
【机器学习】--关联规则算法从初识到应用
一、前述
关联规则的目的在于在一个数据集中找出项之间的关系,也称之为购物蓝分析 (market basket analysis)。例如,购买鞋的顾客,有10%的可能也会买袜子,60%的买面包的顾客,也会买牛奶。这其中最有名的例子就是"尿布和啤酒"的故事了。
二、相关概念
交易集:包含所有数据的一个数据集合,数据集合中的每条数据都是一笔交易
模式/项集(ItemSet):项组合被成为模式/项集
支持度(Support):一个项集在在整个交易集中出现的次数/出现的频度,比如:Support({A,C})=2表示A和C同时出现的次数是2次
最小支持度:交易次数达到最小支持度的情况下,该项集才会被计算
频繁项集:如果项集的支持度大于等于最小支持度,那么改项集被成为频繁项集,即出现的比较频繁。
置信度(Confidence):关联规则左件和右件同时出现的频繁程度,该值越大,表示同时出现的几率越大。
关联规则:LHS --- RHS(confidence) -----> 如果客户购买了左件(LHS),也可能购买右件(RHS),购买的置信度为confidence
首先我们来看,什么是规则?规则形如"如果…那么…(If…Then…)",前者为条件,后者为结果。例如一个顾客,如果买了可乐,那么他也会购买果汁。
如何来度量一个规则是否够好?有两个量,置信度(Confidence)和支持度(Support)。
假设有如下表的购买记录。
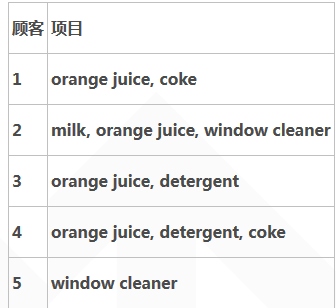
整理后如图:
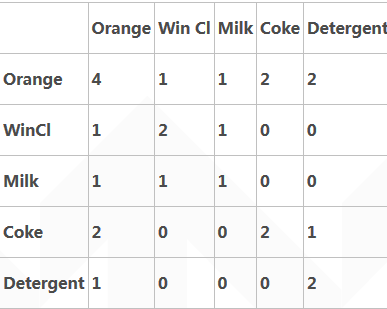
上表中横栏和纵栏的数字表示同时购买这两种商品的交易条数。如购买有Orange的交易数为4,而同时购买Orange和Coke的交易数为2。
置信度表示了这条规则有多大程度上值得可信。设条件的项的集合为A,结果的集合为B。置信度计算在A中,同时也含有B的概率。即Confidence(A==>B)=P(B|A)。例 如计算"如果Orange则Coke"的置信度。由于在含有Orange的4条交易中,仅有2条交易含有Coke.其置信度为0.5。
支持度计算在所有的交易集中,既有A又有B的概率。例如在5条记录中,既有Orange又有Coke的记录有2条。则此条规则的支持度为2/5=0.4。现在这条规则可表述为,如果一个顾客购买了Orange,则有50%的可能购买Coke。而这样的情况(即买了Orange会再买Coke)会有40%的可能发生。支持度是针对项集来说的,因此可以定义一个最小支持度,而只保留满足最小支持度的项集。
关联规则要求项集必须满足的最小支持阈值,称为项集的最小支持度(Minimum Support),记为supmin。支持度大于或等于supmin的项集称为频繁项集,简称频繁集,反之则称为非频繁集。通常k-项集如果满足supmin,称为k-频繁集,记作Lk。关联规则的最小置信度(Minimum Confidence)记为confmin,它表示关联规则需要满足的最低可靠性。
三、Apriori算法
1、原理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号