
第一次个人作业
| 这个作业属于哪个课程 | 班级的链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求的链接 |
| 这个作业的目标 | 实现论文查重算法,并对代码进行性能分析、单元测试,使用PSP表 |
GitHub链接
一、PSP表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 20 |
| Estimate | 估计这个任务需要多少时间 | 15 | 30 |
| Development | 开发 | 150 | 210 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 50 |
| Design Spec | 生成设计文档 | 60 | 80 |
| Design Review | 设计复审 | 20 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| Design | 具体设计 | 25 | 20 |
| Coding | 具体编码 | 30 | 150 |
| Code Review | 代码复审 | 30 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 40 | 60 |
| Test Repor | 测试报告 | 20 | 25 |
| Size Measurement | 计算工作量 | 15 | 15 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 40 | 40 |
| 合计 | 535 | 835 |
二、计算模块的设计与实现
1、总体设计
目录表:
流程图
2、详细设计
DataPreprocessing类
read_file 函数:读取文件数据,发生异常则抛出对应的异常并返回-1。
preprocess_data 函数:对数据进行全角转半角、去除HTML标签、保留中文字符操作,发生异常则抛出对应的异常并返回空字符.
to_dbc 函数:对数据进行全角转半角操作。
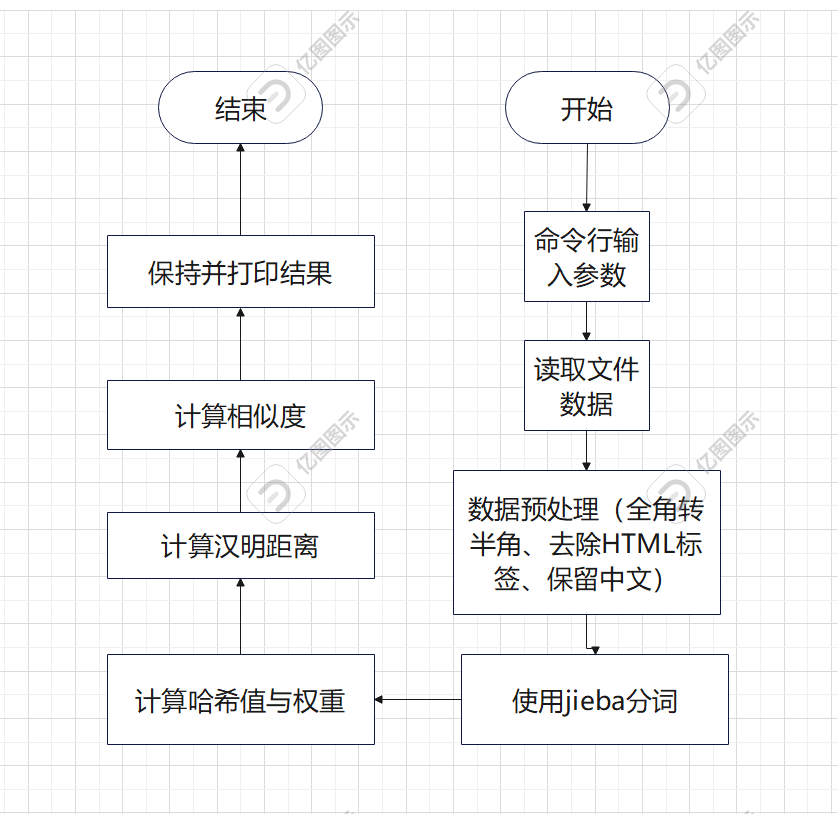
SimHashService类
get函数:使用jieba分词,过滤标点符号或无效字符,过滤标点符号或无效字符,按权重逐位计算哈希值,将统计结果转换成0/1字符串。
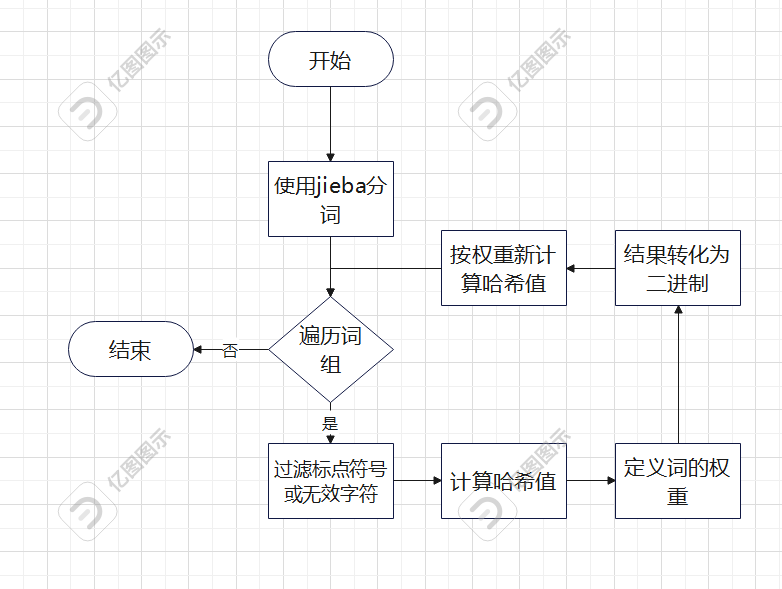
关键算法流程图!
get_word_hash 函数:计算词哈希值。
get_word_weight 函数:定义词的权重。
hamming_distance 函数:计算汉明距离。
SimilarityChecker类:
check_similarity函数:计算两篇文章的SimHash后计算汉明距离,根据汉明距离计算论文相似度。
三、性能改进
1、性能分析
这里我使用PyCharm自带的Profile功能进行性能分析。
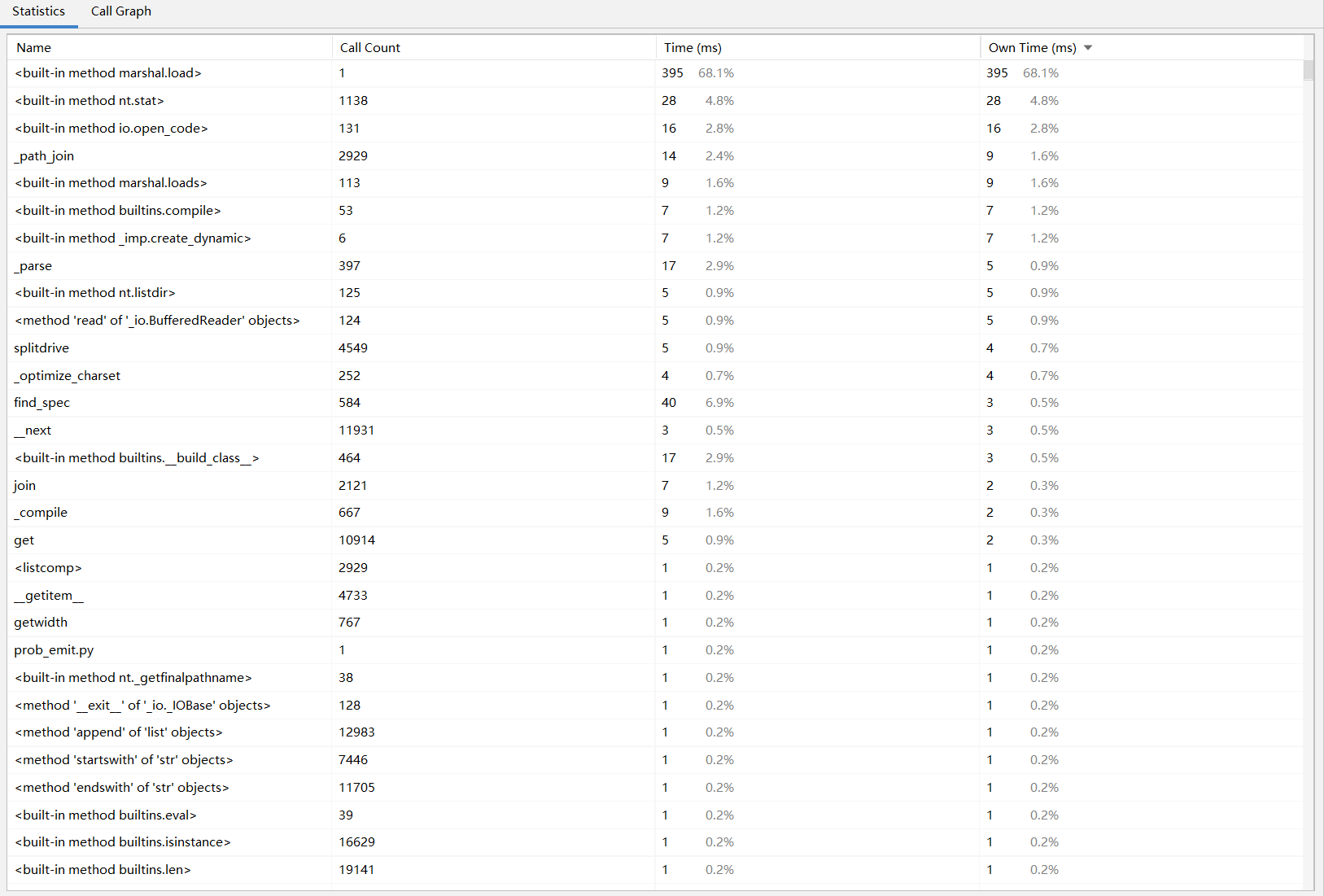
从上图中可以看到耗时最长的是只执行一次的Python内置的
2、改进思路
可以增加对生成processed_text1, processed_text2的合理性判断,减少 checker.check_similarity方法的调用,因为get方法耗时很长,而get方法就是checker.check_similarity调用的。
四、单元测试
思路:
使用unittest库,共设计25个函数(分4个类TestDataPreprocessing、TestGetWordHash、TestHammingDistance、TestSimilarityChecker)来对6个关键函数进行测试,尽可能地对我所构建的论文查重算法进行测试,保证代码健壮性、准确性、通用性。
数据预处理单元测试代码展示:
def test_preprocess_data_with_valid_input(self):
"""测试 preprocess_data 方法,包含 HTML 标签和非中文字符"""
text_content = "<html>这是一个测试! 123</html>"
result = DataPreprocessing.preprocess_data(text_content)
expected = "这是一个测试" # 去除HTML标签和非中文字符后的结果
self.assertEqual(result, expected)
def test_preprocess_data_with_empty_input(self):
"""测试 preprocess_data 方法,输入为空字符串"""
text_content = ""
result = DataPreprocessing.preprocess_data(text_content)
self.assertEqual(result, "")
def test_preprocess_data_with_all_non_chinese(self):
"""测试 preprocess_data 方法,输入不包含中文字符"""
text_content = "Hello, World! 123"
result = DataPreprocessing.preprocess_data(text_content)
self.assertEqual(result, "")
def test_to_dbc_with_full_width_characters(self):
"""测试 to_dbc 方法,将全角字符转换为半角"""
input_str = "ABCabc123!@#"
result = DataPreprocessing.to_dbc(input_str)
expected = "ABCabc123!@#"
self.assertEqual(result, expected)
def test_to_dbc_with_mixed_characters(self):
"""测试 to_dbc 方法,混合全角和半角字符"""
input_str = "Hello ABC"
result = DataPreprocessing.to_dbc(input_str)
expected = "Hello ABC"
self.assertEqual(result, expected)
def test_read_file(self):
"""测试 read_file 方法"""
file_path = "D:\PyCharmCode\SimHash\\3122004446\DataSet\测试用例\DataPreprocessing.txt"
result = DataPreprocessing.read_file(file_path)
expected = "《软 件工程!,123"
self.assertEqual(result, expected)
def test_read_file_err1(self):
"""测试 read_file 方法 不存在次文件"""
file_path = "D:\PyCharmCode\SimHash\\3122004446\DataSet\测试用例\DataPreprocessing_err1.txt"
result = DataPreprocessing.read_file(file_path)
# print(f"result7:{result}")
expected = -1
self.assertEqual(result, expected)
单元测试结果截图
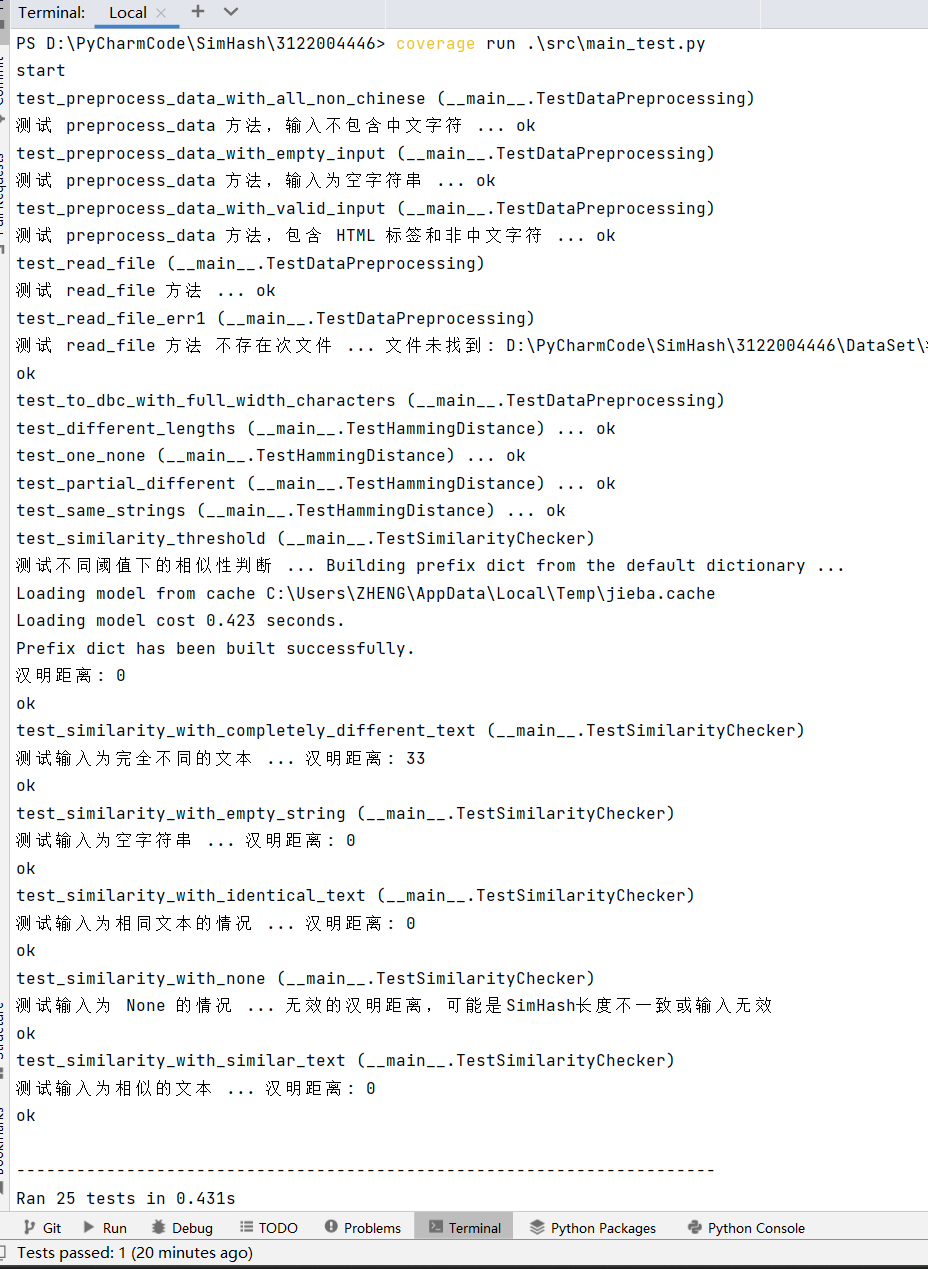
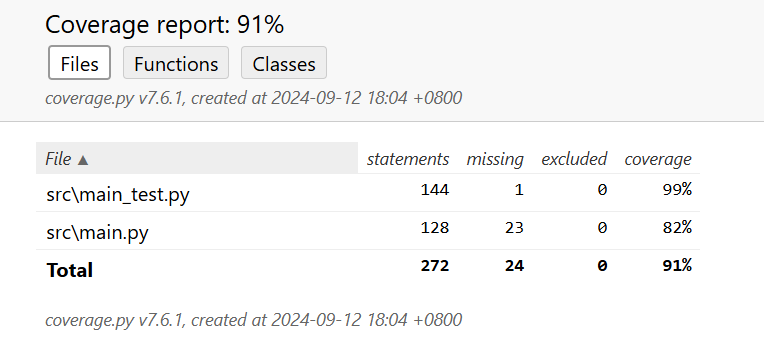
覆盖率
这里使用Python的coverage库进行分析。
代码文件覆盖率截图:
各个函数覆盖率截图:
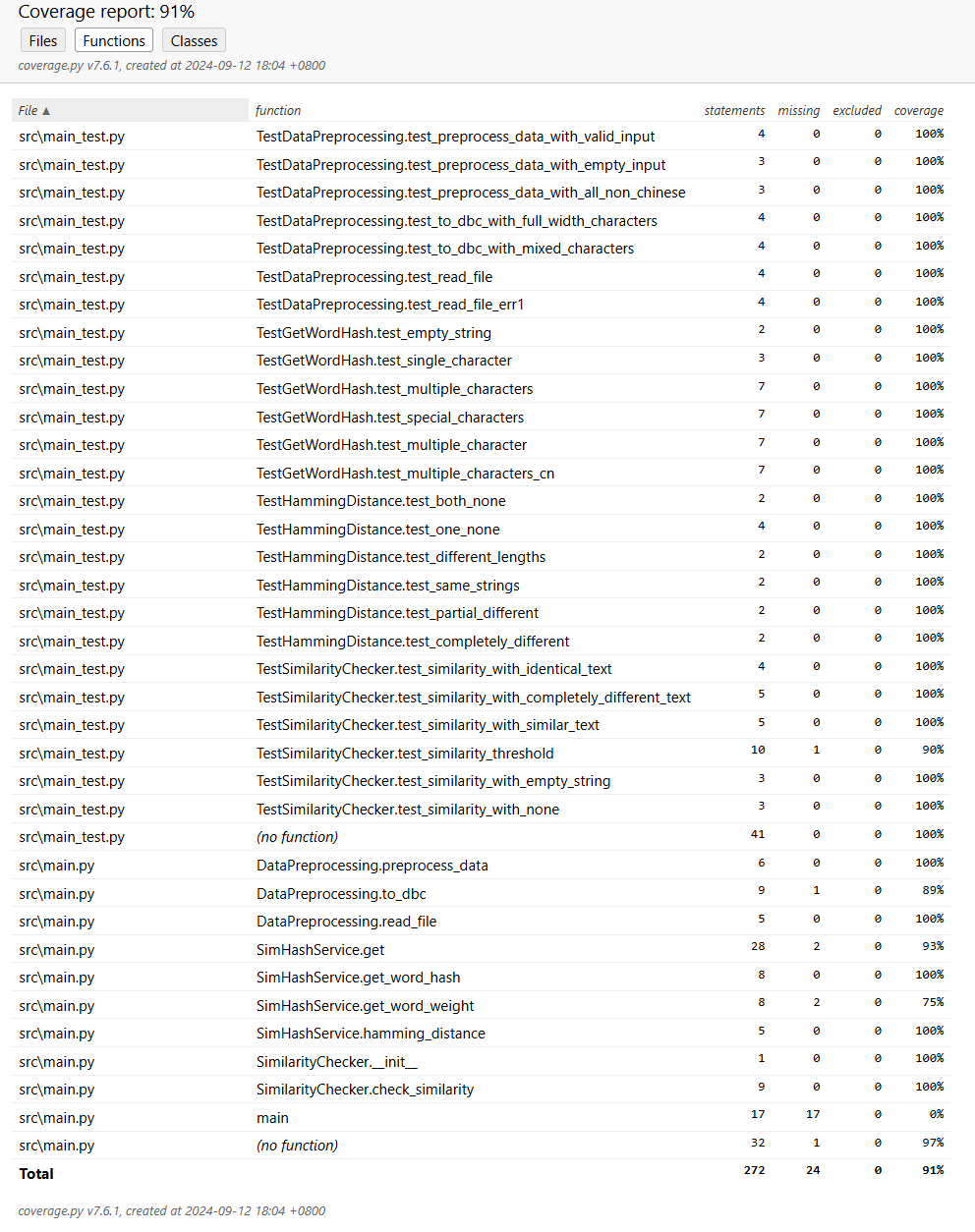
各个类覆盖率截图:

五、异常处理
这里我用unittest库对各个单元进行异常测试。
异常一
read_file函数异常:在读取文件时找不到目标文件或无法正常打开目标文件时,异常时抛出异常提示并返回-1。
测试样例:
def test_read_file_err1(self):
"""测试 read_file 方法 不存在次文件"""
file_path = "D:\PyCharmCode\SimHash\\3122004446\DataSet\测试用例\DataPreprocessing_err1.txt"
result = DataPreprocessing.read_file(file_path)
# print(f"result7:{result}")
expected = -1
self.assertEqual(result, expected)
结果截图:

异常二
to_dbc函数异常:当非字符串输入、非常大的字符串、特殊字符、外部环境问题、编码问题时,异常时抛出异常提示并返回输入内容。
测试样例:
class TestDataPreprocessing(unittest.TestCase):
def test_to_dbc_with_mixed_characters(self):
"""测试 to_dbc 方法,混合全角和半角字符"""
input_str = None
result = DataPreprocessing.to_dbc(input_str)
expected = None
self.assertEqual(result, expected)
结果截图:
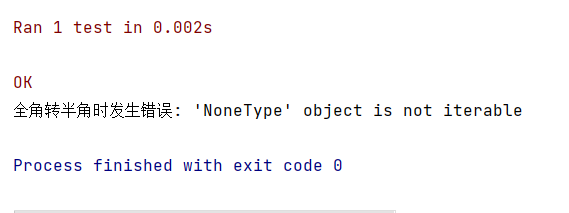
异常三
get_word_hash函数:当非字符串输入、索引越界、特殊字符、编码问题、极端长度的字符串时,异常时抛出异常提示并返回0。
测试样例:
class TestGetWordHash(unittest.TestCase):
def test_empty_string(self):
# 测试空字符串输入
result = SimHashService.get_word_hash(123)
self.assertEqual(result, BIGINT_0)
结果截图:

异常四
get_word_weight函数:当输入数字时,抛出异常提示并返回0。
测试样例:
class TestGetWordHash(unittest.TestCase):
def test_empty_string(self):
# 测试空字符串输入
result = SimHashService.get_word_weight(111)
self.assertEqual(result, BIGINT_0)
结果截图:

异常五
hamming_distance函数:当输入的值不是字符串时,抛出异常提示并返回-1。
测试样例:
class TestHammingDistance(unittest.TestCase):
def test_both_none(self):
# 测试两个输入都为 None
result = SimHashService.hamming_distance("110", 110)
self.assertEqual(result, -1)
结果截图:

六、总结
这是我第一次按照PSP表写的程序,从前期的预估安排时间、学习新知识,到期间的编写程序,再到后期测试程序与撰写报告。体会到了PSP表对于提高软件开发人员个人生产效率和产品质量的作用,也接触到了unittest、coverage、profile等测试分析的方法,是一次难忘的编程经理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号