地图点聚合优化方案
http://www.cnblogs.com/LBSer/p/4417127.html
一、为什么需要点聚合
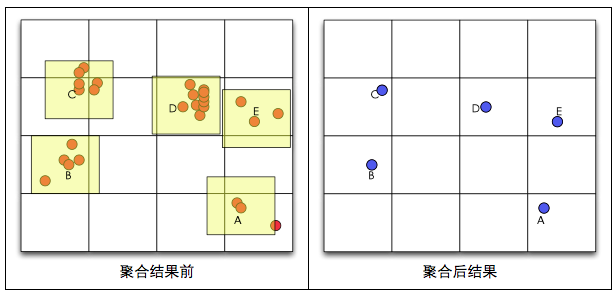
在地图上查询结果通常以标记点的形式展现,但是如果标记点较多,不仅会大大增加客户端的渲染时间,让客户端变得很卡,而且会让人产生密集恐惧症(图1)。为了解决这一问题,我们需要一种手段能在用户有限的可视区域范围内,利用最小的区域展示出最全面的信息,而又不产生重叠覆盖。
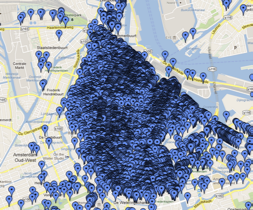
图1
二、已尝试的方案---kmeans
直觉上用聚类算法能较好达成我们目标,因此采用简单的kmeans聚类。根据客户端的请求,我们知道了客户端显示的范围,并到索引引擎里取出在此范围内的数据,并对这些数据进行kmeans聚类,最后将结果返回给客户端。
但是上线之后发现kmeans效果并不如意,主要有以下两个缺点。
a)性能问题
kmeans是计算密集型算法,需要迭代多次才能完成,而且每次迭代过程中都涉及到复杂的距离计算,比较消耗cpu。
我们在上线后遇到load较高的问题。
b)效果问题
kmeans未能彻底解决重叠覆盖问题!可以看到有些聚合后的图标会叠合在一起。

三、优化方案
再次回顾我们的目的:我们需要一种手段能在用户有限的可视区域范围内,利用最小的区域展示出最全面的信息,而又不产生重叠覆盖。
3.1. 直接网格法
解决地理空间相关问题时,对空间划分网格这种方法往往屡试不爽。
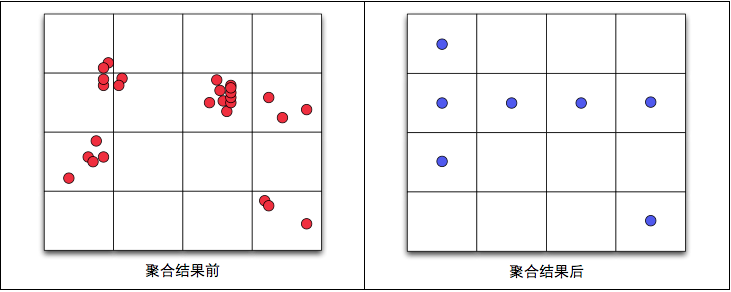
原理:将地图范围划分成指定尺寸的正方形(每个缩放级别不同尺寸),然后将落在对应格子中的点聚合到该正方形中(正方形的中心),最终一个正方形内只显示一个中心点,并且点上显示该聚合点所包含的原始点的数量。
如何将点落到正方形内呢?我们将空间人为指定100*100大小,通过这个公式进行映射。
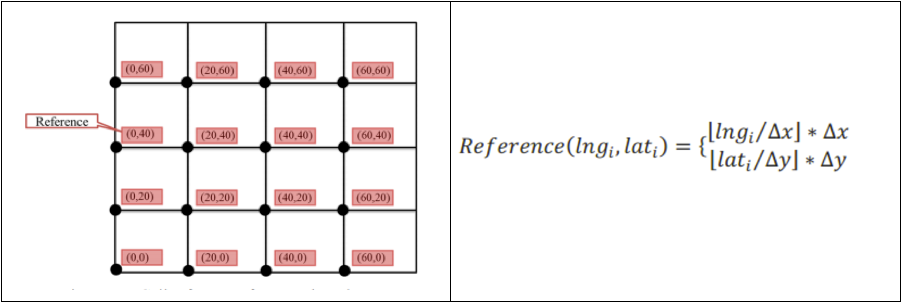
优点:运算速度较快,每个原始点只需计算一次,没有复杂的距离计算。
缺点:有时明明很相近的点,却仅仅因为网络的分界线而被逼分开在不同的聚合点中,此外,聚合点的位置采用的是该网格的中心,而非该网格的质心,这样聚合出来的点可能不能较精确反映原始点的信息。
3.2. 网格距离法
原理:沿用方案一思想,1)将各个点落到相应正方形内;2)求解各个网格的质心;3)合并质心:判断各个质心是否在某一范围内,如果在某一范围内则进行合并。
如何判断各个质心点是否需要合并呢?以A点为例,画一个矩形或者圆范围,落在此范围内的合并,B、C均落在范围内,因此A、B、C三点合并。
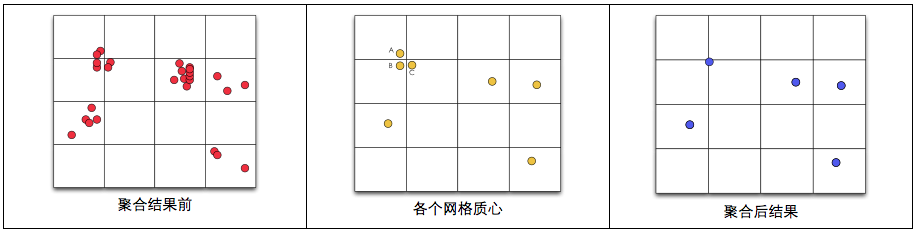
优点:运算速度同样较快,相对于方案一,多了求解质心以及质心合并两个步骤,但这两个步骤都较为简单,能很快完成。
3.3. 直接距离法
原理:初始时没有任何已知聚合点,然后对每个点进行迭代,计算一个点的外包正方形,若此点的外包正方形与现有的聚合点的外包正方形不相交,则新建聚合点(这里不是计算点与点间的距离,而是计算一个点的外包正方形,正方形的变长由用户指定或程序设置一个默认值),若相交,则把该点聚合到该聚合点中,若点与多个已知的聚合点的外包正方形相交,则计算该点到到聚合点的距离,聚合到距离最近的聚合点中,如此循环,直到所有点都遍历完毕。每个缩放级别都重新遍历所有原始点要素。
优点:运算速度相对较快,每个原始点只需计算一次,可能会有点与点距离计算,聚合点较精确的反映了所包含的原始点要素的位置信息。
缺点:速度不如完全基于网格的速度快等,此法还有个缺点,就是各个点迭代顺序不同导致最终结果不同。因此涉及到制定迭代顺序的问题。
3.4. K-D树方法
这种方法需要结合PCA(主成分分析)和K-D树,在效果上比较好,但是性能较差,实现也较为复杂。

(http://applidium.com/en/news/too_many_pins_on_your_map/)
参考文献
https://developers.google.com/maps/articles/toomanymarkers
http://applidium.com/en/news/too_many_pins_on_your_map/
基于百度地图的标记点聚合算法研究

 浙公网安备 33010602011771号
浙公网安备 33010602011771号