

七Dubbo各模块的层次核心接口及组件类--4Cluster层-4.2LoadBalance
七Dubbo各模块的层次核心接口及组件类--4Cluster层-4.2LoadBalance(待完善)
7.4.4 LoadBalance
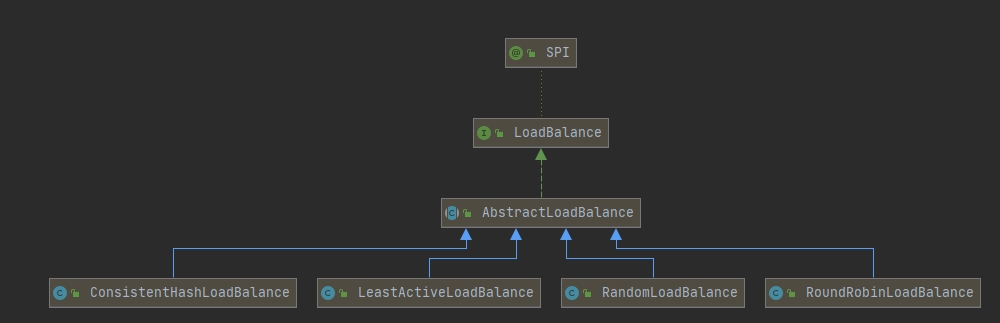
7.4.4.1 RandomLoadBalance
基于权重随机算法的 RandomLoadBalance
7.4.4.2 RoundRobinLoadBalance
基于平滑加权轮询的RoundRobinLoadBalance(参考自 Nginx 的平滑加权轮询负载均衡)
7.4.4.3 LeastActiveLoadBalance
基于最少活跃调用数算法的 LeastActiveLoadBalance
7.4.4.4 ConsistentHashLoadBalance
基于 hash 一致性的 ConsistentHashLoadBalance。
1 Hash算法及原理
1)简介
(1)hash算法
任意输入————hash散列算法——》散列值(是个固定长度输出)
由于散列值是个固定长度输出,输出空间小于输入空间。
注意:
不同输入可能相同输出,不能从散列值来唯一地确定输入值
原理:
以关键码值K为自变量,通过一定的函数关系h(K)(称为散列函数),计算出对应的函数值来,把这个值解释为结点的存储地址,将结点存入到此存储单元中。检索时,用同样的方法计算地址,然后到相应的单元里去取要找的结点。通过散列方法可以对结点进行快速检索。散列(hash,也称“哈希”)是一种重要的存储方式,也是一种常见的检索方法。
(2)哈希表(hash table)
根据hash(key)函数+处理冲突方法,将一组关键字映射到有限地址区间上,以关键字在地址区间中的象作为表中的存储位置(亦成为hash地址),这种表称为hash表。
哈希表是一种“空间换时间”的处理方法。
散列表的存储空间是一个一维数组HT[M],散列地址是数组的下标。设计散列方法的目标,就是设计某个散列函数h,0<=h( K ) < M;对于关键码值K,得到HT[i] = K。 在一般情况下,散列表的空间必须比结点的集合大,此时虽然浪费了一定的空间,但换取的是检索效率。
设散列表的空间大小为M,填入表中的结点数为N,则称为散列表的负载因子(load factor,也有人翻译为“装填因子”)。
建立散列表时,若关键码与散列地址是一对一的关系,则在检索时只需根据散列函数对给定值进行某种运算,即可得到待查结点的存储位置。
但是,散列函数可能对于不相等的关键码计算出相同的散列地址,我们称该现象为冲突(collision),发生冲突的两个关键码称为该散列函数的同义词。
因此,针对哈希表,需要研究两个问题——散列函数和冲突解决方案。
hash用于身份验证、数组签名等场景,也称为“信息摘要”——message Digest-MD
总结:
(1)单向特征
hash是散列函数,单向密码体制,是将明文转化为密文的,且不可逆映射,只能加密,不能解密
(2)固定长度
任意长度————hash——>固定长度
两个特征,使其能够生成消息或者数据。
2)散列函数
在以下的讨论中,我们假设处理的是值为整型的关键码,否则我们总可以建立一种关键码与正整数之间的一一对应关系,从而把该关键码的检索转化为对与其对应的正整数的检索;同时,进一步假定散列函数的值落在0到M-1之间。散列函数的选取原则是:运算尽可能简单;函数的值域必须在散列表的范围内;尽可能使得结点均匀分布,也就是尽量让不同的关键码具有不同的散列函数值。需要考虑各种因素:关键码长度、散列表大小、关键码分布情况、记录的检索频率等等。下面我们介绍几种常用的散列函数。
1.除余法
顾名思义,除余法就是用关键码X除以M(往往取散列表长度),并取余数作为散列地址。除余法几乎是最简单的散列方法,散列函数为: h(x) = x mod M。
2.乘余取整法
使用此方法时,先让关键码key乘上一个常数A (0< A < 1),提取乘积的小数部分。然后,再用整数n乘以这个值,对结果向下取整,把它做为散列的地址。散列函数为: hash ( key ) = _LOW( n × ( A × key % 1 ) )。 其中,“A × key % 1”表示取 A × key 小数部分,即: A × key % 1 = A × key - _LOW(A × key), 而_LOW(X)是表示对X取下整
3.平方取中法
由于整数相除的运行速度通常比相乘要慢,所以有意识地避免使用除余法运算可以提高散列算法的运行时间。平方取中法的具体实现是:先通过求关键码的平方值,从而扩大相近数的差别,然后根据表长度取中间的几位数(往往取二进制的比特位)作为散列函数值。因为一个乘积的中间几位数与乘数的每一数位都相关,所以由此产生的散列地址较为均匀。
| 关键字 | 关键字的平方 | 哈希函数值 |
|---|---|---|
| 1234 | 1522756 | 227 |
| 2143 | 4592449 | 924 |
| 4132 | 17073424 | 734 |
| 3214 | 10329796 | 297 |
4.数字分析法
假设关键字集合中的每个关键字都是由 s 位数字组成 (u1, u2, …, us),分析关键字集中的全体,并从中提取分布均匀的若干位或它们的组合作为地址。数字分析法是取数据元素关键字中某些取值较均匀的数字位作为哈希地址的方法。即当关键字的位数很多时,可以通过对关键字的各位进行分析,丢掉分布不均匀的位,作为哈希值。它只适合于所有关键字值已知的情况。通过分析分布情况把关键字取值区间转化为一个较小的关键字取值区间。
举个例子:要构造一个数据元素个数n=80,哈希长度m=100的哈希表。不失一般性,我们这里只给出其中8个关键字进行分析,8个关键字如下所示:
K1=61317602 K2=61326875 K3=62739628 K4=61343634
K5=62706815 K6=62774638 K7=61381262 K8=61394220
分析上述8个关键字可知,关键字从左到右的第1、2、3、6位取值比较集中,不宜作为哈希地址,剩余的第4、5、7、8位取值较均匀,可选取其中的两位作为哈希地址。设选取最后两位作为哈希地址,则这8个关键字的哈希地址分别为:2,75,28,34,15,38,62,20。
此法适于:能预先估计出全体关键字的每一位上各种数字出现的频度。
5.基数转换法
将关键码值看成另一种进制的数再转换成原来进制的数,然后选其中几位作为散列地址。
例Hash(80127429)=(80127429)13=8137+0136+1135+2134+7133+4132+2*131+9=(502432641)10如果取中间三位作为哈希值,得Hash(80127429)=432
为了获得良好的哈希函数,可以将几种方法联合起来使用,比如先变基,再折叠或平方取中等等,只要散列均匀,就可以随意拼凑。
6.折叠法
有时关键码所含的位数很多,采用平方取中法计算太复杂,则可将关键码分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为散列地址,这方法称为折叠法。
分为:
- 移位叠加:将分割后的几部分低位对齐相加。
- 边界叠加:从一端沿分割界来回折叠,然后对齐相加。
7 混合hash
混合Hash算法利用了以上各种方式。各种常见的Hash算法,比如MD5、Tiger都属于这个范围。它们一般很少在面向查找的Hash函数里面使用。
3)冲突解决
冲突主要取决于:
(1)散列函数,一个好的散列函数的值应尽可能平均分布。
(2)处理冲突方法。
(3)负载因子的大小。太大不一定就好,而且浪费空间严重,负载因子和散列函数是联动的。
尽管散列函数的目标是使得冲突最少,但实际上冲突是无法避免的。因此,我们必须研究冲突解决策略。冲突解决技术可以分为两类:开散列方法( open hashing,也称为拉链法,separate chaining )和闭散列方法( closed hashing,也称为开地址方法,open addressing )。这两种方法的不同之处在于:开散列法把发生冲突的关键码存储在散列表主表之外,而闭散列法把发生冲突的关键码存储在表中另一个槽内
1.分离链表法——开散列方法
(1)拉链法
开散列方法的一种简单形式是把散列表中的每个槽定义为一个链表的表头。散列到一个特定槽的所有记录都放到这个槽的链表中。图9-5说明了一个开散列的散列表,这个表中每一个槽存储一个记录和一个指向链表其余部分的指针。这7个数存储在有11个槽的散列表中,使用的散列函数是h(K) = K mod 11。数的插入顺序是77、7、110、95、14、75和62。有2个值散列到第0个槽,1个值散列到第3个槽,3个值散列到第7个槽,1个值散列到第9个槽
2.闭散列方法(开放地址法)
闭散列方法把所有记录直接存储在散列表中。每个记录关键码key有一个由散列函数计算出来的基位置,即h(key)。如果要插入一个关键码,而另一个记录已经占据了R的基位置(发生碰撞),那么就把R存储在表中的其它地址内,由冲突解决策略确定是哪个地址。
闭散列表解决冲突的基本思想是:当冲突发生时,使用某种方法为关键码K生成一个散列地址序列d0,d1,d2,... di ,...dm-1。其中d0=h(K)称为K的基地址地置( home position );所有di(0< i< m)是后继散列地址。当插入K时,若基地址上的结点已被别的数据元素占用,则按上述地址序列依次探查,将找到的第一个开放的空闲位置di作为K的存储位置;若所有后继散列地址都不空闲,说明该闭散列表已满,报告溢出。相应地,检索K时,将按同值的后继地址序列依次查找,检索成功时返回该位置di ;如果沿着探查序列检索时,遇到了开放的空闲地址,则说明表中没有待查的关键码。删除K时,也按同值的后继地址序列依次查找,查找到某个位置di具有该K值,则删除该位置di上的数据元素(删除操作实际上只是对该结点加以删除标记);如果遇到了开放的空闲地址,则说明表中没有待删除的关键码。因此,对于闭散列表来说,构造后继散列地址序列的方法,也就是处理冲突的方法。
形成探查的方法不同,所得到的解决冲突的方法也不同。下面是几种常见的构造方法
(1)线性探测法
将散列表看成是一个环形表,若在基地址d(即h(K)=d)发生冲突,则依次探查下述地址单元:d+1,d+2,......,M-1,0,1,......,d-1直到找到一个空闲地址或查找到关键码为key的结点为止。当然,若沿着该探查序列检索一遍之后,又回到了地址d,则无论是做插入操作还是做检索操作,都意味着失败。 用于简单线性探查的探查函数是: p(K,i) = i
例9.7 已知一组关键码为(26,36,41,38,44,15,68,12,06,51,25),散列表长度M= 15,用线性探查法解决冲突构造这组关键码的散列表。 因为n=11,利用除余法构造散列函数,选取小于M的最大质数P=13,则散列函数为:h(key) = key%13。按顺序插入各个结点: 26: h(26) = 0,36: h(36) = 10, 41: h(41) = 2,38: h(38) = 12, 44: h(44) = 5。 插入15时,其散列地址为2,由于2已被关键码为41的元素占用,故需进行探查。按顺序探查法,显然3为开放的空闲地址,故可将其放在3单元。类似地,68和12可分别放在4和13单元中.
(2)二次探查法
(3)随机探查法
(4)双散列探查法
4)查找的性能分析
散列表的查找过程基本上和造表过程相同。一些关键码可通过散列函数转换的地址直接找到,另一些关键码在散列函数得到的地址上产生了冲突,需要按处理冲突的方法进行查找。在介绍的三种处理冲突的方法中,产生冲突后的查找仍然是给定值与关键码进行比较的过程。所以,对散列表查找效率的量度,依然用平均查找长度来衡量。
查找过程中,关键码的比较次数,取决于产生冲突的多少,产生的冲突少,查找效率就高,产生的冲突多,查找效率就低。因此,影响产生冲突多少的因素,也就是影响查找效率的因素。影响产生冲突多少有以下三个因素:
1. 散列函数是否均匀;
2. 处理冲突的方法;
3. 散列表的装填因子。
散列表的装填因子定义为:α= 填入表中的元素个数 / 散列表的长度
α是散列表装满程度的标志因子。由于表长是定值,α与“填入表中的元素个数”成正比,所以,α越大,填入表中的元素较多,产生冲突的可能性就越大;α越小,填入表中的元素较少,产生冲突的可能性就越小。
实际上,散列表的平均查找长度是装填因子α的函数,只是不同处理冲突的方法有不同的函数。
5)著名的hash算法
(1) MD4
MD4(RFC 1320)是 MIT 的 Ronald L. Rivest 在 1990 年设计的,MD 是 Message Digest 的缩写。它适用在32位字长的处理器上用高速软件实现--它是基于 32 位操作数的位操作来实现的。
(2) MD5
MD5(RFC 1321)是 Rivest 于1991年对MD4的改进版本。它对输入仍以512位分组,其输出是4个32位字的级联,与 MD4 相同。MD5比MD4来得复杂,并且速度较之要慢一点,但更安全,在抗分析和抗差分方面表现更好
(3) SHA-1 及其他
SHA1是由NIST NSA设计为同DSA一起使用的,它对长度小于264的输入,产生长度为160bit的散列值,因此抗穷举(brute-force)性更好。SHA-1 设计时基于和MD4相同原理,并且模仿了该算法。
6)hash算法运用场景
(1) 文件校验
我们比较熟悉的校验算法有奇偶校验和CRC校验,这2种校验并没有抗数据篡改的能力,它们一定程度上能检测并纠正数据传输中的信道误码,但却不能防止对数据的恶意破坏。
MD5 Hash算法的“数字指纹”特性,使它成为目前应用最广泛的一种文件完整性校验和(Checksum)算法,不少Unix系统有提供计算md5 checksum的命令。
(2) 数字签名
Hash 算法也是现代密码体系中的一个重要组成部分。由于非对称算法的运算速度较慢,所以在数字签名协议中,单向散列函数扮演了一个重要的角色。 对 Hash 值,又称“数字摘要”进行数字签名,在统计上可以认为与对文件本身进行数字签名是等效的。而且这样的协议还有其他的优点。
(3) 鉴权协议
如下的鉴权协议又被称作挑战--认证模式:在传输信道是可被侦听,但不可被篡改的情况下,这是一种简单而安全的方法。
2 hashmap的实现
public class MyHashMap<K, V> implements Map<K, V> {
private class Node {
private MyEntry<K, V> entry = null;
public Node next = null;
}
class MyEntry<K, V> implements Entry<K, V> {
private int hash;
private K key;
private V value;
}
//常量区
private static final double LOAD_FACTOR = 0.75; //负载因子阈值
private static final int INITIAL_SIZE = 16; //数组初始大小
//成员变量区
private int element_count = 0; //当前元素计数
private Node[] node_list = (Node[]) Array.newInstance(Node.class, INITIAL_SIZE); //存储数组。
//略去Map列表的实现方法
}
(1)对于k-v键值对存入hashmap中,哈希值获取采用k.hashcode()方法获取,然后需要散列对应到hashmap上的数组位置上
根据将取模运算比位于运算快5--8倍,有如下算法:
k % 2^n = k & (2^n - 1)
任意数对2的N次方取模时,等同于其和2的N次方-1作位于运算。
负载因子
负载因子是哈希表的重要参数,其定义为:哈希表中已存有的元素与哈希表长度的比值。
它是一个浮点数,表示哈希表目前的装满程度。由于表长是定值,而表中元素的个数越大,表中空余位置就会更少,发生碰撞的可能性也会进一步增大。
哈希表的扩容策略依赖于负载因子阈值。基于性能与空间的选择,JDK标准库将HashMap的负载因子阈值定为0.75。
(2)hashmap结构:
采用2的幂次的数组空间,数组中存储的是node节点。hashmap采用拉链法解决哈希冲突,因此Node[]数组中每个位置后面是一个链表(jdk1.8后是红黑树实现,加快索引)。链表节点为node,node内存储了Map.Entry<k,v>,用来存储实际的k-v键值对信息。
(3)Hash表的核心操作就是通过对key值的计算直接查找目标元素下标,因此我们首先参考标准库编写(fuzhi)出getIndex方法:
private int getIndex( int hash, int mod ){
return (hash & 0x7fffffff) & (mod - 1);
}
(hash & 0x7fffffff)是为了确保结果为正数。
为什么要对0x7fffffff做位于操作?
0x7fffffff是int可以表达的最大正整数,除了首位为0其他31位都为1。正数& 0x7fffffff结果为其本身,负数& 0x7fffffff结果为正数。
(4) 其中,创建node节点的数组结构,使用如下方法:
private Node[] node_list = (Node[]) Array.newInstance(Node.class, INITIAL_SIZE)
Java中并不支持直接申请泛型类的数组。只能通过Array.newInstance静态方法构造数组并强制转换为泛型类的数组。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号