AI绘画漫谈——从AI网页生成说起
1. 又说“前端已死”
为什么说“又”呢?因为前两年我在一些博客网站三天两头就能看到这个标题,虽然今年好像换话题了,但感觉前端每年都要死个七八次,当然这里面还是标题党偏多,不过也体现了有一些开发者对自己当前所做的工作内容的忧虑,尤其是这一次冲击的浪潮是来自于 AI 的,经历了两年的火热,我们已经感受到 AI 对行业的影响,今天在这里想借初学 AI 绘画的一些技术总结来探讨 AI 对我们工作产生的影响。
绘画与摄影
回顾 2022 年的 AI 热潮,最先受到冲击的就是绘画行业,现在翻看当时的讨论,有很多人抱持悲观态度,说出了“绘画已死”,但这也不是第一次有人这么说,无独有偶,1839 年法国画家 H·保罗·德拉罗什看到银版摄影摄影法的成品后,留下了一句话:
此时此刻,绘画死了。
摄影在现在的我们看来,与绘画是两个门类,但当时的画家为什么会有如此激动呢?因为当时的欧洲古典绘画,有两个最重要的技巧——结构和透视,而在摄影中只要按下快门就能完美地记录场景和人物,不像画家需要穷极一生去练习这两种技法,而当下的 AI 绘画好像可以只通过几个关键词就能生成以往需要大量练习才能得到的图片,但事实真是如此吗?我们先看下 AI 技术怎么改变前端的。
2. AI 网页开发
我们先跳过设计和框架搭建阶段,最常用的场景是拿到设计图后,将其转化成网页代码,能实现这个步骤的 AI 工具也有不少了,我找了几个稍微有些口碑的试用,尽量选了一些横平竖直的设计图,因为试了一些较复杂的海报,发现效果差很多。
设计图如下:

FrontendAI
生成了两次,结构还算正常,细节不够:
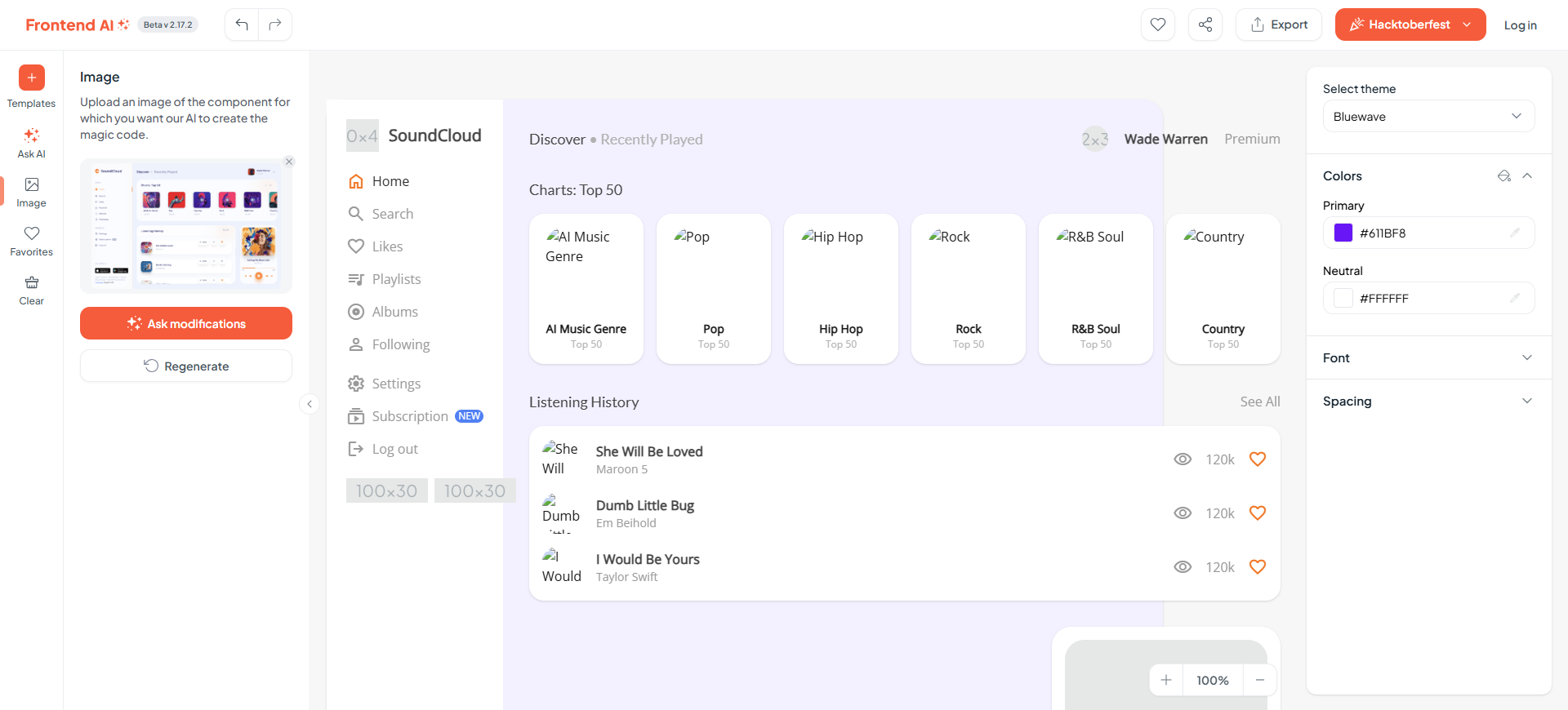
要求将播放器改为浮动的:
代码可以选择不同的框架:
Open UI
只有极简的结构:
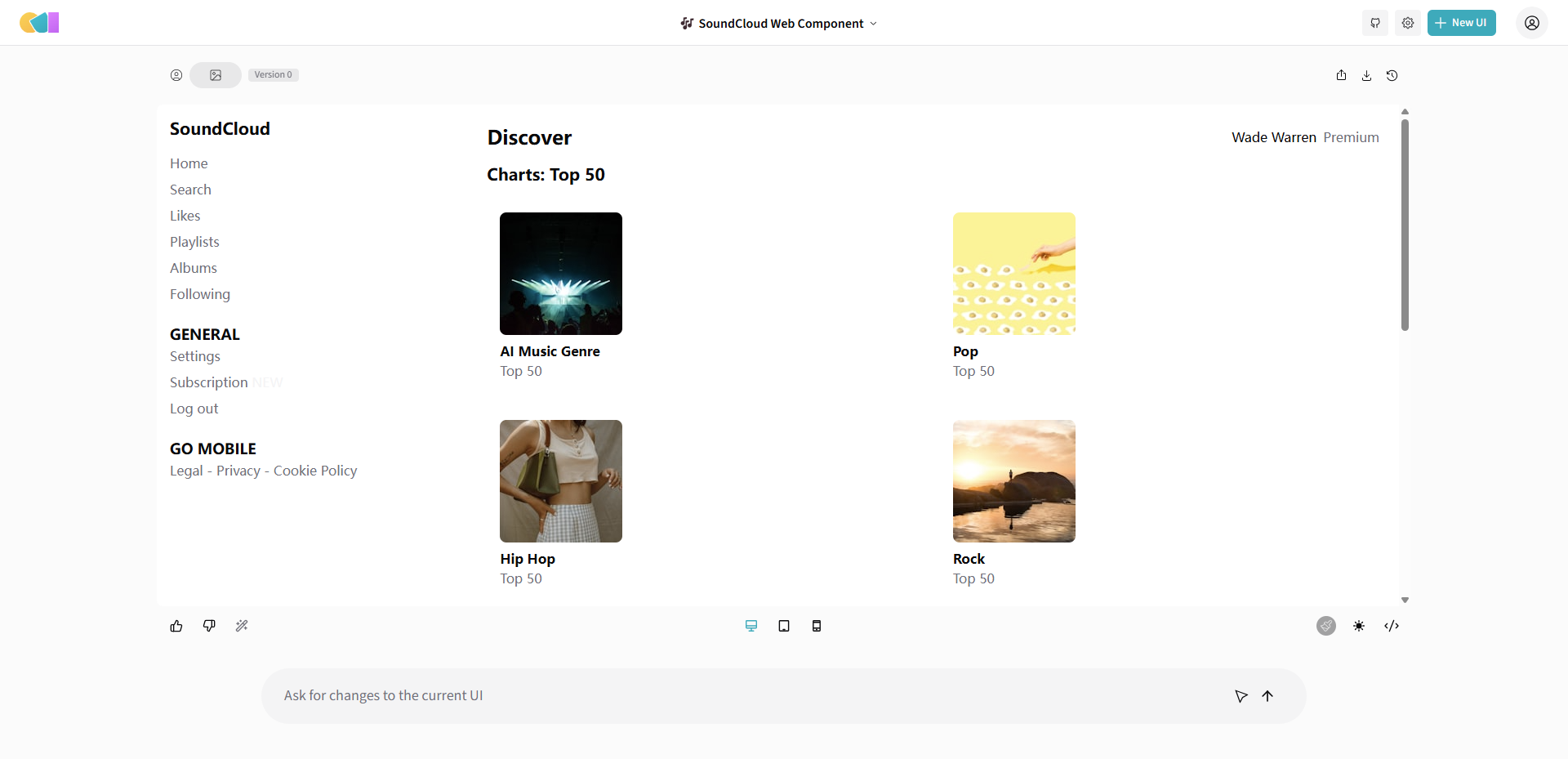
Screenshot to Code
最近没有准备 GPT 的 key,无法试用。
v0
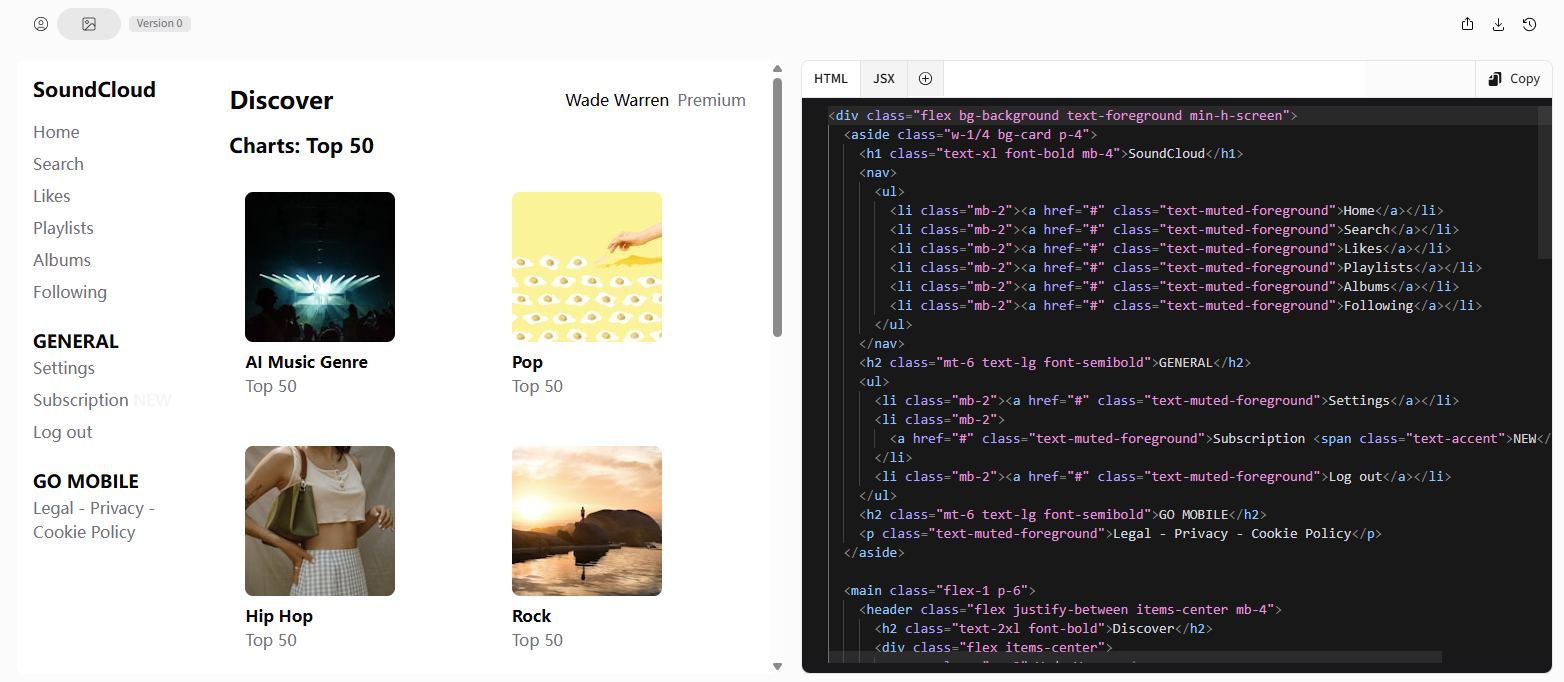
效果比较好的是 Vercel 推出的一款 AI 代码生成工具,可以快速生成前端组件代码。
Vercel 本身也是一个前端部署平台,性质类似 GitHub Pages,这方面也比较有发言权。
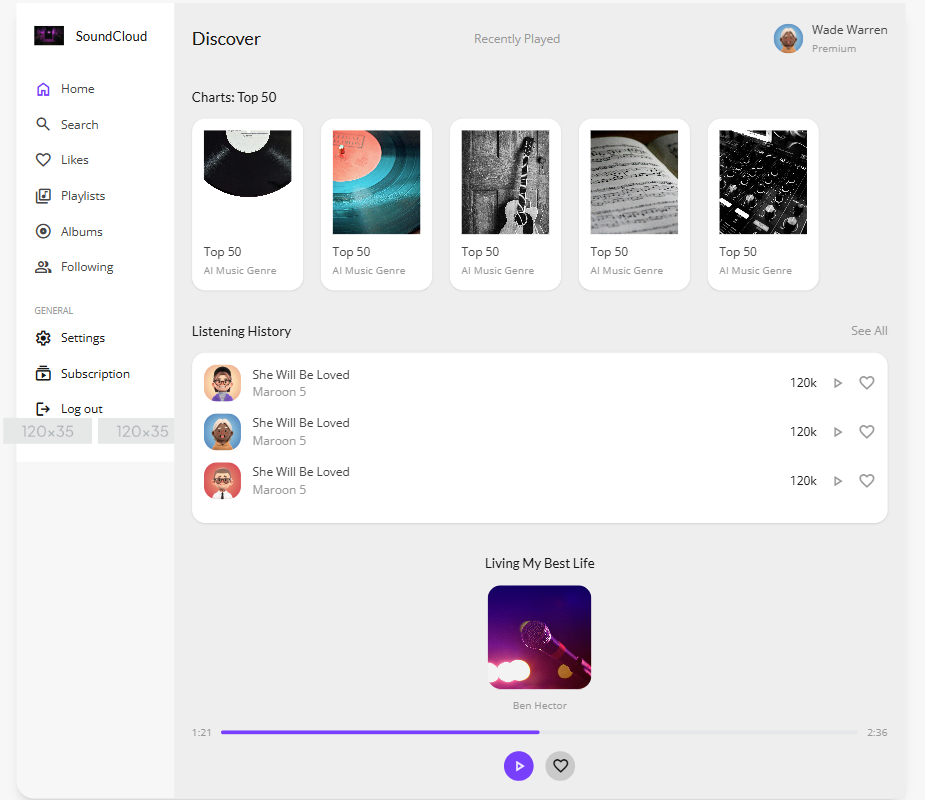
生成的网页截图:
第一次生成的结果来看,只能说样子有了,细节是完全不够的。
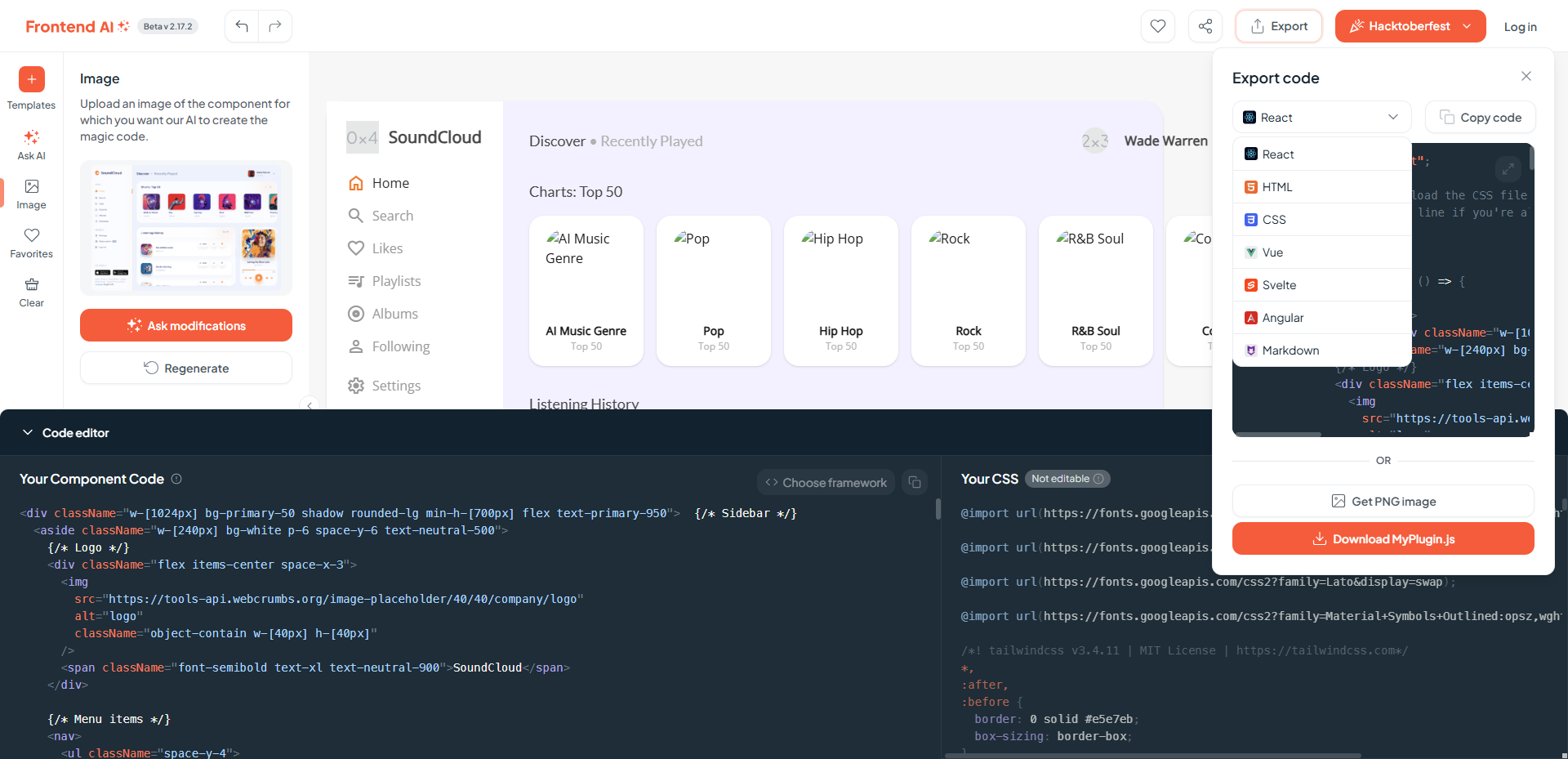
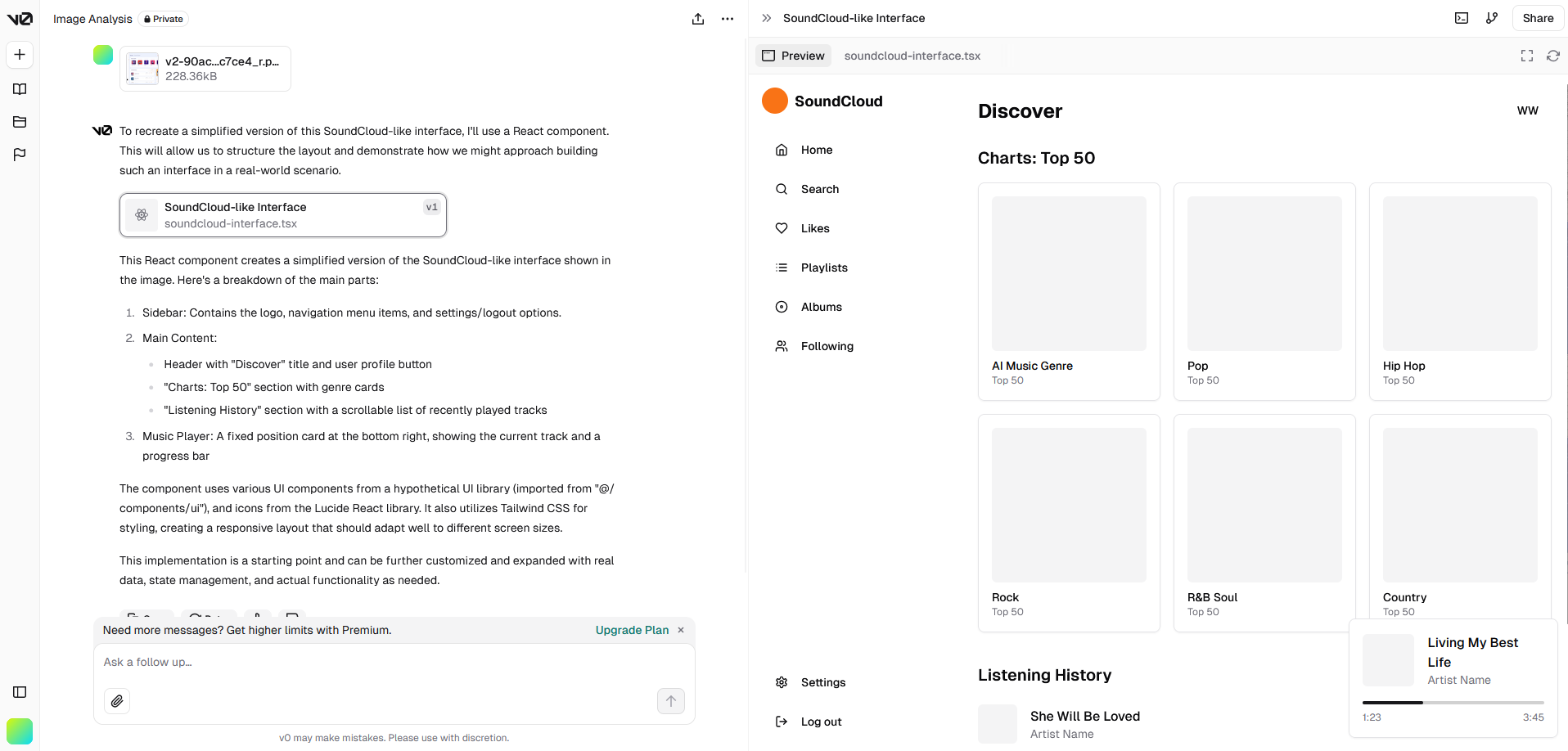
默认生成 React 代码:
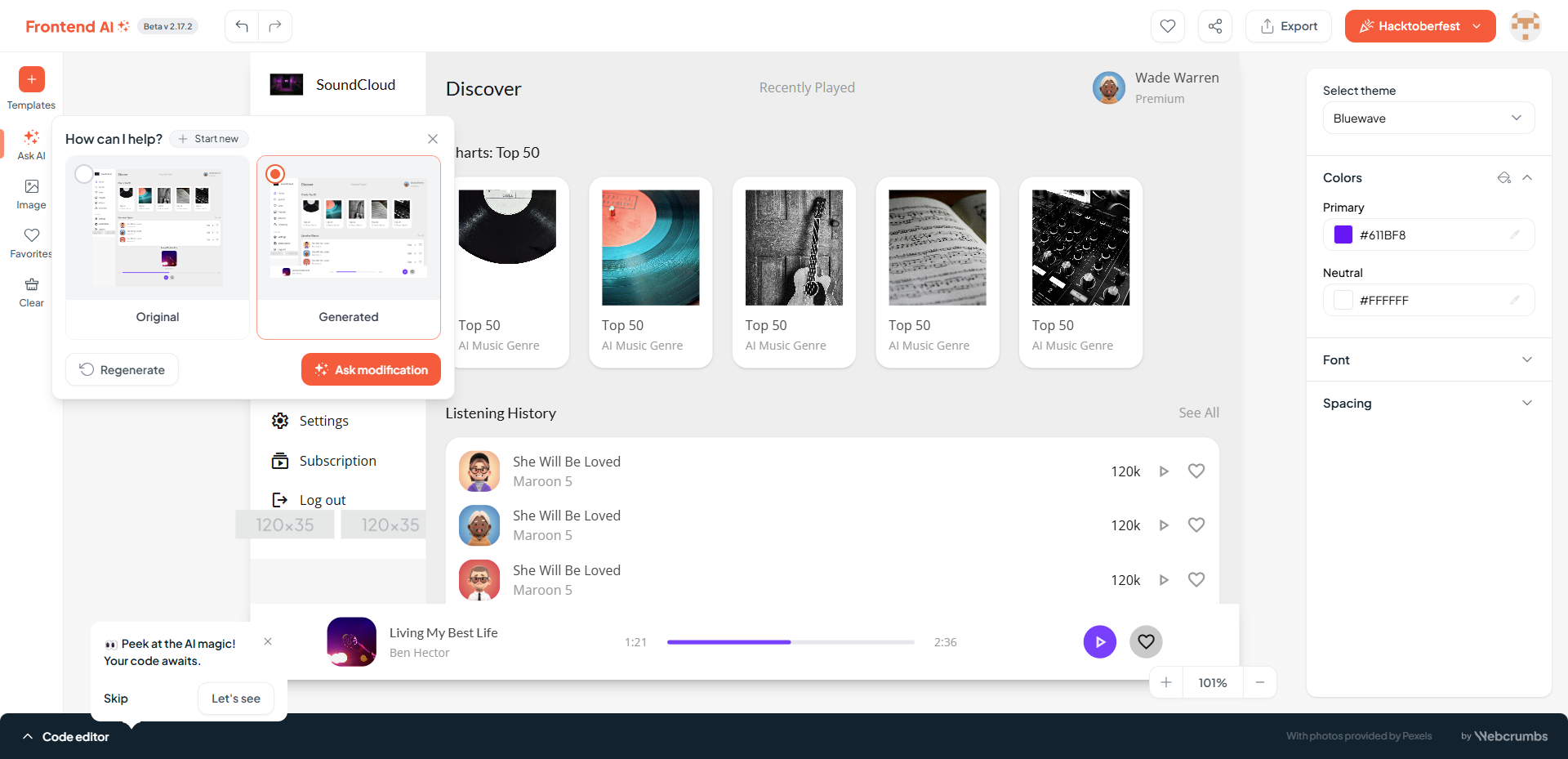
可以用自然语言描述需求并且一步步细化:
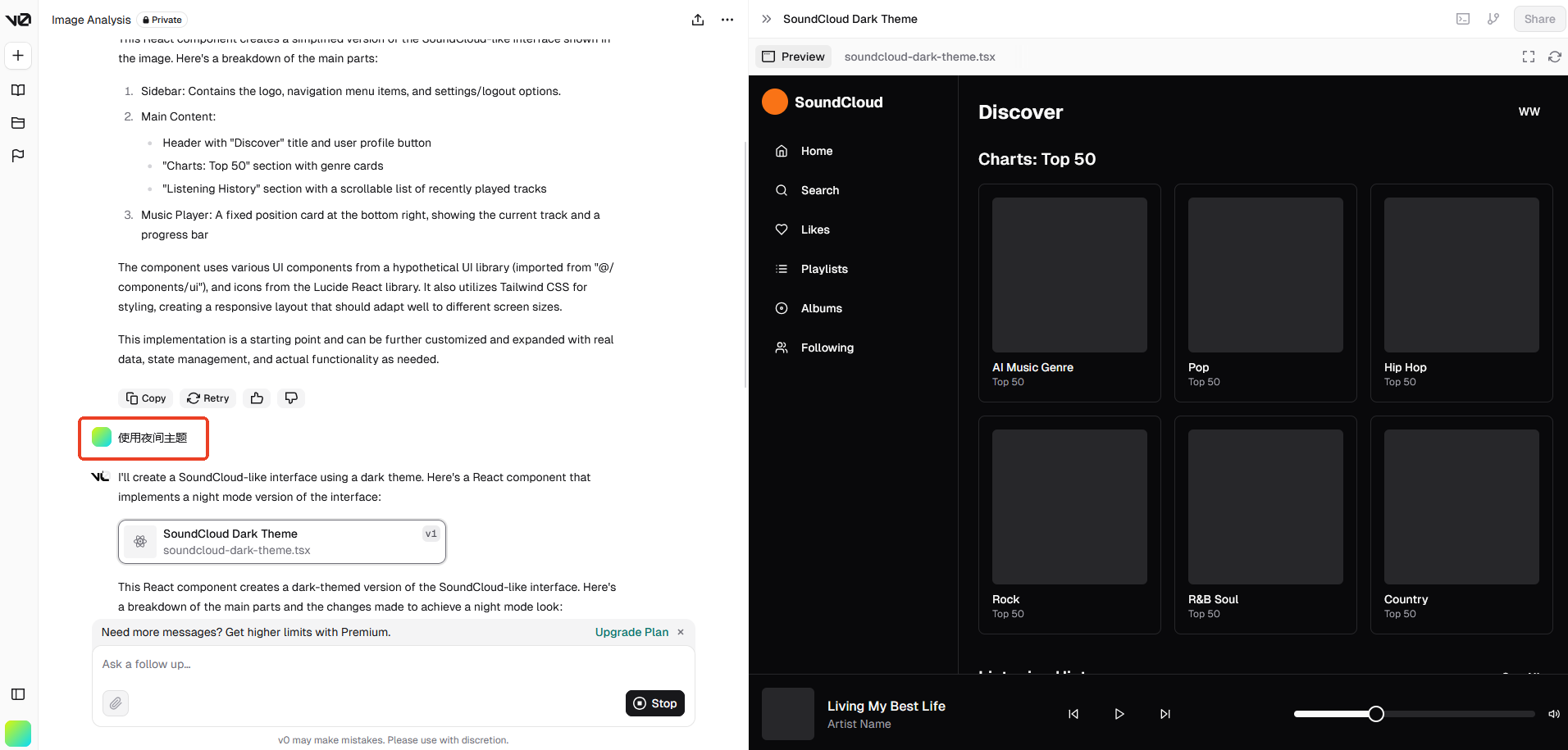
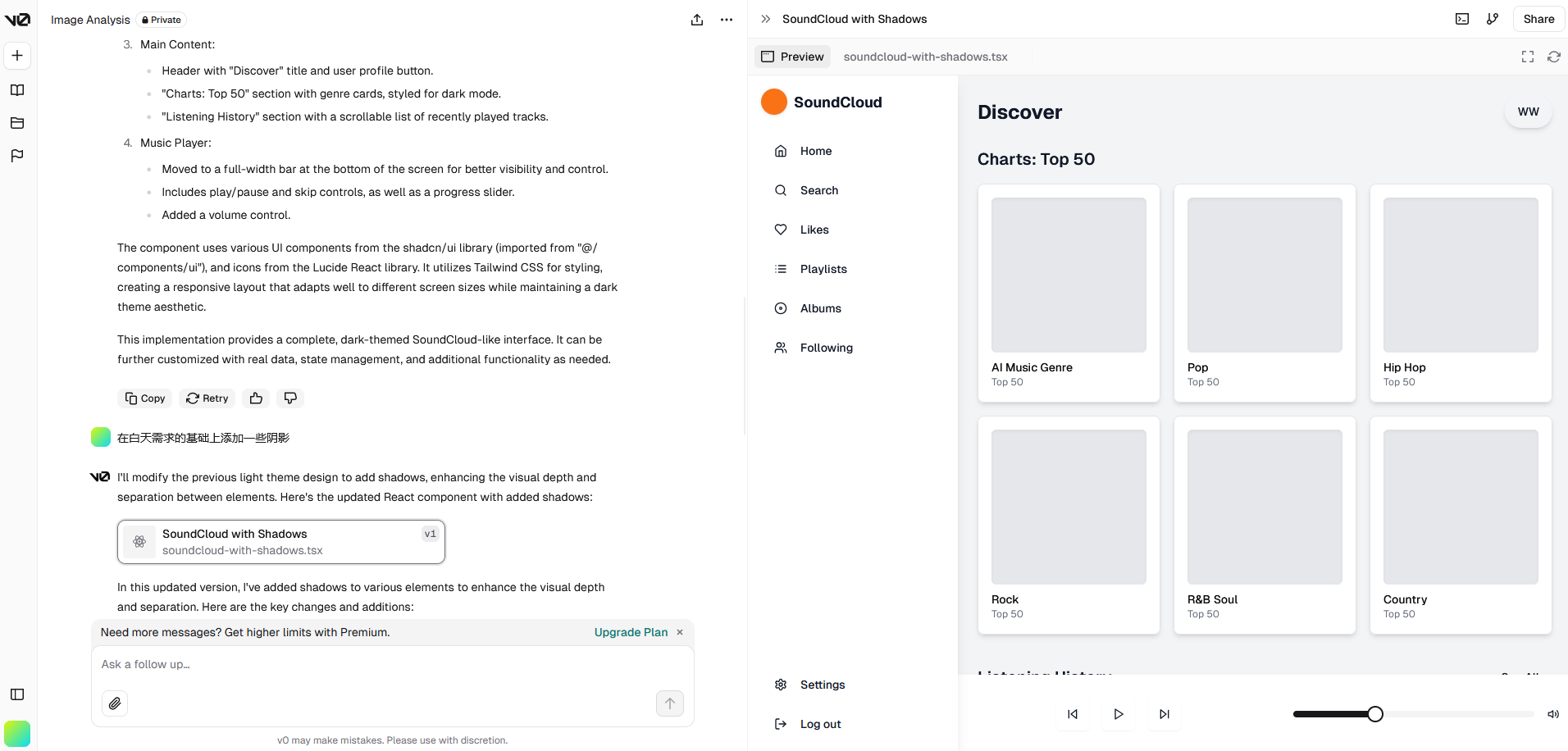
收费情况:付费方式是会员制,可以试用一两个项目。
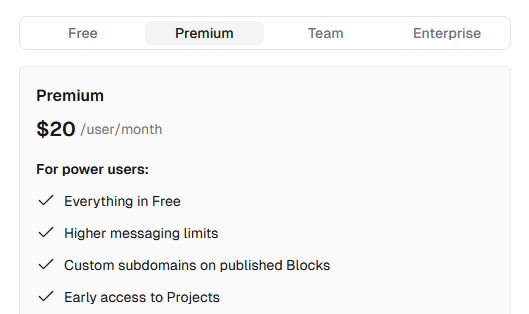
总结
从收费模式上来看,除了 v0 是收费的,其他三个都是开源的,可以自己部署,但要使用 GPT 的 key,但相对地,生成效果都要差一些。
功能上来看都可以用自然语言说明需求,应该是结合了 Chat-GPT,通过一步步的描述细化需求,可以得到更好的结果。
结果上来看个人认为这个还原度还是比较一般的,很难将设计图的细节完全表现出来,不过确实能快速生成代码,可以用作结构参考甚至直接拿 HTML 部分的结构来用,但样式肯定是要调整的。
然后再仔细看看代码部分,这几个框架全部采用了原子化 CSS 方案,用多个类名代替 CSS 属性,这两年在前端领域也算比较流行,比如 Open AI 官网就使用 Tailwind CSS 框架,另一个框架 UnoCSS 也在一些网站得到应用,但在大型的和样式较复杂的项目中运用还有些争议,如果团队中并不是所有人都熟悉这种写法,那么这种代码的可维护性还是比较差的。
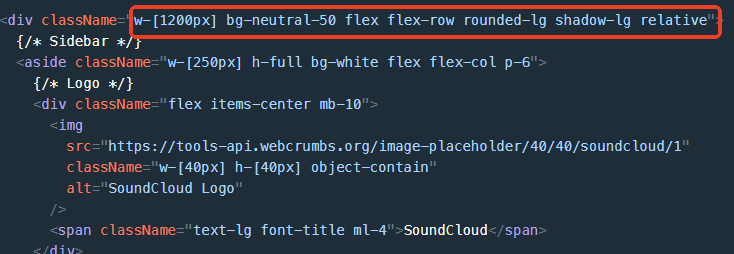

稍微有一点像当年的 Dreamweaver,可以通过拖控件生成代码,但大家都知道,全部都是行内样式有多难维护。不过如今的生成代码质量要好得多。
抛开代码的优劣,可以看到 AI 生成网页的前景还是有的,比如集成在 IDE 中的插件,可以读取当前项目的代码风格进行生成,也可以做到如上几个项目的效果时,可以生成更符合项目的风格的代码,也更方便操作选取需要重新生成的部分,这一点在 AI 绘画部分也有用到。另一方面来说,像 v0 这种产品作为快速生成原型用于验证设计的工具已经足够了。
高情商说法:进步空间还很大。
而且将设计图转为代码只是前端工作的冰山一角,暂时想完全依赖还是挺难的,直接用 Copilot 这种 AI 代码提示工具进行开发,效率也差不多。
3. AI 绘画
AI 暂时还不能替代前端,那么最先受到冲击的绘画行业呢?我看先简单看下 AI 绘画的原理:
上述几个 AI 生成代码的工具,都具有两种形式的输入,一种是自然语言,一种是设计图,也可以描述为文生图和图生图,这两种输入方式也是在 AI 绘画中最主要的,在对 AI 设计工具的探索中,我也产生了一些疑问,AI 是怎么从一张图片生成代码的呢?这个过程中 AI 是如何理解图片的呢?
原理方面,已经有很多深入浅出的资料了,后面也会贴出参考资料,如果直接开始就看尝试去理解原理,可能会有些困难,我们先看下流程,这里只挑几个对生成影响比较大的重点说一下:
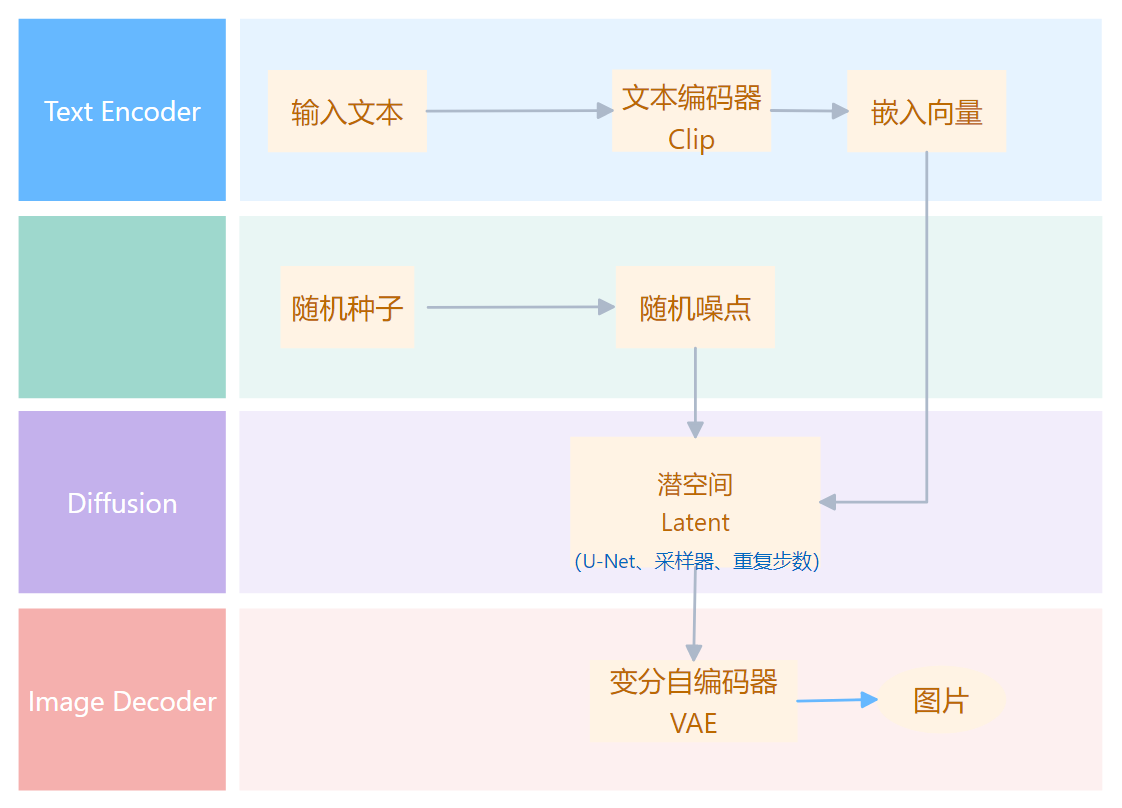
- 文字生成图片:
- 文字输入
- clip_tokenizer(文字转换成数字)
- text_encoder(对输入的文字进行特征编码,用于引导 diffusion 模型进行内容生成)
- diffusion_model(核心部分,下面说)
- decoder(将潜在特征解码成图片)
- 图片生成图片:
- 图片输入
- image_encoder 转为文字
- clip_tokenizer
- text_encoder
- diffusion_model
- decoder
这里面有两个重要的模型:
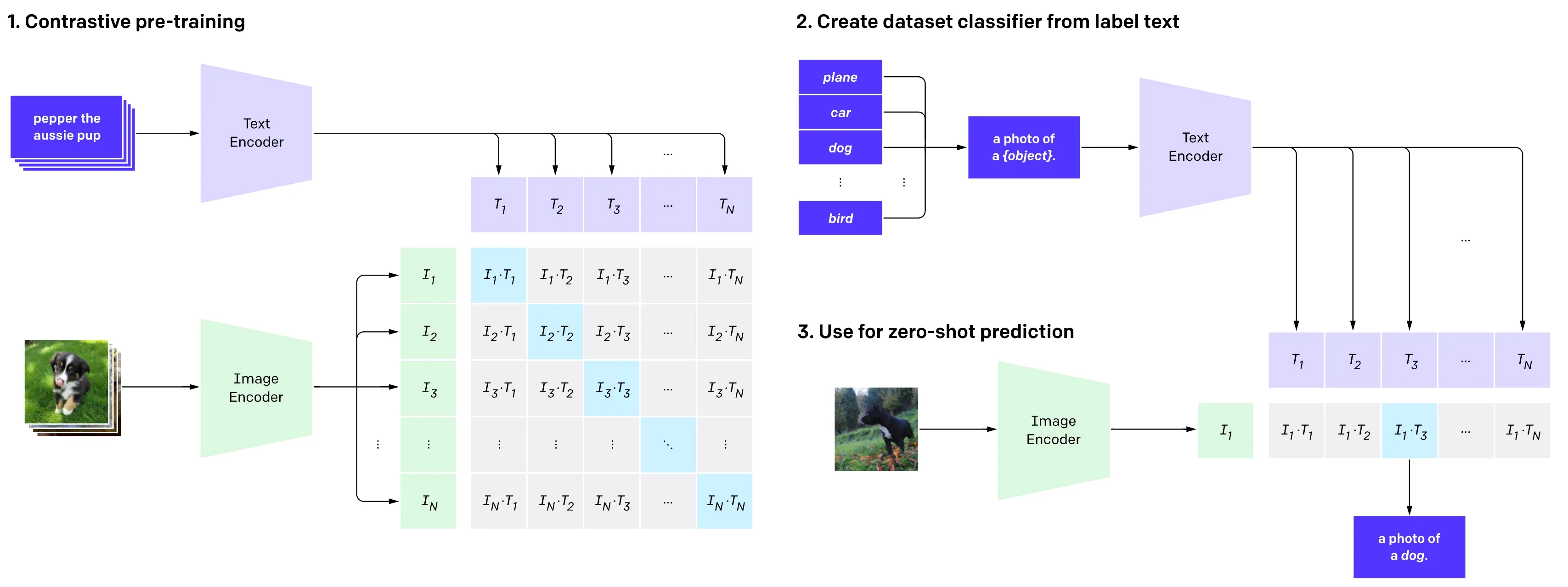
Clip 模型
由 OpenAI 在 2021 年提出,用大量图片和文字对模型进行训练,让模型学会理解图片和文字之间的关系,降低了标注的成本,提高了模型的泛化能力,说人话就是给一张图片打标签。
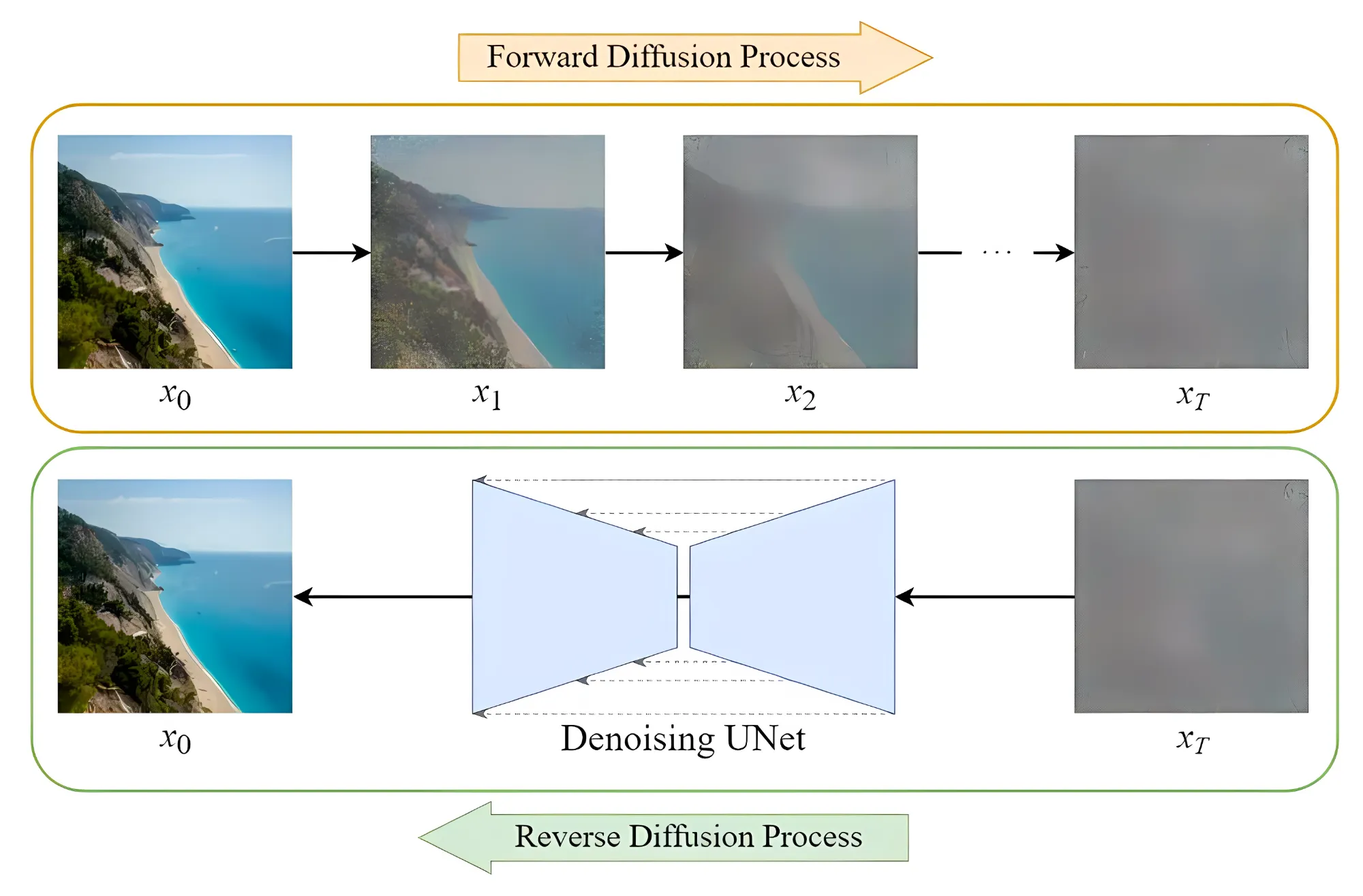
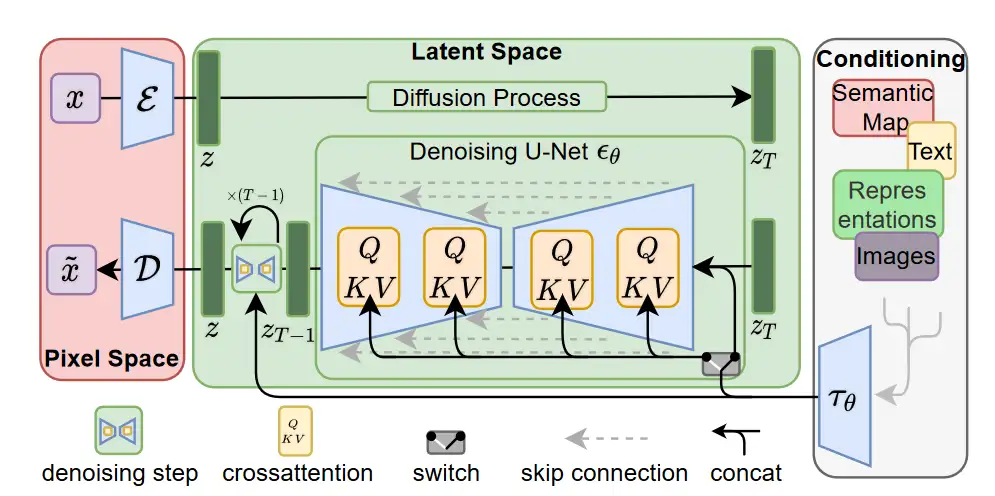
Diffusion 模型
这个是当下 AI 绘画的核心技术,简单来说,先通过对照片添加噪声,然后在这个过程中学习到当前图片的各种特征。之后再随机生成一个服从高斯分布的噪声图片,然后一步一步的减少噪声直到生成预期图片。
2021 年,Open AI 发布了一个名为 DALL-E 的模型,声称这个模型可以从任何文字中创建高质量图像,它所使用的技术即为 Diffusion Models。很快,基于 Diffusion Models 模型的图片生成成为主流。2022 年又发布了 DALL-E 2,可以生成更高质量的图片。但是 OpenAI 一直都没有公开 DALL·E 的算法和模型。
3.1 AI 绘画工具的发展
可以看到,当下的 AI 绘画的理论模型在 2021 年趋于完善,接下来就是 2022 年走上快车道,各种 AI 绘画工具百花齐放:
我 21 年换的显卡,没有关心前沿科技,还选了 AMD 😦 ,今年终于折腾好了,具体 AMD 在 Windows 下部署 Stable Diffusion 的问题,可以看我的另一篇文章。
- 2022 年 2 月:Disco diffusion V5
由 somnai 等几个开源社区的工程师制作的一款基于扩散模型的 AI 绘图生成器,相比传统模型更易用,但是生成的图片比较抽象。
此时人们对于 AI 绘画还是属于嗤之以鼻的状态。
- 2022 年 3 月:Midjourney
由 Disco diffusion 的核心开发参与建设,搭载在 discord 平台,借助 discord 聊天式的人机交互方式,通过对话引导设计的结果,也可以选择倾向的结果,让 AI 按对应方向继续深化下去,所以是不需要设置参数的。
Midjourney 发布 5 个月后,美国科罗拉多州博览会的艺术比赛评选出了结果,一张名为《太空歌剧院》的画作获得了第一名,但它甚至不是人类画师的作品,而是一个叫 MidJourney 的人工智能的画作。参赛者公布这是一张 AI 绘画作品时,引发了很多人类画师的愤怒和焦虑。

- 2022 年 4 月:DALL·E 2
生成的图片质量更高。
- 2022 年 7 月:Stable Diffusion
这个是我今天介绍的重点:由开发公司 Stability AI 发布的 Stable Diffusion,这家公司崇尚开源,他们的宗旨是
AI by the people,for the people
因为上面 DALL·E 是闭源的,Midjourney 以产品的形式收费。
- 2022 年 10 月:NovelAI
Nova AI 是由美国特拉华州的 Anlatan 公司开发的云端软件。最初,该软件于 2021 年 6 月 15 日推出测试版,其主要功能是辅助故事写作。之后,在 2022 年 10 月 3 日,Nova AI 推出了图像生成服务,由于其生成的二次元图片效果出众,因此它被广泛认为是一个二次元图像生成网站。
除了 Disco Diffusion 已经停止更新外,其他几个工具在 2023 年到 2024 年都有不错的发展,靠着各自的特点占据了 AI 绘画的一席之地,直到此时此刻,仍有大量的绘画工具、绘画模型发布,用途效果各异,不一一列举了。
3.2 AI 绘画工具的使用
如同上面所说,我以较为通用的开源工具 Stable Diffusion 为例,介绍一下如何使用 AI 绘画工具。
部署
自行部署模型当然可以,但大家都知道,环境配置方面有各种各样的问题,需要根据各自的情况处理,我另外一篇文章有些不太详细的说明,这里还是以整合包为例快速进入使用阶段。
- 选择一个整合包
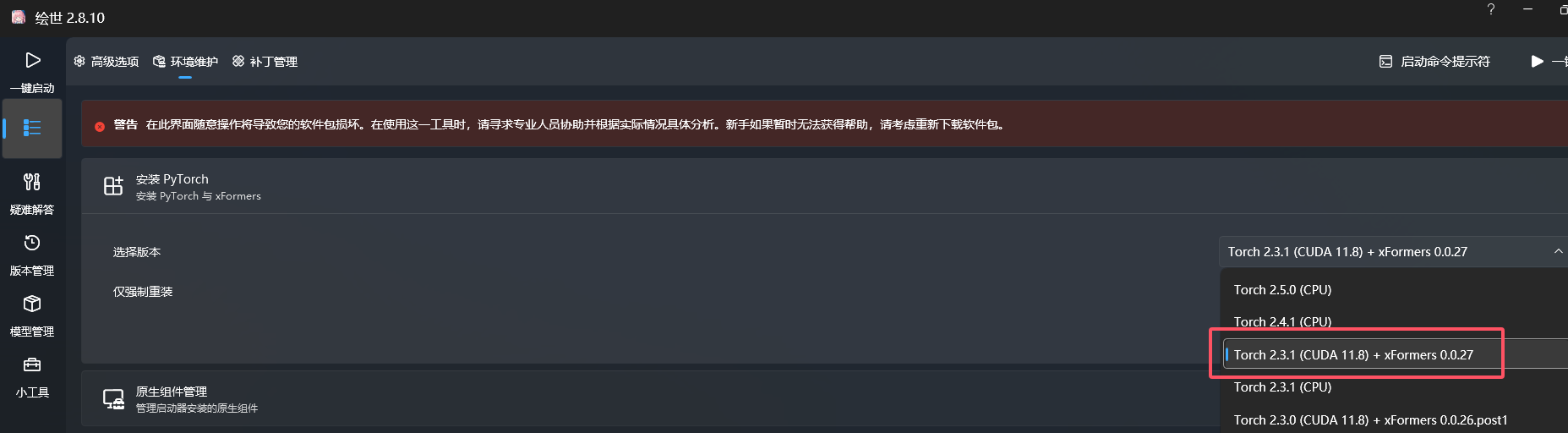
实际上选择很多,无论是一开始热度最高的 AUTOMATIC1111/stable-diffusion-webui,还是国内基于这一版本的绘世整合包,整合包的独立环境,不会影响到本地,能解决一些环境配置的问题。
这里选秋叶的绘世整合包,解压后打开,高级选项-环境维护-安装 PyTorch——这是 Python 的一个深度学习框架,选择一个版本,然后安装。
- 启动
AMD 显卡会提示安装 ROCm,NVIDIA 显卡我不清楚,可能会提示安装 CUDA,安装完成后点击启动,启动后会自动打开浏览器,默认端口 7860,可以在高级选项中修改。
使用
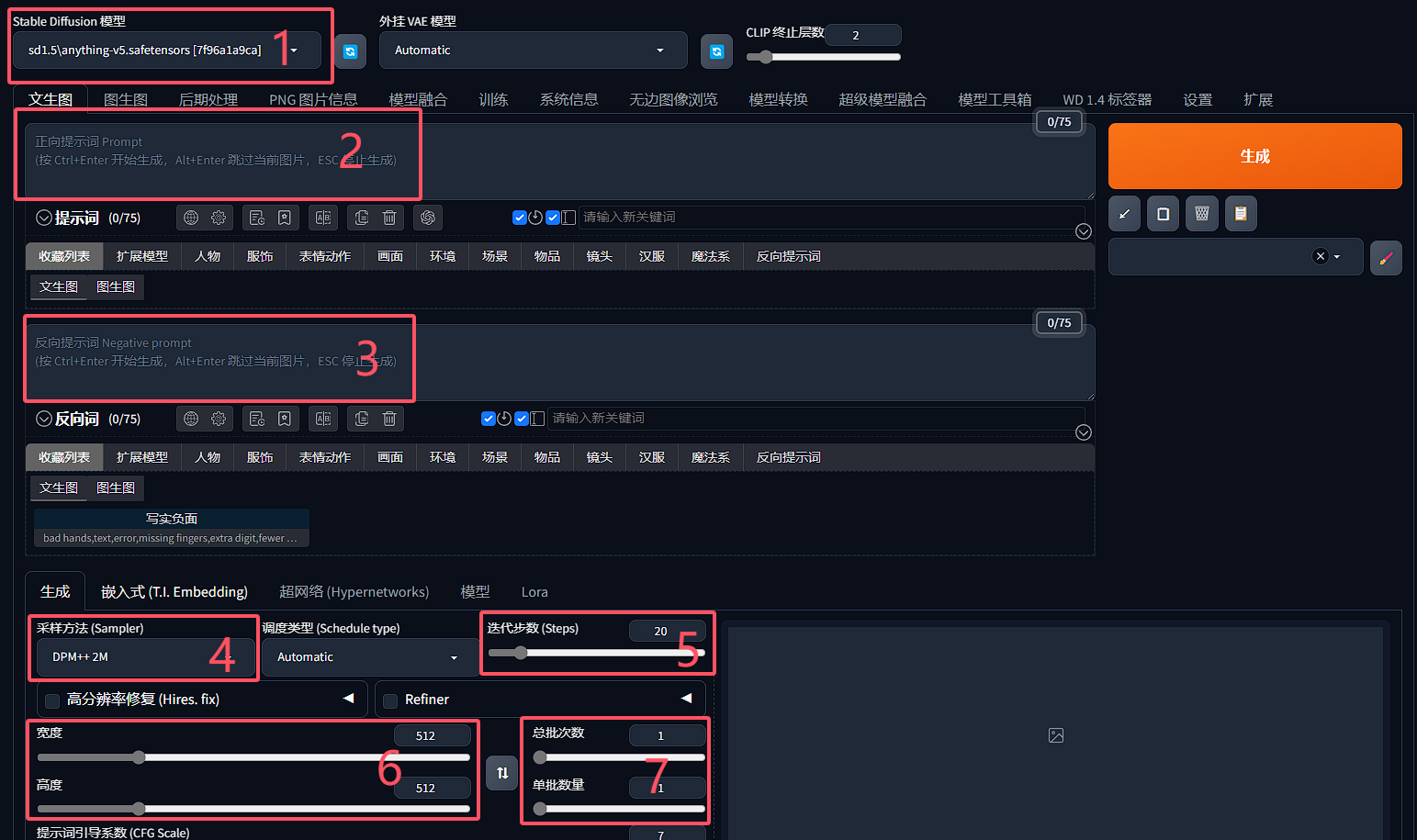
- 选择模型
实际上可以用到不止一个模型,常见的模型分为大模型和用于微调大模型的小模型,这里选择的是最重要的大模型,也叫 Checkpoint。
整合包默认安装的是基于 SD1.5 的 Anything,这个模型可以生成各种风格的图片,不过相对比较早期了,现在可以使用 SD XL。针对想要绘制的不同内容和风格,应该选择不同的模型。模型的使用还有很多内容可以说,我们先用默认的。

- 正向提示词
也就是 Prompt,这个是用来引导模型生成图片的,可以是一个或多个关键词,比如常用的改善画质的 Tag:
masterpiece, best quality
- 逆向提示词
相反的,逆向提示词是用来限制模型生成的内容,比如常用的限制 Tag:
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
举个例子,我们先用正面提示词Ocean生成一张(Anything 是偏卡通的模型,不太明显,这里我用了另一个模型):

通常来说,海是蓝的,但如果我们在负面提示词中加入blue,会发现生成的图片就不一定是蓝色的海:

再添加一个负面提示词green,就会发现生成的图片可能是夕阳下的海,因为此时的海既不是蓝色也不是绿色:

提示词还可以加权重,比如(ocean)表示 1.1 倍,((ocean))表示 1.1×1.1=1.21 倍
[ocean]则是减少权重。
(ocean:1.5)是指定 1.5 倍权重。
Stable Diffusion 刚开始兴盛的时候,Prompt 被大家戏称为“咒语”,因为抄了别人的咒语就能施放同样的法术(生成别人的画风),但是有很多因素都会影响 AI 的生成,这是由模型的原理决定的。
- 采样方法
Stable Diffusion 在生成图像前,会先生成一张完全随机的图像,然后噪声预测器会在图像中减去预测的噪声,随着这个步骤的不断重复最终会生成一张清晰的图像。整个去噪过程叫做采样,使用到的方法叫做采样方法或采样器。
整合包的噪点不明显,这里用 SD.NEXT 的包截图:

推荐 Euler a,和 DPM++ 2M Karras,这个整合包默认也是这个,用同样的提示词,同样的种子,迭代步数 20:
DPM++ 2M

Euler a

- 采样迭代步数
一般 50 以内,通常可以选择 28。有很大的调整空间,采样方法不同,合适的迭代步数也不同。
这里也是用 SD.NEXT 的包截图:
DPM++ 2M,迭代 20 步:
DPM++ 2M,迭代 28 步:

DPM++ 2M,迭代 50 步:

Euler a,迭代 20 步:
Euler a,迭代 28 步:

Euler a,迭代 50 步:

- 图片分辨率
不宜太大,一般不要超过 512×512,超过这个范围会导致生成的图片变形,结构崩溃,这个也和模型的原理有关,而且计算成本也会增加,想要更高分辨率的图片,可以勾选高分辨率修复,生成较小分辨率再超分。
下图是 512×512 的图片,第一张是原图,第二张是超分后的图,但超分其实是一种图生图的重绘:


再看一遍原理
理解完这些参数和生成过程后,再回头看一下模型的原理,就相对好理解了。
把提示词和种子传给模型,经过降噪和扩散,最后 VAE 修复,图片生成。
【AI 绘画】大魔导书:AI 是如何绘画的?Stable Diffusion 原理全解(一)
补充一些模型
- LoRA 和 LyCORIS
LoRA 是除了主模型外最常用的模型。LoRA 和 LyCORIS 都属于微调模型,一般用于控制画风、控制生成的角色、控制角色的姿势等等,你可以自己喂数据进行训练,比如喂 X 张同一个角色让 AI 学习,再加上 LoRA 模型进行输出,就有一定概率生成你需要的角色。
使用方式是以提示词的方式加入,我这里使用的 Lora 是 Silicon-landscape-isolation:<lora:Silicon-landscape-isolation:1>
固定种子,不加入 LoRA 模型,使用提示词 landscape/scenery:

固定种子,加入 LoRA 模型,使用提示词 landscape/scenery:

- VAE
VAE 会影响出图的画面的色彩和某些极其微小的细节。一般用于图片亮度和饱和度的修正、画面较正和以及补光等。绘图时如果出现图片亮度过低、发灰等问题时就需要用到,一般来说大模型自带 VAE。
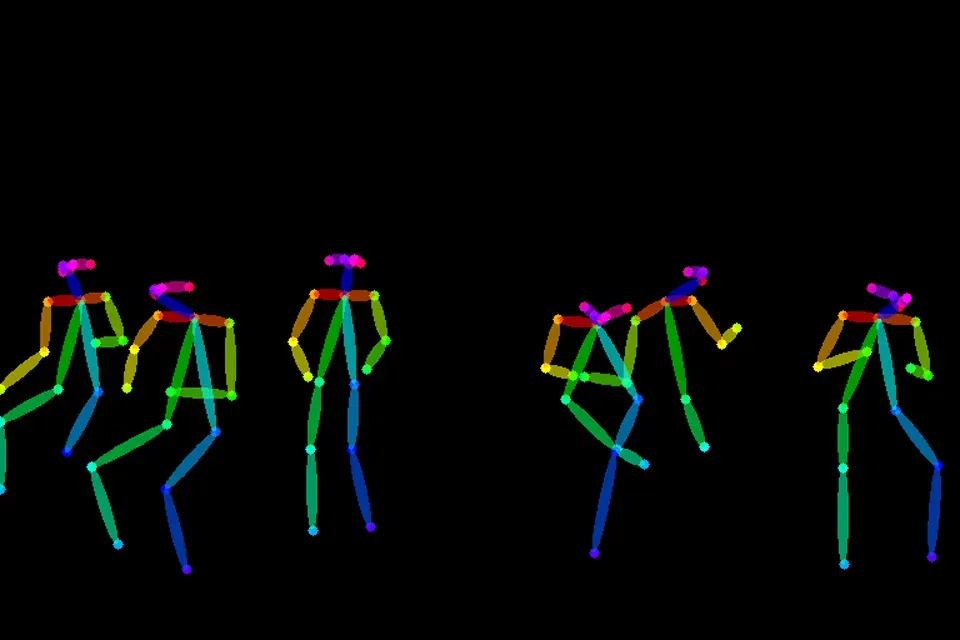
- ControlNet
及其强大的控制模型,它可以做到画面控制、动作控制、色深控制、色彩控制等等。可以通过这样的方式来控制人物的姿势:
- Flux
前 Stability AI 核心成员 Robin Rombach 创立了一个名为 Black Forest Labs 的新公司,并获取了 3200 万美元的融资,并开源了 FLUX.1 系列模型。细节和手脚精准度也非常高,不过配置需求也提高了。
更多详细内容可以参考 【AI 绘画】全部模型种类总结 / 使用方法 / 简易训练指导——魔导绪论
插件、扩展及其他
- 超分


- 重绘

可以看到,这些流程已经是一个全新的研究门类了,并不是一个一键就能简单改变世界的东西。
3.3 AI 绘画的问题
- 版权
这个是来源于提示词的,只是一个提示词或者训练模型,就能以特定画师的风格生成类似的图片,而对于画师来说,也许通过日以继夜的练习才能形成自己的风格,这与当年绘画和摄影的情况如出一辙。
- 结构
人物的结构及手指等细节,对于人类画师也是非常难以掌握的,尽管现在已经有微调模型和重绘的辅助,处理这部分内容也是非常耗时且困难的。顺便提一下,摄影强于绘画表现的透视和结构,反而是 AI 绘画的难点。
- 一致性
即使是用同样的种子和提示词,生成的结果亦有不同,如果理解了前面的内容,就知道这是扩散模型的原理所决定的,虽然也能通过微调模型来解决,但模型的上限就在这里。这也是我认为 AI 绘画在商业上的阻力之一,同样的人物,同样的配饰换了分镜就可能不同,可以称作是作画事故了,毕竟人物配饰也是人物设计的一部分,可能涵盖着一些信息表达。
- 缺乏创造性
前面的问题我觉得也许通过不断地改进模型可以解决,但缺乏创造性是最本质的问题,我们已经接触了各种各样的大模型,应该知道即使经过成千上万的数据训练,模型也是在重复已有的内容,而且在从创作领域来说,AI 并不具备所谓灵感、想法、创意等,离真正的“智能”还有一定的距离,毕竟现在的 AI 不会因为某一天偶然看到的夕阳而产生拍照的想法,而 AI 绘画的使用者反复去调整 Prompt、采样方法、模型等去获得一个符合自身想法的结果图时,不正是以模型为画笔而进行的一种创作吗?
AI 绘画的应用
基于上述的缺点,AI 绘画的商用价值据我了解是很有限的,我所了解的只有一些比较小的工作室作品,或者一些便宜广告里(可能一些更隐性的地方会有应用,比如概念美术和草图等,不是行业人员接触不到),越是专业,AI 的限制就越明显,但反过来说,AI 对于个人来说,是一个很好的工具,可以帮助我们快速生成一些图片,比如博客的封面,或者一些简单的插图,也看到一些画师表示 AI 绘画可以为他们提供一些前期设计的参考,诸如:构图、色彩、感受等。
4. 写在最后
在我看来,AI 绘画是如同摄影一样的新工具,摄影让普通人不需要练习绘画技巧就能记录下生活,AI 绘画让普通人不需要练习绘画技巧就能生成需要的图片。毕竟最早研究摄影的人中也不乏画家,随着摄影发展的同时也有了摄影师这个行业,之后这两个行业也在互相借鉴学习,在之后的发展中,绘画和摄影都产生了不同的新流派,绘画更有表现力,摄影更有真实感,在 AI 的冲击下,绘画也可能会产生新的流派,在 AI 无法完成的复杂结构上取得进步。
这样看来,当下的 AI 既不能代替画师,也不会代替前端,可能最先淘汰反而是 AI 的 Prompt 工程师了,毕竟模型一天一个样,即使是 Stable Diffusion 这样的热门模型也在被逐渐替代,此时我们能做还是那句老话:
Keep hungry, keep foolish.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号