技术分享PPT整理(二):C#从数组到解决哈希冲突的算法
这篇博客起源于我对Dictionary、List、ArrayList这几个类区别的好奇,当时在改造公司的旧系统,发现很多地方使用了ArrayList,但我们平时用的多是泛型集合List
装箱与拆箱
在开始分析集合类之前先简单说下装箱拆箱的概念,在实际的开发中,也许我们很少提到这个概念,但它实际上遍布我们的开发过程,并且对性能有很大的影响,首先来了解一下什么是装箱和拆箱:
装箱和拆箱是值类型和引用类型之间相互转换是要执行的操作。
- 装箱在值类型向引用类型转换时发生
- 拆箱在引用类型向值类型转换时发生
int i = 123;
object o = (object)i; // 将int转object,发生装箱
int j = (int)o; // 从object转回原来的类型,解除装箱
通过上面的说明和例子可以看到,这是一个很简单的概念,实际上就是在我们进行类型转换时发生的一种情况,但如果我们再深入一些可以从数据结构的角度来更清晰地解释这个问题,先看下面两个例子:
值类型
int i = 123;
object o = i; // 装箱会把i的值拷贝到o
i = 456; // 改变i的值
// i的变化不会影响到o的值
Console.WriteLine("{0},{1}", i,o);

原始值类型和装箱的对象使用不同的内存位置,因此能够存储不同的值。
引用类型
public class ValueClass
{
public int value = 123;
public void Test()
{
ValueClass b = new ValueClass();
ValueClass a = b;
b.value = 456;
Console.WriteLine("{0},{1}", a.value, b.value);
}
}
两个变量指向同一块内存数据,当一个变量对内存区数据改变之后,另一个变量指向的数据当然也会改变。
简单地说,值类型的赋值相当于直接将物品交给另一个人,而引用类型的赋值相当于将一个存放了物品的地址复制给另一个人,每当有人来找的时候,再根据地址去找到物品,地址没有发生改变的情况下,将里面的物品替换,那么后面所有顺着线索找过来的人拿到的都是被替换的物品。如果以数据结构的知识来看,引用类型和值类型就是分别存放在堆和栈里面的数据。
堆与栈
我们把内存分为堆空间和栈空间:
- 线程堆栈:简称栈Stack,栈空间比较小,但是读取速度快
- 托管堆:简称堆Heap,堆空间比较大,但是读取速度慢
栈存储的是基本值类型,堆存储的是new出来的对象。引用类型在栈中存储一个引用,其实际的存储位置位于托管堆。
值类型:在C#中,继承自System.ValueType的类型被称为值类型,主要有以下几种:bool、byte、char、decimal、double、enum、float、Int、long、sbyte、short、struct、uint、ulong、ushort
引用类型:以下是引用类型,继承自System.Object:class、interface、delegate、object、string
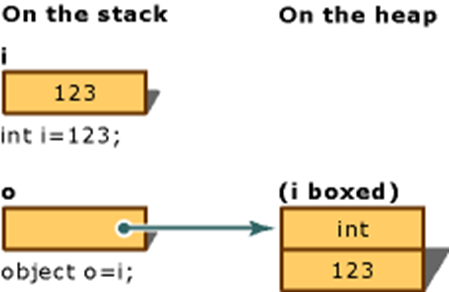
装箱(Boxing)
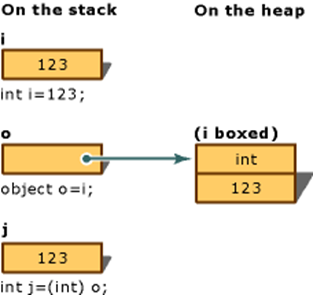
我们再回头看刚才例子的装箱操作,可以用很清晰的图片来表达:
int i = 123;
object o = (object)i;
int i = 123;
object o = i;
int j = (int)o;
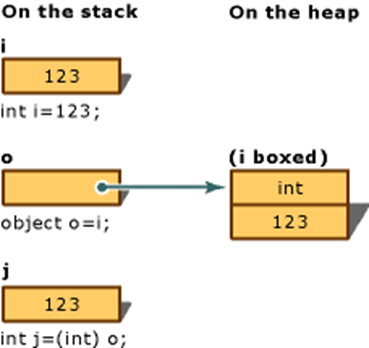
装箱操作是在堆中开辟一个新的空间,再将栈中的数据赋值过去,拆箱操作则相反。
取消装箱(Unboxing)
取消装箱也就是拆箱,是从object类型到值类型或从接口类型到实现该接口的值类型的显式转换。取消装箱操作包括:
- 检查对象实例,以确保它是给定值类型的装箱值。
- 将该值从实例复制到值类型变量中。
要在运行时成功取消装箱值类型,被取消装箱的项必须是对一个对象的引用,该对象是先前通过装箱该值类型的实例创建的。
int i = 123;
object o = i;
try
{
int j = (short)o; // 拆箱
Console.WriteLine("拆箱成功!");
}
catch (InvalidCastException e)
{
Console.WriteLine("{0} 拆箱失败!", e.Message);
}
C#动态数组(ArrayList)
了解了装箱和拆箱的数据结构,让我们把目光拉回开篇,讨论的问题是集合类的区别,先从C#的动态数组ArrayList开始说明。
动态数组(ArrayList)代表了可被单独索引的对象的有序集合。它基本上可以替代一个数组。但是,与数组不同的是,您可以使用索引在指定的位置添加和移除项目,动态数组会自动重新调整它的大小。它也允许在列表中进行动态内存分配、增加、搜索、排序各项。
ArrayList al = new ArrayList();
al.Add(45);
al.Add(78);
al.Add(33);
al.Add(56);
al.Add(12);
al.Add(23);
al.Add(9);
foreach (short i in al)
{
Console.Write(i + " ");
}
而我们现在平时比较常用的是命名空间同为System.Collections.Generic的泛型集合List<T>,使用这个类可通过索引访问对象的强类型列表,提供用于对列表进行搜索、排序和操作的方法。
这两种集合类的功能看上去差不多,但为什么现在都使用后者呢?这里先看个简单的例子:
// ArrayList
private static void TestArrayListAddByValue()
{
for (int i = 0; i < testValue; i++)
{
arrayListValue.Add(0);
}
description = "ArrayList值类型";
}
private static void TestArrayListAddByReference()
{
for (int i = 0; i < testValue; i++)
{
arrayListReference.Add("0");
}
description = "ArrayList引用类型";
}
// List<T>
private static void TestListAddByValue()
{
for (int i = 0; i < testValue; i++)
{
listReference.Add(0);
}
description = "List添加值类型";
}
private static void TestListAddByReference()
{
for (int i = 0; i < testValue; i++)
{
listValue.Add("0");
}
description = "List添加引用类型";
}
程序执行的结果:
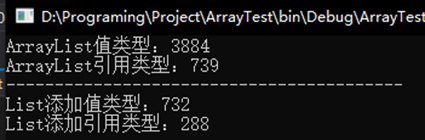
性能上的差异显而易见,那么为什么会有这样的结果呢?我们再带上其他集合类一起说明。
HashTable、Dictionary和List
- HashTable 散列表(也叫哈希表),是根据关键字(Key value)而直接访问在内存存储位置的数据结构。
- Dictionary<TKey, TValue> 泛型类提供了从一组键到一组值的映射。字典中的每个添加项都由一个值及其相关联的键组成。通过键来检索值,实质其内部也是散列表
- List
是针对特定类型、任意长度的一个泛型集合,实质其内部是一个数组。
ICollection和ICollection
这三个是我现在还比较有疑问的类,我们可以先观察一下这张关系表,发现在结构上似乎有所对应,ArrayList和HashTable实现ICollection接口,List

还是刚才的代码,我又引入新的类执行了一遍,并且这次还加入了遍历数据的时间:

看一看出List与Dictionary的差距好像不是特别大,暂且不谈,主要还是HashTable的表现欠佳,其实也就是ICollection和ICollection
除了装箱会消耗时间外,在测试的时候发现当循环的次数超过某个值的时候,使用HashTable的程序发生了可以复现的崩溃,个人猜测应该是内存溢出,由于测试的具体环境不同,这里就不写出具体的值了,感兴趣可以自己测试一下。
Dictionary与List
横向的比较可以得出是装箱造成了性能损耗这个结果,那么纵向比较ICollection
我们要从存储结构和操作系统的原理谈起。
首先我们清楚List
而HashTable或者Dictionary,他是根据Key而根据Hash算法分析产生的内存地址,因此在宏观上是不连续的,虽然微软对其算法也进行了很大的优化。
由于这样的不连续,在遍历时,Dictionary必然会产生大量的内存换页操作,而List只需要进行最少的内存换页即可,这就是List和Dictionary在遍历时效率差异的根本原因。
除了刚才的遍历问题,还要提到Dictionary的存储空间问题,在Dictionary中,除了要存储我们实际需要的Value外,还需要一个辅助变量Key,这就造成了内存空间的双重浪费。
而且在尾部插入时,List只需要在其原有的地址基础上向后延续存储即可,而Dictionary却需要经过复杂的Hash计算,这也是性能损耗的地方。
(Dictionary插入效率低的原因)
综上所述,List在插入数据时更有优势,而Dictionary则因为有哈希表的存在,这就相当于有一个目录,可以根据Key值更快地定位到需要的Value,只不过在数据量不大的情况下难以体现出差异,我们可以提升一下程序的数据精度:
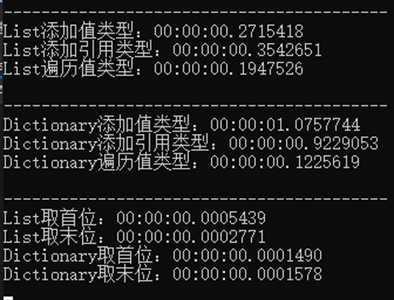
可以看出,在取出某个数据时,Dictionary<T,K>更具优势。
哈希冲突
在查资料的时候也顺便学习了一下哈希冲突相关的知识,上文提到Hashtable和Dictionary从数据结构上来说都属于Hashtable(哈希表),都是对关键字(键值)进行散列操作,将关键字散列到Hashtable的某一个槽位中去,不同的是处理碰撞的方法。散列函数有可能将不同的关键字散列到Hashtable中的同一个槽中去,这个时候我们称发生了碰撞,为了将数据插入进去,我们需要另外的方法来解决这个问题。这里举两个常见的例子:开放寻址法和链表法。
开放寻址法
开放寻址法中也有很多分类,这里以比较容易的线性探测为例,有这样一组数字:12,67,56,16,25,37,22,29,15,47,48,34,前五个已经被分别存放在下标为0,1,4,7,8的这五个位置,这时按顺序要将37也插入这个集合,那么就从0开始找,发现0的位置已经被占用了,再看1也被占用了,当搜索到2的时候发现是空的,那么37就被存放在了下标为2的这个位置,依次类推,这样就可以将所有数字存入集合,过程如下图:
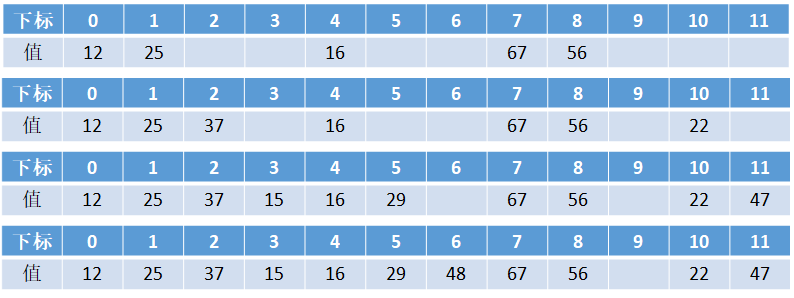
开放寻址法只用数组一种数据结构存储,继承了数组的优点,对CPU缓冲友好,易于序列化。但是对内存的利⽤率并不如链表法,且冲突的代价更高。当数据量比较小、装载因子小的时候,适合采⽤开放寻址法。这也是Java中的ThreadLocalMap使⽤开放寻址法解决散列冲突的原因。
链表法
开放寻址法很好理解,其实就是一间间地开门看过去,有人就换下一间,直到找到没人的房间,再看链表法,就相对巧妙一些,还是刚才那组数字,我们现在有12个位置,那么我们就让每一个数字以12为除数取余,再通过链表将他们安放到对应的位置,一旦发生冲突就在链表后面再加一节,因为链表的特性,地址永远不会冲突,只不过当我们需要找到对应的数据时要对单个链表进行遍历。
链表法对内存的利⽤率比开放寻址法要高。因为链表结点可以在需要的时候再创建,并不需要像开放寻址法那样事先申请好。链表法比起开放寻址法,对大装载因⼦的容忍度更⾼。基于链表的散列冲突处理⽅法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略,比如⽤红黑树代替链表。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号