
【机器学习】--决策树和随机森林
一、前述
决策树是一种非线性有监督分类模型,随机森林是一种非线性有监督分类模型。线性分类模型比如说逻辑回归,可能会存在不可分问题,但是非线性分类就不存在。
二、具体原理
ID3算法
1、相关术语
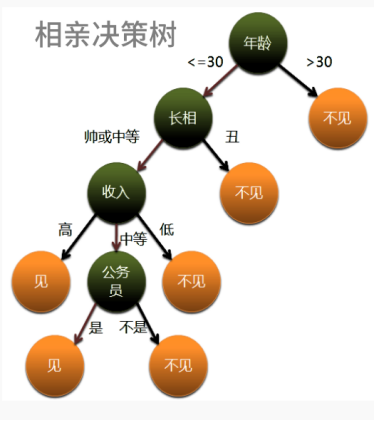
根节点:最顶层的分类条件
叶节点:代表每一个类别号
中间节点:中间分类条件
分枝:代表每一个条件的输出
二叉树:每一个节点上有两个分枝
多叉树:每一个节点上至少有两个分枝
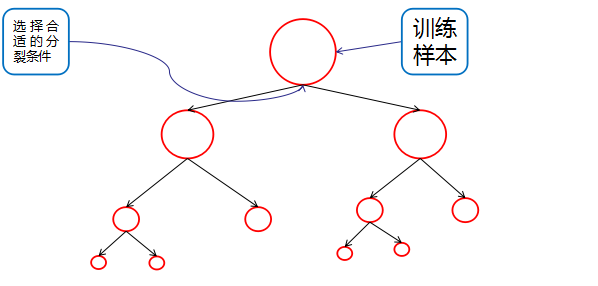
2、决策树的生成:
数据不断分裂的递归过程,每一次分裂,尽可能让类别一样的数据在树的一边,当树的叶子节点的数据都是一类的时候,则停止分类。(if else 语句)
3、如何衡量纯粹度
举例:
箱子1:100个红球
箱子2:50个红球 50个黑球
箱子3:10个红球 30个蓝球 60绿球
箱子4:各个颜色均10个球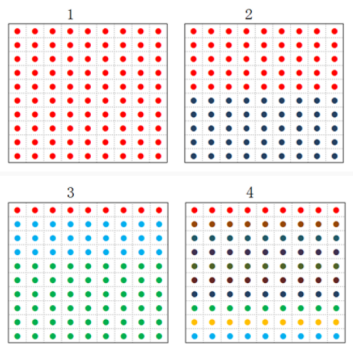
凭人的直觉感受,箱子1是最纯粹的,箱子4是最混乱的,如何把人的直觉感受进行量化呢?
将这种纯粹度用数据进行量化,计算机才能读懂
举例:
度量信息混乱程度指标:
熵的介绍:

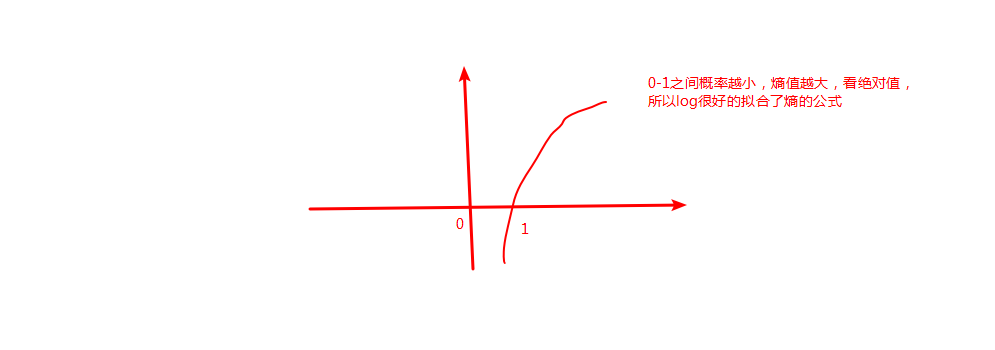
熵公式举例:
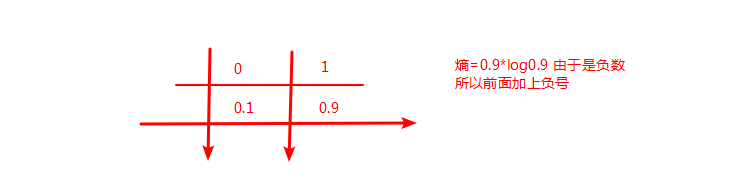
熵代表不确定性,不确定性越大,熵越大。代表内部的混乱程度。
比如两个集合 A有5个类别 每个类别2个值 则每个概率是0.2
比如B有两个类别,每个类别5个 ,则每个概率是0.5
显然0.5大于0.2所以熵大,混乱程度比较大。
信息熵H(X):信息熵是香农在1948年提出来量化信息的信息量的。熵的定义如下
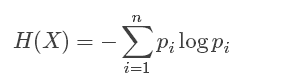
n代表种类,每一个类别中,p1代表某个种类的概率*log当前种类的概率,然后将各个类别计算结果累加。
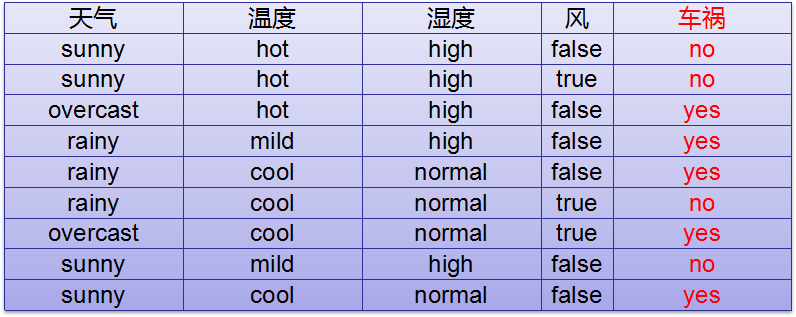
以上例子车祸的信息熵是-(4/9log4/9+5/9log5/9)
条件熵:H(X,Y)类似于条件概率,在知道X的情况下,Y的不确定性
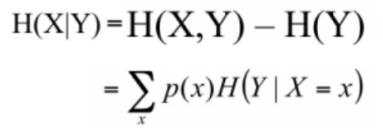
以上例子在知道温度的情况下,求车祸的概率。
hot 是3个,其中两个没有车祸,一个车祸,则3/9(2/3log2/3+1/3log1/3)。
mild是2个,其中一个车祸,一个没有车祸,则2/9(1/2log1/2+1/2log1/2)
cool是4个,其中三个车祸,一个没有车祸,则4/9(3/4log3/4+1/4log1/4)。
以上相加即为已知温度的情况下,车祸的条件熵。
信息增益:代表的熵的变化程度
特征Y对训练集D的信息增益g(D,Y)= H(X) - H(X,Y)
以上车祸的信息熵-已知温度的条件熵就是信息增益。
信息增益即是表示特征X使得类Y的不确定性减少的程度。
(分类后的专一性,希望分类后的结果是同类在一起)
信息增益越大,熵的变化程度越大,分的越干脆,越彻底。不确定性越小。
在构建决策树的时候就是选择信息增益最大的属性作为分裂条件(ID3),使得在每个非叶子节点上进行测试时,都能获得最大的类别分类增益,使分类后数据集的熵最小,这样的处理方法使得树的平均深度较小,从而有效提高了分类效率。
C4.5算法:有时候给个特征,它分的特别多,但是完全分对了,比如训练集里面的编号
信息增益特别大,都甚至等于根节点了,那肯定是不合适的
问题在于行编号的分类数目太多了,分类太多意味着这个特征本身的熵大,大到都快是整个H(X)了
为了避免这种现象的发生,我们不是用信息增益本身,而是用信息增益除以这个特征本身的熵值,看除之后的值有多大!这就是信息增益率,如果用信息增益率就是C4.5
CART算法:
CART使用的是GINI系数,相比ID3和C4.5,CART应用要多一些,既可以用于分类也可以用于回归。
CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出的条件概率分布。
CART算法由以下两步组成:
- 决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;
- 决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时损失函数最小作为剪枝的标准。
CART决策树的生成就是递归地构建二叉决策树的过程。CART决策树既可以用于分类也可以用于回归。本文我们仅讨论用于分类的CART。对分类树而言,CART用Gini系数最小化准则来进行特征选择,生成二叉树。GINI系数其实是用直线段代替曲线段的近似,GINI系数就是熵的一阶近似。
公式如下:
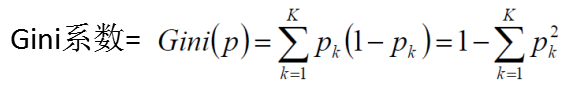
比如两个集合 A有5个类别 每个类别2个值 则每个概率是0.2
比如B有两个类别,每个类别5个 ,则每个概率是0.5
假设C有一个类别,则基尼系数是0 ,类别越多,基尼系数越接近于1,所以
我们希望基尼系数越小越好
CART生成算法如下:
输入:训练数据集停止计算的条件:
输出:CART决策树。
过程:

损失函数:
以上构建好分类树之后,评价函数如下:
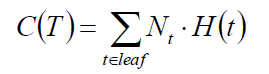
(希望它越小越好,类似损失函数了)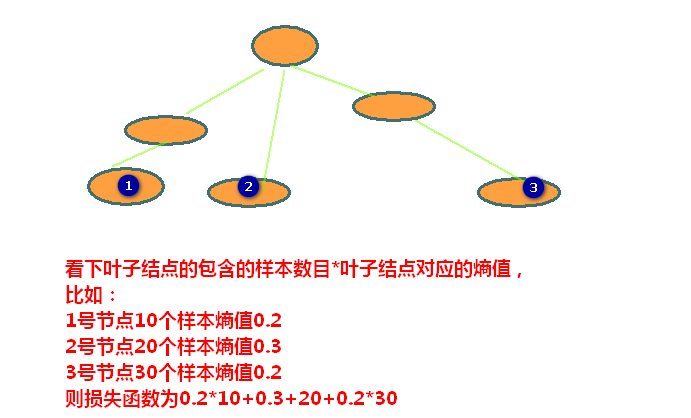
三、解决过拟合问题方法
1、背景
叶子节点的个数作为加权,叶子节点的熵乘以加权的加和就是评价函数这就是损失函数,这个损失函数肯定是越小越好了
如何评价呢?
用训练数据来计算损失函数,决策树不断生长的时候,看看测试数据损失函数是不是变得越低了,
这就是交互式的做调参的工作,因为我们可能需要做一些决策树叶子节点的剪枝,因为并不是树越高越好,因为树如果非常高的话,可能过拟合了。
2、解决过拟合两种方法
剪枝
随机森林
3、解决过拟合方法之剪枝
为什么要剪枝:决策树过拟合风险很大,理论上可以完全分得开数据(想象一下,如果树足够庞大,每个叶子节点不就一个数据了嘛)
剪枝策略:预剪枝,后剪枝
预剪枝:边建立决策树边进行剪枝的操作(更实用)
后剪枝:当建立完决策树后来进行剪枝操作
预剪枝(用的多)
边生成树的时候边剪枝,限制深度,叶子节点个数,叶子节点样本数,信息增益量等树的高度,每个叶节点包含的样本最小个数,每个叶节点分裂的时候包含样本最小的个数,每个叶节点最小的熵值等max_depth min_sample_split min_sample_leaf min_weight_fraction_leaf,max_leaf_nodes max_features,增加min_超参 减小max_超参
后剪枝
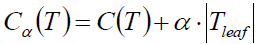
叶子节点个数越多,损失越大
还是生成一颗树后再去剪枝,alpha值给定就行
后剪枝举例:
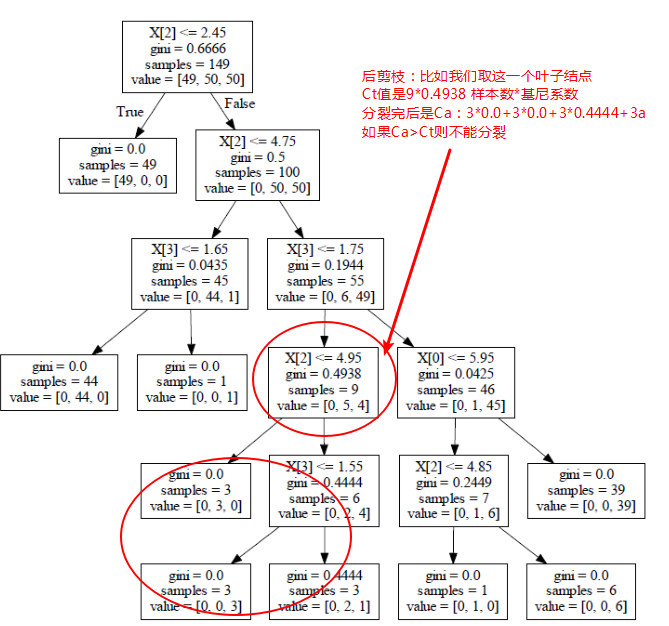
4、解决过拟合方法之随机森林
思想Bagging的策略:
从样本集中重采样(有可能存在重复)选出n个样本在所有属性上,对这n个样本建立分类器(ID3、C4.5、CART、SVM、Logistic回归等)
重复上面两步m次,产生m个分类器将待预测数据放到这m个分类器上,最后根据这m个分类器的投票结果,决定待预测数据属于那一类(即少数服从多数的策略)
在Bagging策略的基础上进行修改后的一种算法
从样本集中用Bootstrap采样选出n个样本;
从所有属性中随机选择K个属性,选择出最佳分割属性作为节点创建决策树;
重复以上两步m次,即建立m棵CART决策树;
这m个CART形成随机森林(样本随机,属性随机),通过投票表决结果决定数据属于那一类。
当数据集很大的时候,我们随机选取数据集的一部分,生成一棵树,重复上述过程,我们可以生成一堆形态各异的树,这些树放在一起就叫森林。
随机森林之所以随机是因为两方面:样本随机+属性随机
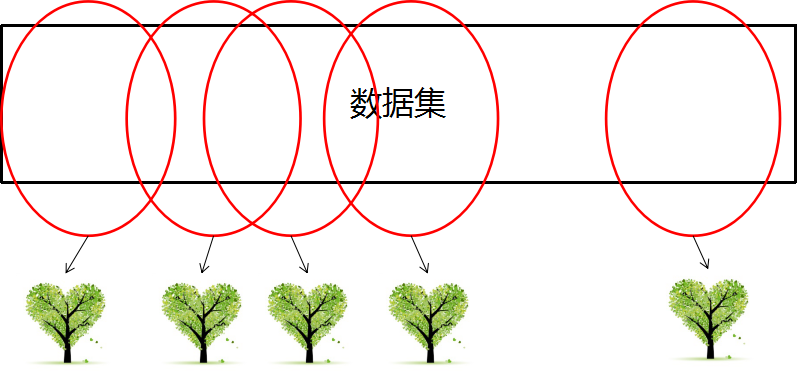
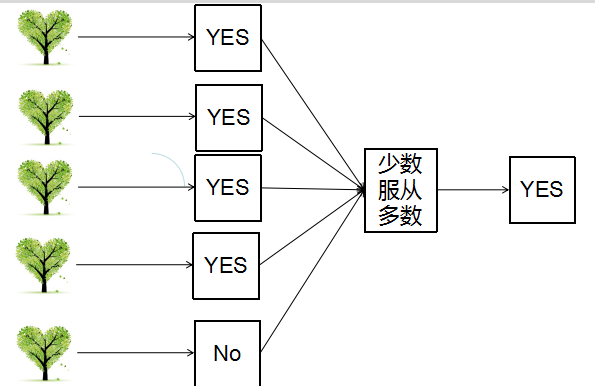
选取过程:
取某些特征的所有行作为每一个树的输入数据。
然后把测试数据带入到每一个数中计算结果,少数服从多数,即可求出最终分类。
随机森林的思考:
在随机森林的构建过程中,由于各棵树之间是没有关系的,相对独立的;在构建
的过程中,构建第m棵子树的时候,不会考虑前面的m-1棵树。因此引出提升的算法,对分错的样本加权。
提升是一种机器学习技术,可以用于回归和分类的问题,它每一步产生弱预测模型(如决策树),并加权累加到总模型中;如果每一步的弱预测模型的生成都是依
据损失函数的梯度方式的,那么就称为梯度提升(Gradient boosting)提升技术的意义:如果一个问题存在弱预测模型,那么可以通过提升技术的办法得到一个强预测模型。
四、代码
决策树:
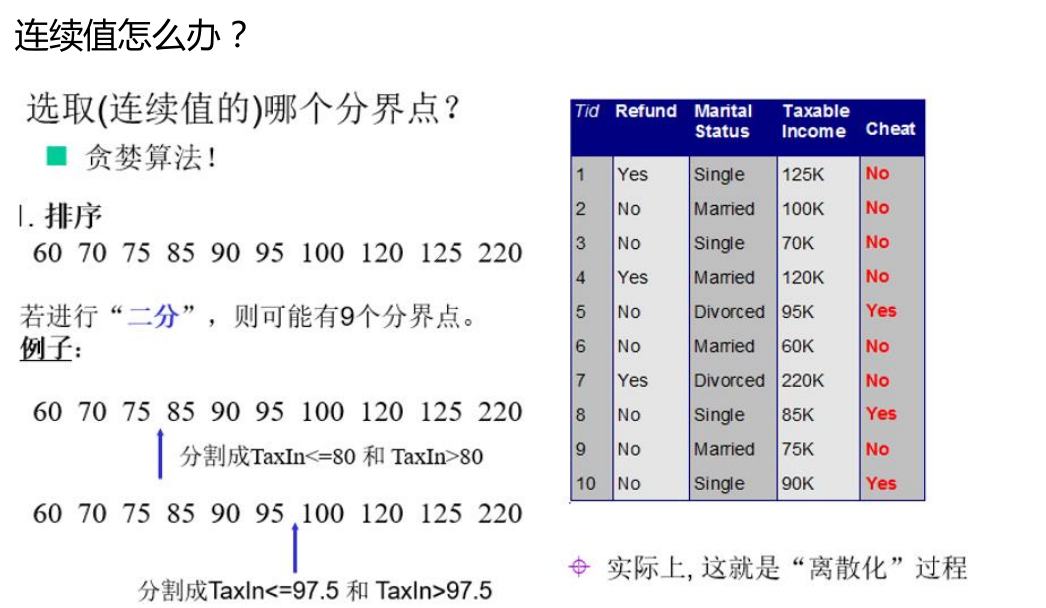
决策树的训练集必须离散化,因为如果不离散化的话,分类节点很多。
package com.bjsxt.rf
import org.apache.spark.mllib.tree.DecisionTree
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.{SparkContext, SparkConf}
object ClassificationDecisionTree {
val conf = new SparkConf()
conf.setAppName("analysItem")
conf.setMaster("local[3]")
val sc = new SparkContext(conf)
def main(args: Array[String]): Unit = {
val data = MLUtils.loadLibSVMFile(sc, "汽车数据样本.txt")
// Split the data into training and test sets (30% held out for testing)
val splits = data.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
//指明类别
val numClasses=2
//指定离散变量,未指明的都当作连续变量处理
//1,2,3,4维度进来就变成了0,1,2,3
//这里天气维度有3类,但是要指明4,这里是个坑,后面以此类推
val categoricalFeaturesInfo=Map[Int,Int](0->4,1->4,2->3,3->3)
//设定评判标准
val impurity="entropy"
//树的最大深度,太深运算量大也没有必要 剪枝 防止模型的过拟合!!!
val maxDepth=3
//设置离散化程度,连续数据需要离散化,分成32个区间,默认其实就是32,分割的区间保证数量差不多 这里可以实现把数据分到0-31这些数中去 这个参数也可以进行剪枝
val maxBins=32
//生成模型
val model =DecisionTree.trainClassifier(trainingData,numClasses,categoricalFeaturesInfo,impurity,maxDepth,maxBins)
//测试
val labelAndPreds = testData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val testErr = labelAndPreds.filter(r => r._1 != r._2).count().toDouble / testData.count()//错误率的统计
println("Test Error = " + testErr)
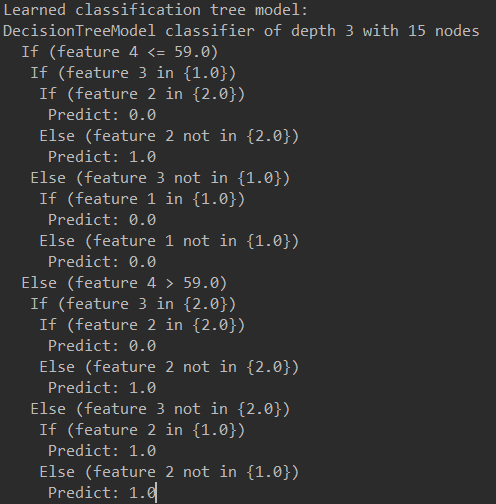
println("Learned classification tree model:\n" + model.toDebugString)
}
}
样本数据:
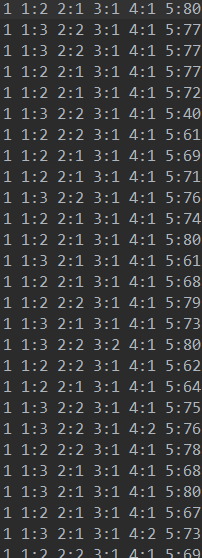
将第5列数据离散化。
结果:

深度为3一共15个节点。
随机森林:
package com.bjsxt.rf
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.mllib.tree.RandomForest
object ClassificationRandomForest {
val conf = new SparkConf()
conf.setAppName("analysItem")
conf.setMaster("local[3]")
val sc = new SparkContext(conf)
def main(args: Array[String]): Unit = {
//读取数据
val data = MLUtils.loadLibSVMFile(sc,"汽车数据样本.txt")
//将样本按7:3的比例分成
val splits = data.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
//分类数
val numClasses = 2
// categoricalFeaturesInfo 为空,意味着所有的特征为连续型变量
val categoricalFeaturesInfo =Map[Int, Int](0->4,1->4,2->3,3->3)
//树的个数
val numTrees = 3
//特征子集采样策略,auto 表示算法自主选取
//"auto"根据特征数量在4个中进行选择
// 1,all 全部特征 2,sqrt 把特征数量开根号后随机选择的 3,log2 取对数个 4,onethird 三分之一
val featureSubsetStrategy = "auto"
//纯度计算
val impurity = "entropy"
//树的最大层次
val maxDepth = 3
//特征最大装箱数,即连续数据离散化的区间
val maxBins = 32
//训练随机森林分类器,trainClassifier 返回的是 RandomForestModel 对象
val model = RandomForest.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo,
numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins)
//打印模型
println(model.toDebugString)
//保存模型
//model.save(sc,"汽车保险")
//在测试集上进行测试
val count = testData.map { point =>
val prediction = model.predict(point.features)
// Math.abs(prediction-point.label)
(prediction,point.label)
}.filter(r => r._1 != r._2).count()
println("Test Error = " + count.toDouble/testData.count().toDouble)
}
}
结果:
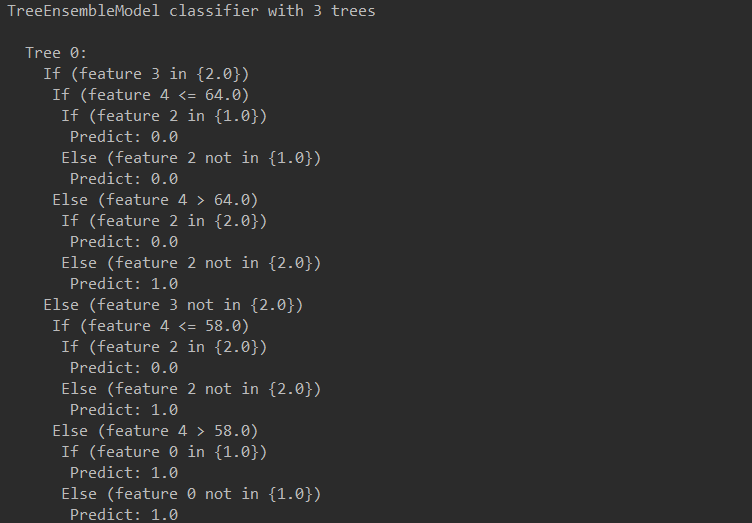

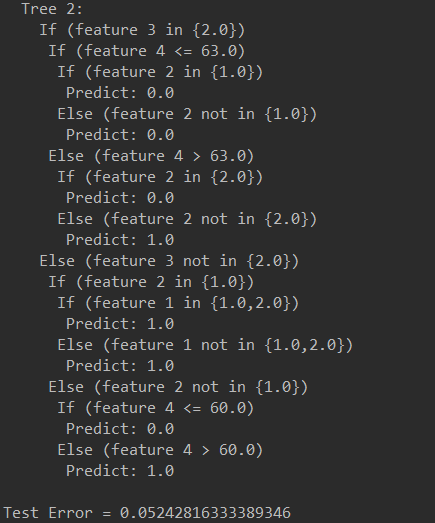
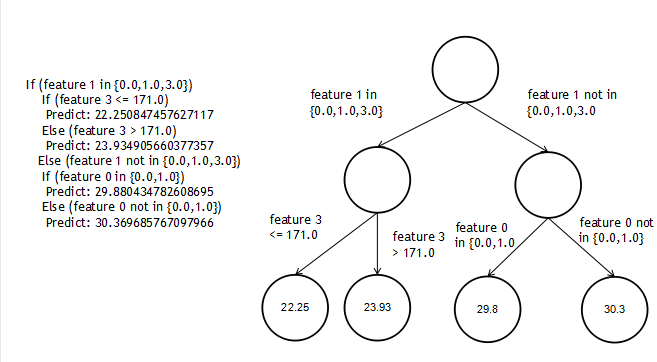
根据DEBUGTREE画图举例:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号