
2.3 控制
条件码
前面我们在操作数指示符和数据传送指令中介绍了整数寄存器,在 32位 CPU 中包含一组 8 个存储 32 位值的寄存器,即整数寄存器。它可以存储一些地址或者整数的数据,有的用来记录某些重要的程序状态,有的则用来保存临时数据。而这里我们要介绍的是条件码(condition code)寄存器。它与整数寄存器不同,它是由单个位组成的寄存器,也就是它们当中的值只能为 0 或者 1。当有算术与逻辑操作发生时,这些条件码寄存器当中的值会相应的发生变化。也就是说可以检测这些寄存器来执行条件分支指令。常用的条件码如下:
①、CF:进位标志寄存器。最近的操作是最高位产生了进位。它可以记录无符号操作的溢出,当溢出时会被设为1。
②、ZF:零标志寄存器,最近的操作得出的结果为0。当计算结果为0时将会被设为1。
③、SF:符号标志寄存器,最近的操作得到的结果为负数。当计算结果为负数时会被设为1。
④、OF:溢出标志寄存器,最近的操作导致一个补码溢出(正溢出或负溢出)。当计算结果导致了补码溢出时,会被设为1。
从上面可以看出,CF和OF可以判断有符号和补码的溢出,ZF判断结果是否为0,SF判断结果的符号。这是底层机器的设定,而我们所编程用的高级语言(比如C,Java)就是靠这四个寄存器,演化出各种各样的流程控制。
设置条件码
通常情况下,条件码寄存器的值无法主动被改变,它们大多时候是被动改变,这算是条件码寄存器的特色。这其实理解起来并不困难,因为条件码寄存器是1位的,而我们的数据格式最低为b,也就是8位,因此你无法使用任何数据传送指令去传送一个单个位的值。几乎所有的算术与逻辑指令都会改变条件码寄存器的值,不过改变的前提是触发了条件码寄存器的条件。比如对于subl %edx,%eax这个减法指令,假设%edx和%eax寄存器的值都为0x10,则两者相减的结果为0,此时ZF寄存器将会被自动设为1。对于其它的指令运算,都是类似的,会根据结果的不同而设置不同的条件码寄存器。
这里我们需要说明的是,leal 指令作为地址计算的时候,是不改变任何条件码的。
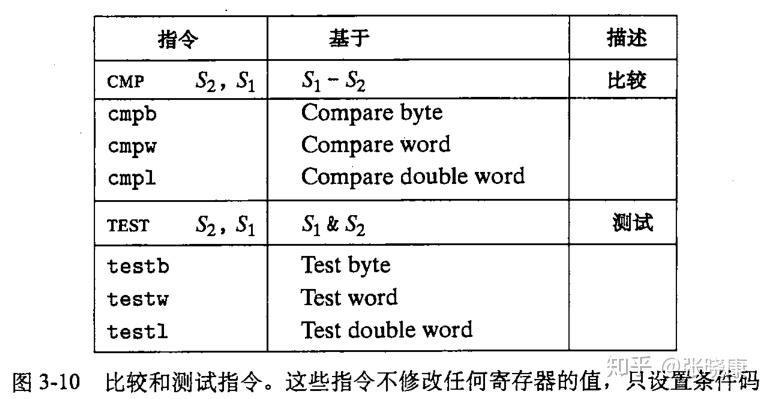
前面我们所讲的算术逻辑指令,在改变整数寄存器的值后,会根据结果设置不同的条件码。而这里还有另外两种指令,它们只设置条件码,而不改变任何其他寄存器的值。如下图:
访问条件码
对于普通寄存器来讲,使用的时候一般是直接读取它的值,而对于条件码,通常不会直接读取。常用的有如下三种方法:
①、可以根据条件码寄存器的某个组合,将一个字节设置为0或1。
②、可以直接条件跳转到程序的某个其它的部分。
③、可以有条件的传送数据。
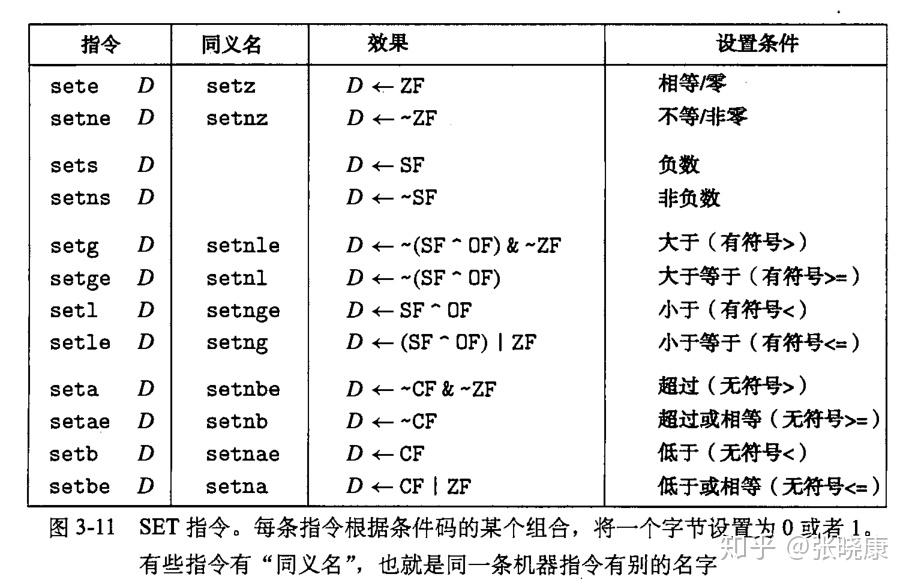
对于第一种情况,下图描述的指令便是根据条件码的某个组合,将一个字节设置为0或1,这一整类指令称为 SET 指令,它们的区别就在与它们考虑的条件码的组合是什么,这些指令名字的不同后缀指明了它们所考虑的条件码的组合。
注意:这些指令的后缀表示不同的条件而不是操作数的大小。比如指令 setl 和 setb 表示 “小于时设置(set less)”和“低于时设置(set below)”,而不是“设置长字(set long word)”和“设置字节(set byte)”。
用条件传送来实现条件分支
在现代处理器上,使用数据的条件转移可能比直接使用条件转移效率高。为了理解为什么基于条件数据传送的代码会比基于条件控制转移的代码性能要好,我们必须了解一些关于现代处理器如何运行的知识。处理器通过使用流水线(pipelining)来获得高性能,在流水线中,一条指令的处理要经过一系列的阶段,每个阶段执行所需操作的一小部分。这种方法通过重叠连续指令的步骤来获得高性能,例如,在取一条指令的同时,执行它前面一条指令的算术运算。要做到这一点,要求能够事先确定要执行的指令序列,这样才能保持流水线中充满了待执行的指令。当机器遇到条件跳转(也称为“分支”)时,只有当分支条件求值完成之后,才能决定分支往哪边走。处理器采用非常精密的分支预测逻辑来猜测每条跳转指令是否会执行。只要它的猜测还比较可靠(现代微处理器设计试图达到90%以上的成功率),指令流水线中就会充满着指令。另一方面,错误预测一个跳转,要求处理器丢掉它为该跳转指令后所有指令已做的工作,然后再开始用从正确位置处起始的指令去填充流水线。正如我们会看到的,这样一个错误预测会招致很严重的惩罚,浪费大约15~30个时钟周期,导致程序性能严重下降。
跳转指令 jump
正常情况下,指令会按照他们出现的顺序一条一条地执行。而跳转指令(jump)会导致执行切换到程序中一个全新的位置,我们可以理解为方法或者函数的调用。在汇编代码中,这些跳转的目的地通常用一个标号(label)指明。比如如下代码:
movl $0,%eax
jmpl .L1
movl (%eax),%edx
.L1:
popl %edx
指令 jmpl .L1 会导致程序跳过 movl 指令,从 popl 开始执行。在产生目标代码文件时,汇编器会确定所有带标号指令的地址,并将跳转目标(目的指令的地址)编码为跳转指令的一部分。
jump 指令有三种跳转方式:
①直接跳转:跳转目标是作为指令的一部分编码的,比如上面的直接给一个标号作为跳转目标
②间接跳转:跳转目标是从寄存器或者存储器位置中读出的,比如 jmp *%eax 表示用寄存器 %eax 中的值作为跳转目标;再比如 jmp *(%eax) 以 %eax 中的值作为读地址,从存储器中读取跳转目标。
③其他条件跳转:根据条件码的某个组合,或者跳转,或者继续执行代码序列中的下一条指令。
跳转指令有几种不同的编码,但最常用的是PC相对编码,也就是将目标指令的地址与紧跟在跳转指令后面那条指令的地址之差作为编码。
注意:当执行PC相对寻址时,程序计数器PC的值是跳转指令后面那条指令的地址,而不是跳转指令本身的地址。因为即使PC存储的是后面那条指令的地址,但CPU仍然可以根据跳转指令的操作码和偏移量计算出跳转目标的地址,仍然可以执行跳转指令的操作,跳转完后再回到PC所指向的下一条指令。
循环
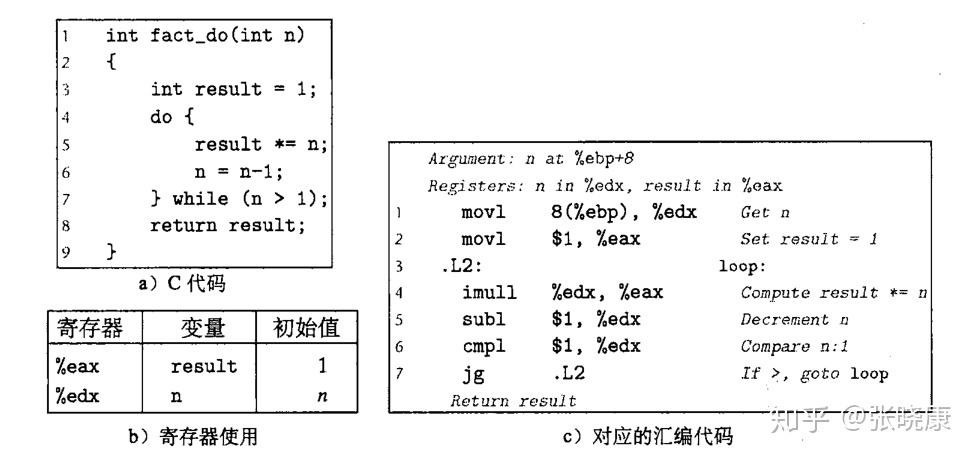
C 语言提供了多种循环结构,比如 do-while、while和for。汇编中没有相应的指令存在,我们可以用条件测试和跳转指令组合起来实现循环的效果。而大多数汇编器会根据一个循环的do-while 循环形式来产生循环代码,即其他的循环一般也会先转换成 do-while 形式,然后在编译成机器代码。
比如如下 do-while 循环:
条件传送指令 cmov
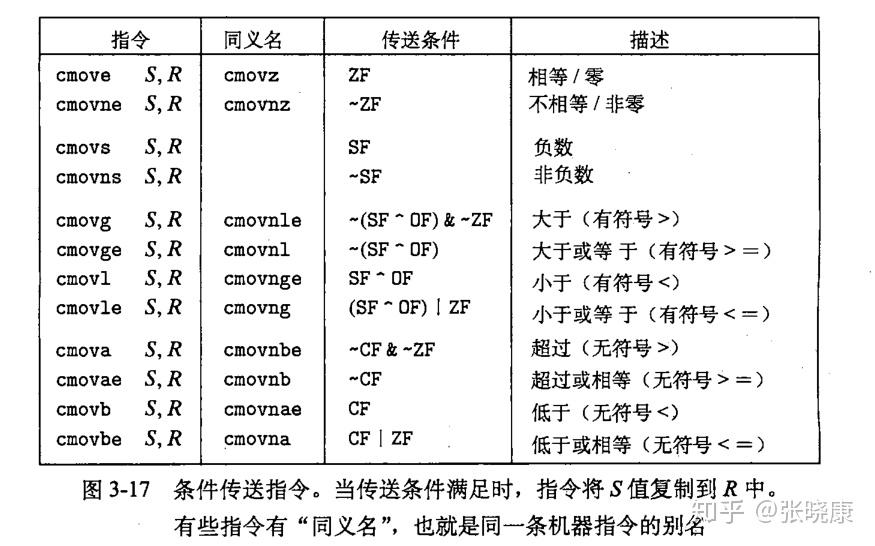
条件传送指令。顾名思义,条件传送指令的意思就是在满足条件的时候进行传送的指令,也就是cmov指令。它与set指令十分相似,同样有12种,也就是加上12种条件码寄存器的组合即可,如下所示:
条件传送指令相当于一个if/else的赋值判断,一般情况下,条件传送指令的性能高于if/else的赋值判断。但是因为条件传送指令将对两个表达式都求值,因此如果两个表达式计算量很大时,那么条件传送指令的性能就可能不如if/else的分支判断了。不过总的来说,这种情况还是很少的,因此条件传送指令还是很有用的,只是并不是所有的处理器都支持条件传送指令,这依赖于处理器以及编译器的编译方式。
条件传送指令最大的缺点便是可能引起意料之外的错误,比如对于下面这一段代码。
int cread(int *xp){
return (xp ? *xp : 0);
}
乍一看,这一段代码是没问题的,不过如果使用条件传送指令去实现这段代码的话,将可能引起空指针引用的错误。因为条件传送指令会先对两个表达式进行计算,也就是说无论xp是否有值,都将计算*xp这个表达式,因此当xp为空指针0时,则会产生错误。由此可见,条件传送指令也不是哪都能用的,通常情况下,编译器会帮我们尽力处理这种错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号