在Windows环境下使用AMD显卡运行Stable Diffusion
现在用的电脑是 21 年配的,当时并没有 AI 相关的需求,各种各样的原因吧,抉择后选择了 AMD 的显卡,但在 2024 年的今天,使用 AI 进行一些工作已不再是什么罕见的需求,所以我也想尝试一下,但发现 AMD 显卡却处处碰壁,研究后发现,经过各方面的努力,AMD 显卡在 AI 方面的支持已经有了很大的进步,但是由于历史原因,NVIDIA 显卡在这方面的支持更加完善,所以我在这里记录一下我在 Windows 环境下使用 AMD 显卡运行 AI 程序的过程。
这些步骤现在已经可以通过整合包完成,搜索“绘世整合包”就能找到,这里只是记录一下学习过程,方便学习查阅。
CUDA
首先要说的就是 CUDA,不同于 CPU,GPU 的并行计算能力更强,而 CUDA 就是 NVIDIA 推出的并行计算平台和编程模型,它可以让开发者对 GPU 进行编程,然后在 NVIDIA 的 GPU 上运行,这样就可以充分利用 GPU 的并行计算能力,而不是只用来显示图形。CUDA 是 NVIDIA 的专利技术,所以 AMD 显卡是无法使用 CUDA 的。并且,得益于比较早的推出时间,CUDA 的生态系统也更加完善,有很多的库和框架都是基于 CUDA 的,比如 TensorFlow、PyTorch 等。
而当下热门的 AI 绘画工具 Stable Diffusion 就需要用到 PyTorch,换句话说,如果 AMD 显卡能够支持 PyTorch,那么就可以运行 Stable Diffusion。
Linux
首先我了解到在 Linux 环境下,AMD 显卡是可以运行 PyTorch 的,而且 AMD 也推出了 ROCm,这是一个开源的并行计算平台,可以让 AMD 显卡运行 PyTorch,但是在 Windows 环境下,ROCm 并不支持 PyTorch,所以我们需要另辟蹊径。
研究过程中也考虑了装双系统,但以双系统的方式来使用 AI 绘画较为麻烦,可能过一段时间就不想再切换系统了,所以我还是更希望在 Windows 环境下使用 AMD 显卡运行 Stable Diffusion。
Linux 环境下的运行效率据说已经没有什么损耗了,相关资料很多,这里不放了。
DirectML
2023 年的方案里,能看到名为 pytorch-directml 的项目,这是一个 PyTorch 的后端,可以让 PyTorch 在 Windows 环境下使用 DirectML 运行,而 DirectML 是微软推出的一个机器学习加速库,可以让 PyTorch 在 Windows 环境下使用 AMD 显卡运行。
在经过社区的努力后,克服重重困难,pytorch-directml 项目已经可以在 Windows 环境下使用 AMD 显卡运行 PyTorch 了,这就为我们提供了一个在 Windows 环境下使用 AMD 显卡运行 Stable Diffusion 的方案。
stable-diffusion 最有名的整合包 AUTOMATIC1111/stable-diffusion-webui 的 wiki 中也有 AMD 显卡的使用说明,但是这个项目并没有直接支持 AMD 显卡,所以我们需要使用一个 fork 项目。wiki 截图如下:
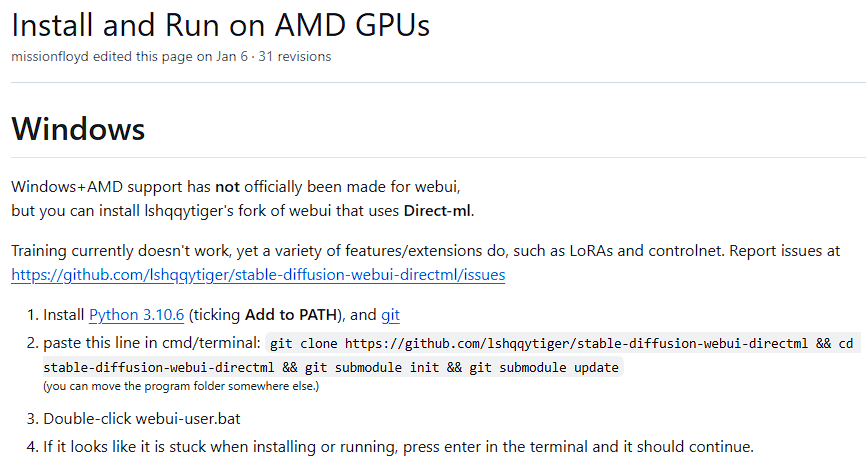
通过链接跳转到对应项目,发现名称已经变了——lshqqytiger/stable-diffusion-webui-amdgpu,这个项目早期应该是叫做 stable-diffusion-webui-directml,可以看出现在并不仅限于使用 pytorch-directml,后面我们会提到。
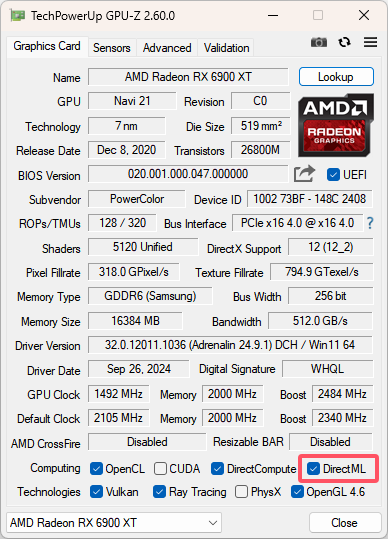
下图是 GPU-Z 的截图,可以看到显卡对 DirectML 以及 CUDA 的支持情况,虽然本文一直说的是 AMD 显卡,但实际上 Intel 的显卡也有一部分支持 DirectML,理论上也是可以使用这个方案的,不过案例较少,没有了解,这里不详细说明了。
参考资料:
在 windows 上通过 pytorch-directml 利用 AMD 显卡加速 stable-diffusion
ROCm
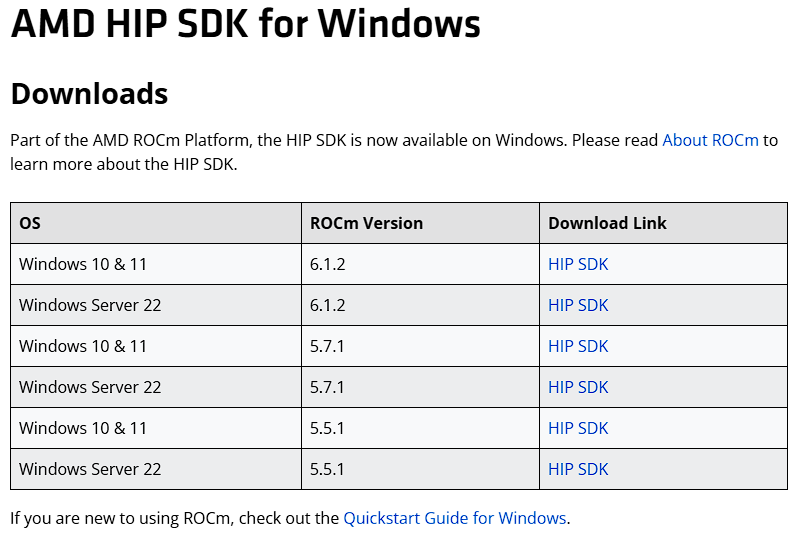
AMD ROCm 是一个开放式软件栈,包含多种驱动程序、开发工具和 API,可为从底层内核到最终用户应用的 GPU 编程提供助力。ROCm 已针对生成式 AI 和 HPC 应用进行了优化,并且能够帮助轻松迁移现有代码。
定位应该和 CUDA 类似,这个只要到官网下载安装就行了,目前的 Stable Diffusion 应该是只能使用 5.7 版本的,下载包命名的时间是 23 年 Q4。
PyTorch
PyTorch 是一种用于构建深度学习模型的功能完备框架,是一种通常用于图像识别和语言处理等应用程序的机器学习。使用 Python 编写,因此对于大多数机器学习开发者而言,学习和使用起来相对简单。PyTorch 的独特之处在于,它完全支持 GPU,并且使用反向模式自动微分技术,因此可以动态修改计算图形。这使其成为快速实验和原型设计的常用选择。
如果使用 DirectML 方案,那么就需要安装 pytorch_directml:
pip install torch-directml
Python
既然反复提到 PyTorch,那这里在说一下 Python,相关学习资料多如牛毛,这里不过多介绍了,主要说一下版本问题,与前端的 Node.js 环境类似,不同版本适配情况也不同,能做的工作也不一样,所以需要的一个类似版本切换的工具,Node.js 使用的是 nvm,Python 可以用 Conda,原理不太一样,Conda 是创建一个对应版本的虚拟环境,然后在虚拟环境中安装对应版本的 Python,这样就可以在不同的项目中使用不同的 Python 版本了。如果不是经常用到 Python 开发的话,使用 MiniConda 就可以了,这个是一个轻量级的 Conda,只包含了最基本的功能,不会占用太多空间。
- 下载安装
latest-miniconda-installer-links
- 创建虚拟环境
上面的 DirectML 方案中,Wiki 有提到推荐 Python 3.10.6
# 创建虚拟环境
conda create -n pytdml python=3.10.6
# 第一次使用需要初始化
conda init
# 激活虚拟环境
conda activate pytdml
# 安装 pytorch_directml
pip install torch-directml
参考资料:
在 Windows 上通过 DirectML 启用 PyTorch
ZLUDA
其实说了那么多 DirectML,但是实际上这个方案现在已经不是最好的了,而且 DirectML 仍然不能将 AMD 显卡的性能全部发挥出来,今年 2 月份,ZLUDA 发布了 AMD 显卡版本,可以让 AMD 显卡运行 CUDA 程序,这样就可以在 Windows 环境下使用 AMD 显卡运行 Stable Diffusion 了。
ZLUDA 是非 NVIDIA GPU 上 CUDA 的替代方案。ZLUDA 允许使用非 NVIDIA GPU 运行未修改的 CUDA 应用程序,具有接近原生性能。
理论上,只需安装好 ROCm,然后直接使用 CUDA 版的 pytorch,再用 lshqqytiger 编译的版本替换对应的 CUDA dll 文件,即可直接在 Windows 上运行。
lshqqytiger 版本:https://github.com/lshqqytiger/ZLUDA
另外,webui 推荐 SD.NEXT automatic,这个版本对 AMD 显卡支持更好,我最后是用这个版本跑起来的。运行 webui.bat,默认启动在 7860 端口,第一次启动要编译十几二十分钟,耐心等待,界面如下图:
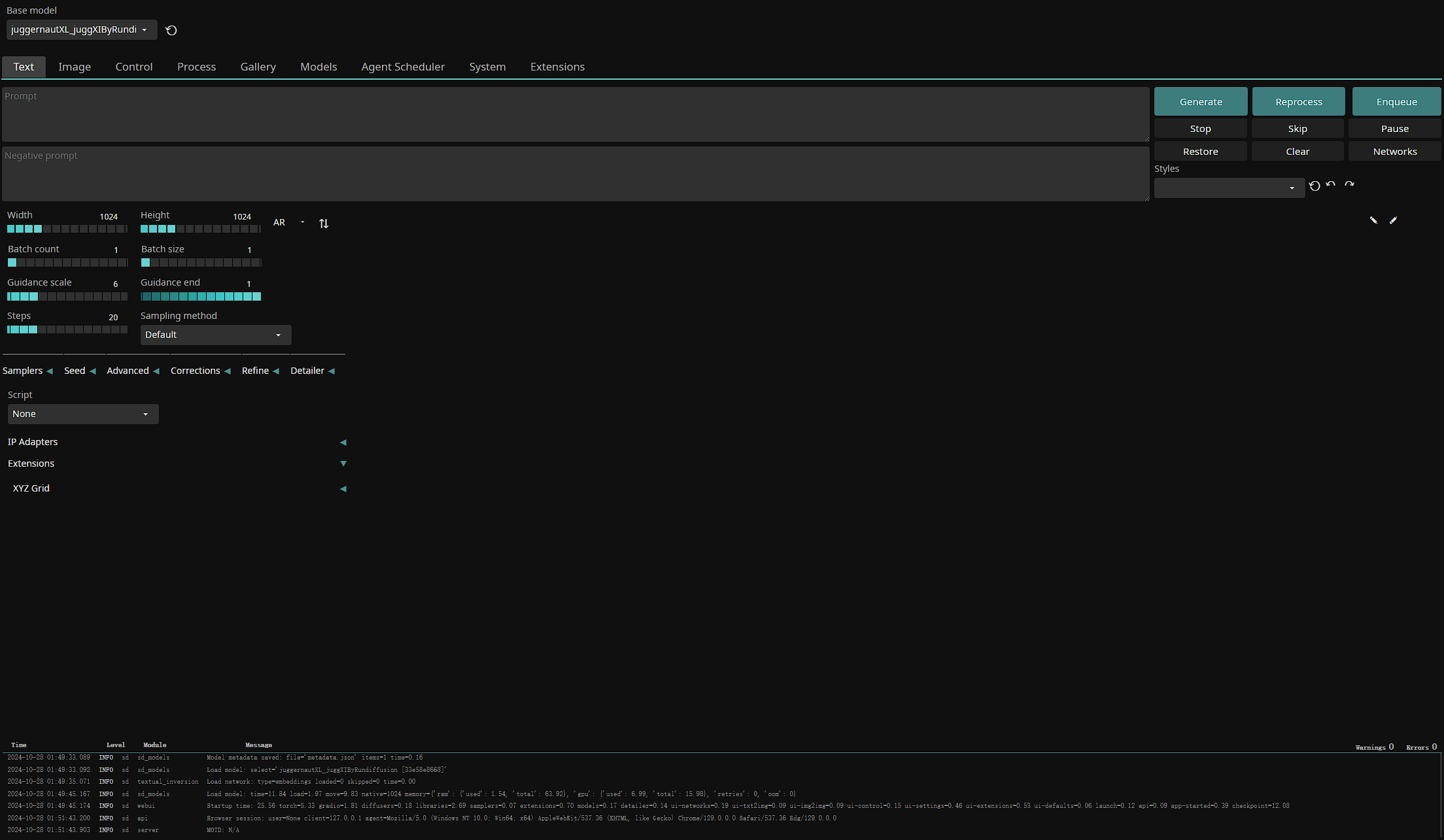
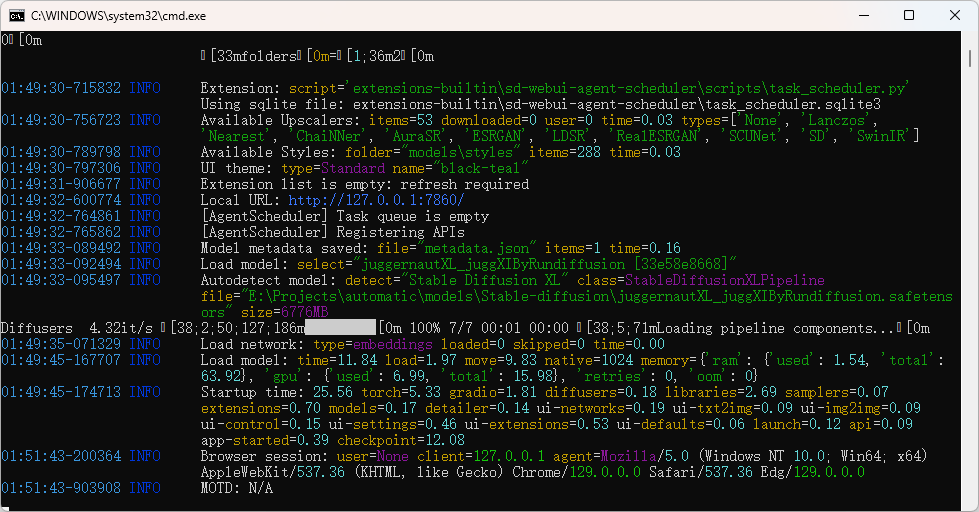
我之前已经挂载过模型了,如果第一次进入可能会让你选择一个模型。加个提示词随便输出一张,尺寸最好不要太大,512×512 就行,原因会在另一篇专门讲生成的文章里说:

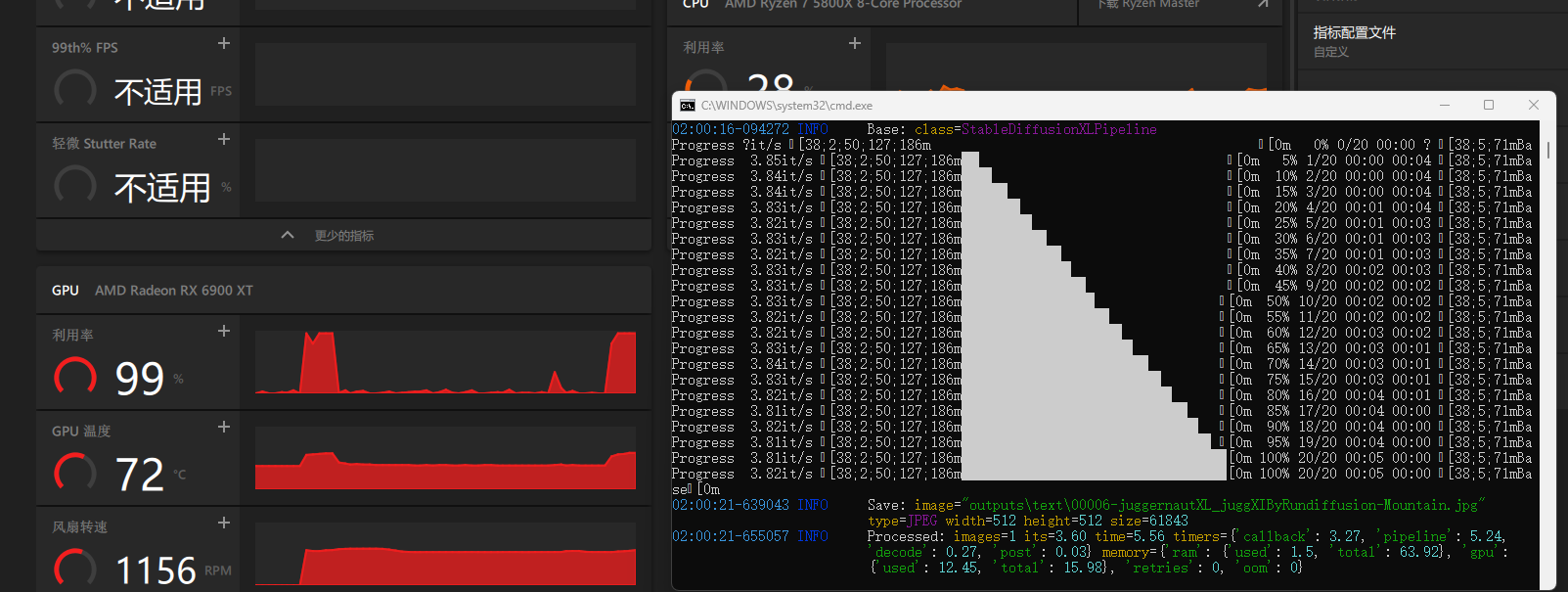
可以看到 GPU 的占用已经上去了,说明此时已经是在用显卡进行计算了:
总结
-
安装 ROCm
-
安装 Python
-
安装 PyTorch
-
安装 ZLUDA(主要是配置环境变量)
-
替换 CUDA dll 文件
-
运行 webui(后来发现整合包好像可以自动处理 PyTorch 等,我这边已经装好了就没法验证)
这一篇主要还是记录一下自己的学习过程,后续在生成方面就打算直接用整合好的包了,功能更加全面,会比自己搭建的方便一些,这样能更集中精力在具体的生成上,而不是在环境上浪费太多时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号