
Reinforcement Learning Charpter 3
本文参考《Reinforcement Learning:An Introduction(2nd Edition)》Sutton
有限MDP
有限MDP在RL中一般就是指如下图的交互式学习框架。(为了方便起见,把它当成离散化的过程)
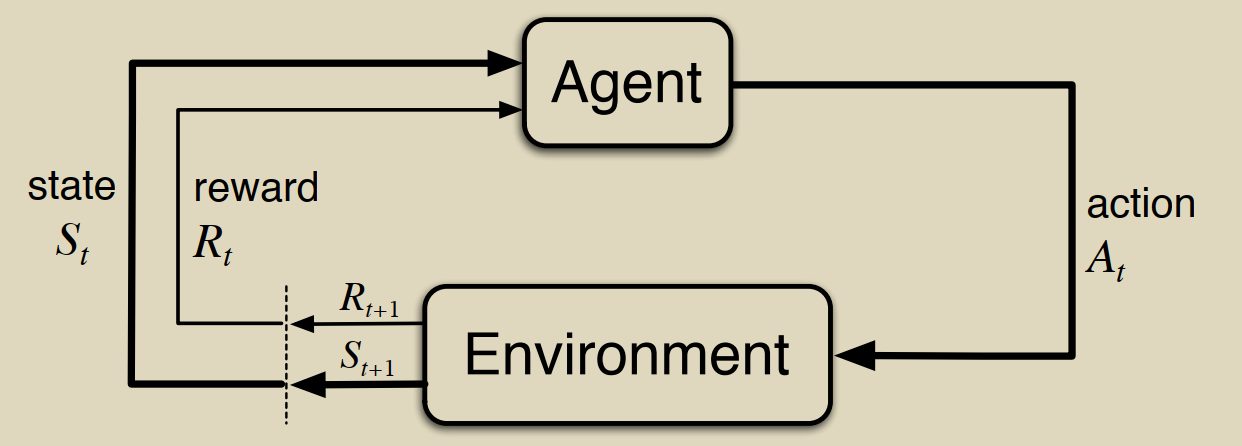
其“有限”的特点表现在:state、reward、action三者只有有限个元素
其markov性体现在:
![]()
所以在这种情况下state,reward是两个具有明确定义的离散概率分布的随机变量,并且对前继状态有依赖性;
由条件概率的性质,不难看出函数p实际上是为state=s,action=a的所有后继状态(包括state与reward)指定了一个概率分布。
值得注意的一点是我们现在讨论的模型是随机的,也就是state,action,reward之间本质上是相互独立的。
对于函数p,我们取适当的定义域可以自然的衍生出一系列的关于环境的信息:
如状态转移概率:
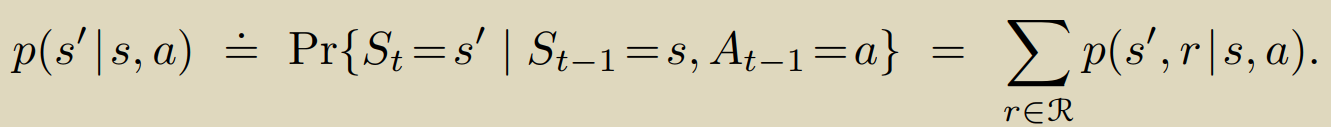
还有很多,不再赘述。
有限MDP作为RL的学习框架之一核心就在于智能体和环境之间三个信号(s,r,a)的来回传递,经过大量实践已证明有限MDP方法的普适性和有效性。
联系我们之前bandit问题的例子,对于有限MDP框架而言,其目标在于最大化 收益和 (决策过程中)的期望值;
所以很重要的一点就是:收益信号r只是目标的一种间接表达,并不一定是目标本身。收益信号强不代表达到RL目标,但是达到RL目标时收益信号一定不弱。
依赖于有限MDP框架,我们可以公式化的描述我们的策略、状态价值,从而评估我们的策略是否足够优秀:
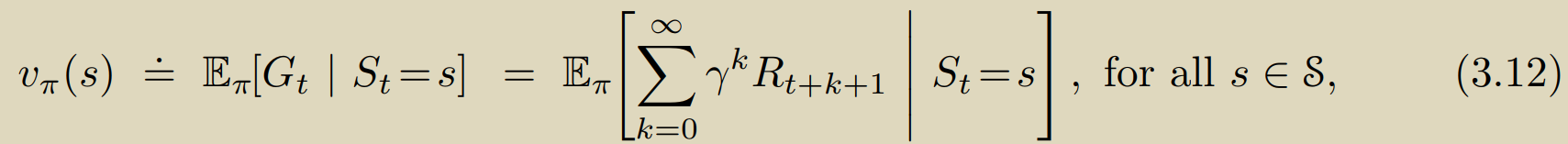
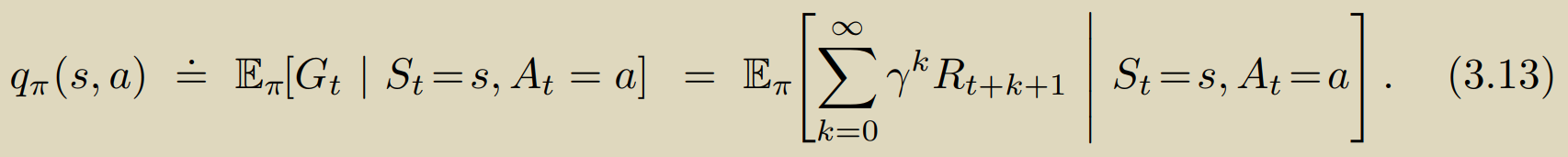
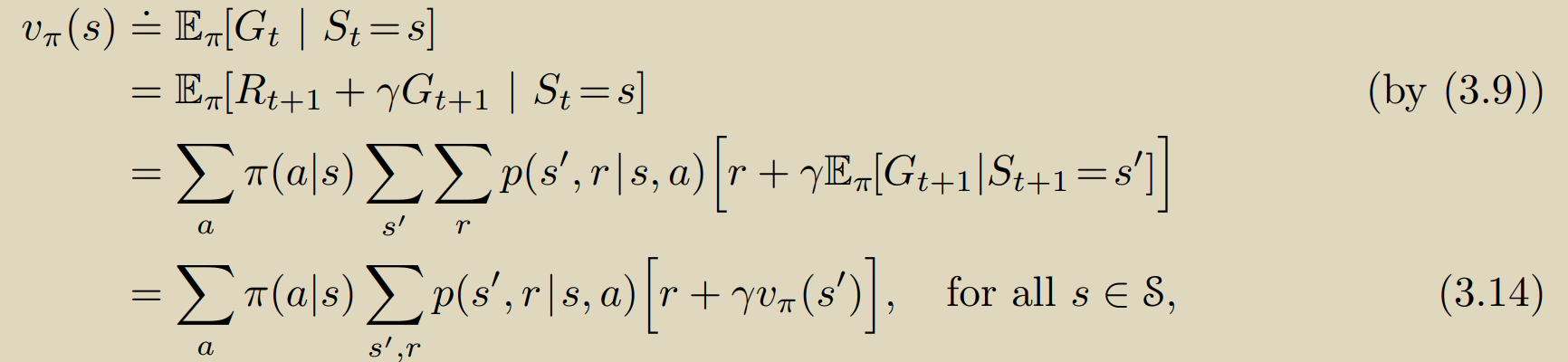
最下的式子即为著名的贝尔曼方程,由于其递归依赖的特性,对于有限MDP过程这个方程组总是有唯一解(保证解一定存在)。
那么比较自然的我们得到了一个新的问题:是否存在一个策略使得在任何状态下状态的价值都大于其他策略下该状态的价值?
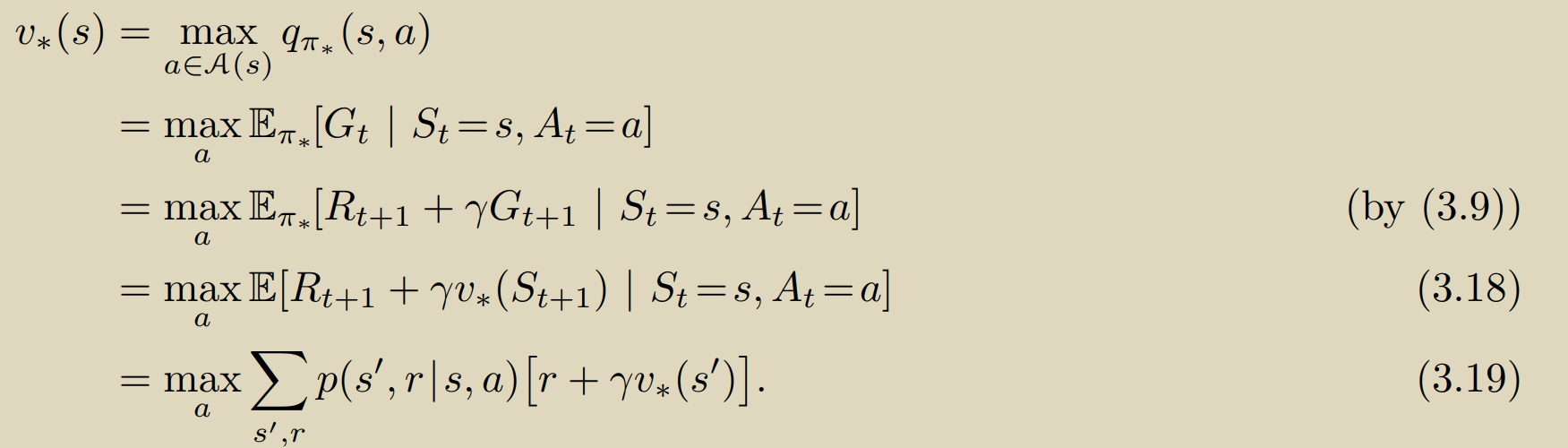
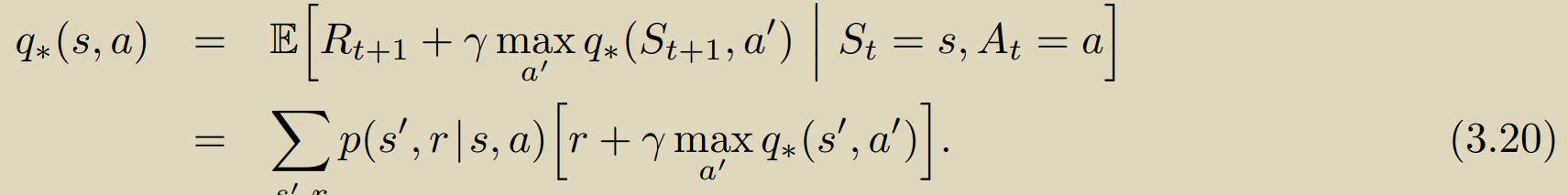
即上述两式代表的 贝尔曼最优方程是否存在解?
从数学上可以证明必然存在最优解,且解唯一:
证明过程可参考:强化学习中无处不在的贝尔曼最优性方程,背后的数学原理为何? - 知乎 (zhihu.com),主要运用到了压缩映射的性质和巴拿赫不动点定理。
然而解存在不代表我们可直接解出,我们希望能够得到最优方程的解,但不同于bellman方程,最优方程显式解法需要足够充足的算力且要对环境有精确完备的建模,所以我们只能尽可能的近似求解。
