计算机基础与编程环境
计算机的基本构成
根据大纲可以猜测计算机由CPU、内存、IO设备等构成
参考资料
计算机由软件和硬件构成
硬件里面有中央处理器,也就是我们常说的CPU,这里面有算术逻辑运算器ALU和控制器CU
硬件还有其他三部分,分别是存储器,输入设备和输出设备
其中存储器分为内存储器和外存储器,外存储器就是磁盘啊光盘啊之类的可以拆掉的。内存储器应该是刻在主板上的,所以我们电脑的内存是4G(对我的配置低),就是内存储器的最大容量只有4G,你使劲给他装硬盘只是增加外存储器而已,还不如清理一下缓存/擦汗
内存储器也分为随机存取存储器RAM和只读存储器ROM
RAM也叫主存,是直接和CPU交换数据的内部存储器,速度极快,通常作为临时存储数据的地方,很快很快,但是断电就数据全没了
ROM,顾名思义,Read-Only Memory,只能读出无法写入,就算断电数据也还在(根本不用修改怎么不在)通常是装入整机之前写入数据,用来存储各种固定的程序和数据
还有一个小小的(真的很小)寄存器register就在CPU旁边,运算速度极高,所以很多程序猿在for的时候喜欢用register来定义,那么register究竟有多小呢?我不知道我只知道我曾经for全用register 直接WA,去掉就好了
至于输入输出设备,很多啦,像什么键盘鼠标扫描仪打印机都是
PS:打印机是输出设备,至于你能用打印机扫描之类的,是因为你的打印机上装了扫描仪
软件方面,首先就是系统软件,就要有操作系统,比如DOS,windoes,Linux之类的
然后就要语言处理程序,系统之用程序,数据库管理系统。。。反正进C盘什么都能看见了
最后软件还有你自己安装的软件,电脑原配程序库。
在计算机中数据是用二进制存储的,首先程序的数据通过输入设备到达储存器,然后控制器控制运算器从存储器中获取数据并运算,然后把运算结果放回存储器,随后通过输出设备输出。
Windows/Linux等操作系统的基本概念及其常见操作
我怎么知道什么基本概念随便水一下算了
参考资料
operating system,os,就是操作系统,所以Python里面可以看见
from os import system
(别问我为什么突然将进程)
进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。
进程的概念主要有两点:(from百度百科)
第一,进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据区域(data region)和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。
第二,进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程。
动态性:进程的实质是程序在多道程序系统中的一次执行过程,进程是动态产生,动态消亡的。
并发性:任何进程都可以同其他进程一起并发执行
独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位;
异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进
结构特征:进程由程序、数据和进程控制块三部分组成。
多个不同的进程可以包含相同的程序:一个程序在不同的数据集里就构成不同的进程,能得到不同的结果;但是执行过程中,程序不能发生改变。
而线程呢,是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
我们需要区分“并发”和“并行”两个概念,并行是指两件事在同一时刻同时发生,并发是指两件事在时间内间隔发生,(当然也可以不只两件事)
比如事件A:清空屏幕并在屏幕第一行第一列输出1
事件B:清空屏幕并在屏幕第一行第二列输出2
不断执行事件A,B
如果是并行,那么就
while(true)
{
// 一开始就是空的直接回到行首输出
cout << "\r12";
}
如果是并行,那么就
while(true)
{
// 因为需要快的效果所以用fwrite输出
fwrite("\r1 ",1,3,stdout);
fwrite("\r 2",1,3,stdout);
}
多线程就是采用并行的方法运行的,你看着它同时处理很爽哦,其实他是分开处理的,先做一下这个,然后做一下那个,再回来做一下这个……至于这一下……就短到你认为他是在一起做的
比如上面那个并行的例子图像在视网膜上残留(?)的时间约为100~400ms(百度说的),那么我只要10ms来执行A,10ms执行B,那么在前100ms内我是交错分别执行了5次A和5次B,这样你的眼睛看上去就是同时输出了12
但是如果我加上Sleep(1000)指令,也就是我需要1010ms来执行A,1010ms来执行B,那么停留时间内就会有全部都是1或者全部都是2的时候,你才会觉得他是分开执行的
所以计算机这一下是极短的,才能让我一边听歌一边水文章
然后共享,系统中的资源可以供多个并发的进程共同使用
分为互斥共享和同时共享,互斥就是一个时刻只能一个进程访问即进程们是轮流访问资源的,共享是多个进程同时访问资源(跟并发和并行的关系差不多)
虚拟:把一个物理上的实体变为若干个逻辑上的对应物。物理实体是实际存在的,而逻辑上对应物是用户感受到的。
虚拟技术中的时分复用技术。微观上处理机在各个微小的时间段内交替着为各个进程服务。
异步:在多道环境程序下,允许多个程序并发执行,但由于资源有限,进程的执行不是一贯到底的,而是走走停停的,以不可预知的速度向前推进,这就是进程的异步性。
(然而好像没什么用)
系统调用,是操作系统提供给应用程序使用的接口。
比如你的打印机是操作系统的话,进程要通过系统调用才能使用打印机,你通过系统调用向打印机传入你的论文,然后打印机再打印出你的论文。
如果你打印到一半,同学也通过系统调用向打印机传入他的照片,那么打印机知道要打印照片,但是一定要等打印完论文先再打印照片。这就是系统调用,相当于在用户态给系统一个指令,实际处理指令的是核心态(就是你的打印机)
操作系统的运行环境
运行机制
操作系统的运行机制有两种指令、两种处理器状态和两种程序
两种处理器状态就是用户态(目态)和核心态(管态),上面说过用户态是给用户调用的,核心态才是处理器真正处理指令的状态。通过程序状态字寄存器(PSW)的某个位来表示当前处理器的状态。比如0是目态,1是管态
那么肯定了,用户是不可以执行某些指令,比如说把所有内存清零。如果你正在打印你的论文,突然同学来把内存清零了,那么你的论文……节哀。但是在核心态是肯定会执行内存清零这样的指令的,你敲题目的时候也难免会用到memset,虽然memset也是用户态,但是底层他调用核心态的“清空内存”,这些就是核心态才能用的特权指令。相对的,用户态和核心态都能调用的指令就是非特权指令。
所以,可以推得,两种程序就是指内核程序和应用程序。内核程序是系统的管理者,在核心态运行,可以执行所有指令。
而应用程序,就是windows上面的.exe文件(看文件类型就知道了)。就是用户只能调用的程序,只能执行费特权指令,运行在用户态。
操作系统内核
- 时钟管理:实现计时功能
- 中断处理:用来实现中断当前线程去执行其他并发线程的中断机制
- 原语:一种特殊的程序,操作系统最底层,不能中断的程序(原子性),运行时间极短,调用频繁
原语其实就是最底层的程序,原语经过不断包装才能变成我们使用的程序。
比如我们看cout,就是一个ofstream类型的变量,指向了stdout(其实stdout应该是FILE类型的但我不管反正就是表示stdout),然后我们使用cout输出的时候是调用经过包装后的左移运算符。即
int a;
cout << a;
的时候我们其实是调用
int a;
<< (cout,a);
而这里重载的左移运算符的函数定义应该是:
ofstream* operator << (ofstream*, int);
至于实现……不知道
所以我们以后就可以
struct pair
{
int first, second
};
ofstream* operator << (ofstream* ofile, const pair dat)
{
ofile << first << second;
return ofile;
}
就可以直接用cout来输出一个pair类型的变量
这里我就用系统提供的oftream* operator << (ofstream, int)包装成了ofstream operator << (ofstream, pair)函数。
同理oftream operator << (ofstream*, int)也是通过底层函数包装来实现的
底层函数又是通过更底层函数包装来时限的……
……
一直到最底层,就是原语,到了原语级别程序极度精简,因为原语不允许中断。
我的输出函数可以先输出了first,中断一下,执行其他,再回来输出second(只要其他不会干扰我的输出结果),这样是可以的。因为我的函数很清晰是分成两个底层函数来执行,这两个函数是并发的,是可以断开执行的。但是这样分下去总要有个递归边界,就是原语
然后内核还有对系统资源进行管理的功能,包括进程管理、存储器管理、设备管理等
内核体系结构
-
大内核
把操作系统的大部分功能都写进内核里面,在核心态运行(就是内核管大部分的事)
优点:封装函数的层数较少,迭代比较少次就能达到原语级别,性能较高。
缺点:内核代码庞大,结构混乱,难以维护 -
微内核
只把基本必要的程序留在内核
优点:内核功能少,结构清晰,方便维护。
缺点:迭代次数多,需要频繁在核心态和用户态之间切换,性能低。
举个栗子,如果我要写一个只用来输出的系统,那么基本的必要的程序就是putchar(int),这是我这个系统里面最低级的程序。
如果是微内核,我只需要在内核里实现putchar函数就可以了。到时候维护只需要维护putchar函数就可以了。至于其他的
void write(int x)
{
if(x<0) putchar('-'), write(-x);
if(x>9) write(x/10);
putchar((x%10)^48);
}
之类的函数都是用户态的,用户可以直接调用。但是这样的话如果我们要实现cout就会是
ofstream* operator << (ofstream* ofile, int a)
{
/// 一些玄学操作
write(a);
return ofile;
}
虽然我不知道怎么可以写入到ofile里面,这样你调用了一次左移运算符,然后再带调用write,通过用户态调用的核心程序就必定会更多次(emmm好吧这个栗子体现不出来),是很慢的
如果是大内核,我们就可以把上述出现的所有函数都放入内核里面,这样可以直接在核心态执行程序,不需要判断用户态是否有非法操作(执行特权指令),这样就会快很多,但与此同时整个源程序也会庞大很多,就像你的码量上去之后维护会很艰难/苦笑
计算机网络和Internet基本概念
参考资料
为了使不同计算机厂家生产的计算机能够相互通信,以便在更大的范围内建立计算机网络,国际标准化组织(ISO)在1978年提出了"开放系统互联参考模型",即著名的OSI/RM模型(Open System Interconnection/Reference Model)。它将计算机网络体系结构的通信协议划分为七层,自下而上依次为:物理层(Physics Layer)、数据链路层(Data Link Layer)、网络层(Network Layer)、传输层(Transport Layer)、会话层(Session Layer)、表示层(Presentation Layer)、应用层(Application Layer)。其中第四层(传输层)完成数据传送服务,上面三层面向用户。
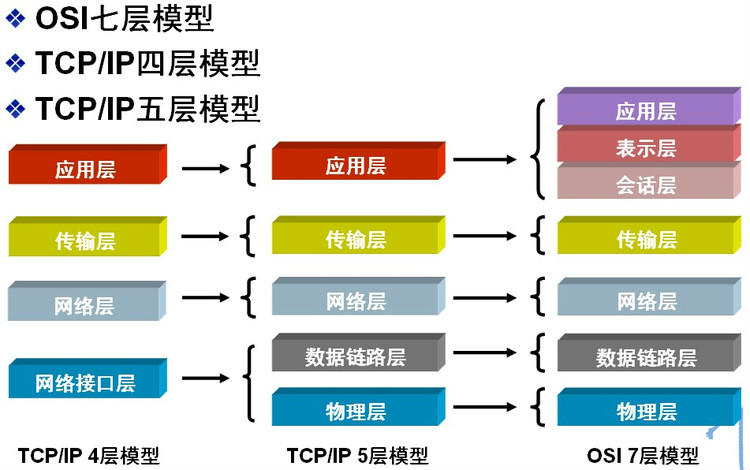
但是即使是这样,全球的计算机可以相互通信了,但是由于各计算机使用的字符集不同,所以有些计算机可能不能很好通信。
这个字符集,可以简单理解为编码。你有没有试过程序输出中文的时候乱码,然后加一句setlocale(LC_ALL,"");就搞定的时候?这就是因为你的中文使用的是utf-8编码,但是控制台默认的chcp 是936,也就是gbk字符集,但是你的utf-8是属于Unicode字符集的,所以就会出现乱码,也就是无法通信。
再举个栗子,我们平时在写代码的时候采用的ASCII码也是一种字符集,但是没有中文所以中文是不能用ASCII来表示的。如果强制用ASCII来显示中文字符的话:
- 首先我们百度搜索“犇”字
- 得到网址https://www.baidu.com/s?wd=%E7%8A%87 (已经去掉好多没用的参数)
- 从中截取“犇”的编码:0xE78A87的六位hex,每位hex是4位bin,8位bin就是1byte,所以每两位hex就是1byte,也就是一个正常的char,所以0xE78A87这个中文字符就可以用三个char 来表示:0xE7, 0x8A, 0x87
然后这些如果转成int就变成了-25,-118, -121,然后如果你再用ascii输出……幸运的话会输出不可见字符,不幸运的话就是乱码
附上测试代码:
#include <bits/stdc++.h>
using namespace std;
int main()
{
setlocale(LC_ALL,"");
wchar_t a = L'犇';
cout << a << endl;
char b[4] = "犇";
cout << (int)b[0] << ' ' << (int)b[1] << ' ' << (int)b[2] << endl;
wprintf(L"%lc",a);
return 0;
}
那么怎么解决计算机采用不同字符集的问题呢?网络协议就出来了。
百度:网络协议为计算机网络中进行数据交换而建立的规则、标准或约定的集合。
在数据链路层主要使用的协议就是以太网协议。从某种意义上讲,以太网就是局域网。
网络层的协议主要有
IP协议(Internet Protocol,因特网互联协议);
ICMP协议(Internet Control Message Protocol,因特网控制报文协议);
ARP协议(Address Resolution Protocol,地址解析协议);
RARP协议(Reverse Address Resolution Protocol,逆地址解析协议)。
在应用层上,又会有FTP(文件传送协议)、Telnet(远程登录协议)、DNS(域名解析协议)、SMTP(邮件传送协议),POP3协议(邮局协议),HTTP协议(Hyper Text Transfer Protocol 超文本传输协议)
IP地址:
参考资料
IPv4是32位IP地址,就是在cmd里面一个ipconfig就能知道的那个。因为32位地址好像不太够用,所以就有IPv6,也就是128位IP地址(肯定够用了)
IP地址分为5类:
D类:地址的32位bin以1110开头,地址范围是224.0.0.0~239.255.255.255,D类地址作为组播地址/多播地址(一对多的通信);
E类:地址以1111开头,地址范围是240.0.0.0~255.255.255.255,E类地址为保留地址,供以后使用。
接下来三类是私有地址:
私有地址属于非注册地址,专门为组织机构内部使用。
私有地址由网络号和主机号组成
前面一些连续位称为网络号,用于表示该设备位于哪个网络,后面的其余位称为主机地址,用于在该网络中唯一标识一台主机。
A类地址以0开头,第一个字节(也就是前八位)作为网络号,地址范围为:0.0.0.0~127.255.255.255
B类地址以10开头,前两个字节作为网络号,地址范围是:128.0.0.0~191.255.255.255;
C类地址以110开头,前三个字节作为网络号,地址范围是:192.0.0.0~223.255.255.255。
但是这样分就会发现,A类地址按网络号分类只有128个网络,但是每个网络可以拥有……好多好多个……个主机
而C类地址恰好反过来,他的网络数远远大于主机数(我才不算呢哼唧)这样就会造成资源效率低下。
所以后来就有人把主机号划分成了子网+主机号
这种方式被称为子网寻址。
子网是从每类的网络地址的主机部分拿出一定数量的位数,用该位数标识子网号,从而将每类的IP网络进一步分成更小的网络。
这样之后A类地址的(子)网络数就会大大提升,然后每个网络对应的主机数就少了。
但是增加了子网之后,我怎么知道从哪里开始是主机号!!!
所以就出来了子网掩码
子网掩码是由一段连续的1和一段连续的0组成的32位bin,把它和IP地址按位与就可以得到网络号
比如子网掩码由30个1和2个0组成,那么对IP地址按位与之后前30位不变,那么这个IP地址的前30位就是网络号(网络地址+子网地址),剩下的两位就是主机号
计算机的历史
???
参考资料(自行观看)
以下是摘抄重点:
第一台真正计算机的出现
帕斯卡发明了人类有史以来第一台机械计算机——帕斯卡加法器。它是一种系列齿轮组成的装置,外形像一个长方盒子,用儿童玩具那种钥匙旋紧发条后才能转动,只能够做加法和减法。然而,即使只做加法,也有个“逢十进一”的进位问题。聪明的帕斯卡采用了一种小爪子式的棘轮装置。当定位齿轮朝9转动时,棘爪便逐渐升高;一旦齿轮转到0,棘爪就“咔嚓”一声跌落下来,推动十位数的齿轮前进一档。
1662年帕斯卡去世,不久后,在德国的大数学家莱布尼茨看到了帕斯卡关于加法计算机的论文,勾引起了他的发明欲。莱布尼茨早年经历坎坷,后来获得了一次去法国的机会,在巴黎的时候,他聘请了一些著名的机械专家和能工巧匠,终于在1674年制造出了一台更完美的机械计算机。
莱布尼茨发明的新型计算机约有1米长,内部安装了一系列齿轮机构,除了体积较大之外,基本原理继承于帕斯卡。不过,莱布尼茨技高一筹,他为计算机增添了一种名叫“步进轮”的装置。步进轮是一个有9个齿的长圆柱体,9个齿依次分布于圆柱表面;旁边另有个小齿轮可以沿着轴向移动,以便逐次与步进轮啮合。每当小齿轮转动一圈,步进轮可根据它与小齿轮啮合的齿数,分别转动1/10、2/10圈……,直到9/10圈,这样一来,它就能够连续重复地做加法。
连续重复的计算加法是现代计算机做乘除法采用的办法,莱布尼茨的计算机加减乘除四则运算一应俱全。
在介绍莱布尼茨的时候还有一个小插曲。(传说大约在1700年左右的某天,莱布尼茨的朋友送给他一副中国的”易图“,其实就是八卦图,在看八卦图的时候,发现八卦的每一种卦象都有阴阳两种符号组成,这不就是有规律的二进制数字么,于是他就由此,率先系统提出了二进制的运算法则,直到今天,我们用到的计算机还是使用的二进制。)

第一台电子计算机:阿塔纳索夫-贝瑞计算机(Atanasoff–Berry Computer,通常简称ABC计算机)在1937年设计,不可编程,仅仅设计用于求解线性方程组,并在1942年成功进行了测试。
第一代电子管计算机(1946~1958):
特点: 操作指令是为特定任务而编制的,每种机器有各自不同的机器语言,功能受到限制,速度也慢。另一个明显特征是使用真空电子管和磁鼓储存数据。
第二代晶体管计算机 (1956-1963):
特点: 晶体管代替了体积庞大电子管,使用磁芯存储器。体积小、速度快、功耗低、性能更稳定。还有现代计算机的一些部件:打印机、磁带、磁盘、内存、操作系统等。在这一时期出现了更高级的COBOL和FORTRAN等编程语言,使计算机编程更容易。新的职业(程序员、分析员和计算机系统专家)和整个软件产业由此诞生。
第三代集成电路计算机 (1964-1971):
以中小规模集成电路,来构成计算机的主要功能部件。主存储器采用半导体存储器。运算速度可达每秒几十万次至几百万次基本运算。在软件方面,操作系统日趋完善。
第四代大规模集成电路计算机 (1971-至今):
从1970年以后采用大规模集成电路(LSI)和超大规模集成电路(VLSI)为主要电子器件制成的计算机,重要分支是以大规模、超大规模集成电路为基础发展起来的微处理器和微型计算机。
敲黑板划重点:
冯·诺依曼:现代计算机之父,发表了著名的“101页报告”。明确规定出计算机的五大部件(输入系统、输出系统、存储器、运算器、控制器),并用二进制替代十进制运算,大大方便了机器的电路设计。
克劳德·艾尔伍德·香农:信息论之父。提出了信息熵的概念,为信息论和数字通信奠定了基础。
艾伦·麦席森·图灵:计算机科学之父,二战破解德军密码。
计算机在现代社会的常见应用……用常识吧帮不了你了
NOI以及相关活动的历史
接下来开启……快速模式?
进制
就是逢几进1啦……最低就是二进制。可以类比成算盘,如果是n进制,那么从右向左数第i位是j就表示有j个
比如 就表示
一般用b表示二进制binary,o代表八进制octonary,x代表十六进制hexadecimal,d表示十进制decimal,计算机中0b开头的就是二进制,0x开头的就是16进制。
进制转换
可以用十进制作为跳板先把i进制转换为10进制,然后再用短除法通过余数得到j进制
如果是负数二进制,好有道理的资料,就用补码存储。
反码:就是源码取反,c++里面有个位运算符~(小波浪)就是取反,
那么计算机储存的是~2的补码(因为是负数)
补码转回十进制,首先就要求得反码,就是
反码知道是个负数,那么负数二进制转十进制,取反再加一,再加个负号
所以~2,取反再加一就是3,加负号,就是-3
储存空间大小
bit:位(比特),最基本的储存单位,只能表示0/1
byte:字节,一字节有八位
Kb:千字节,这里千是约数,确切数是1024,1Kb=1024byte
Mb:兆字节,1024Kb
Gb:千兆字节,1024Mb
Tb:太字节,1024Gb
Pb:拍字节,1024Tb
Eb:艾字节,1024Pb
程序编译运行基本概念
1.预处理
此阶段主要完成#符号后面的各项内容到源文件的替换,往往一些莫名其妙的错误都是出现在头文件中的,要在工程中注意积累一些错误知识。
(1)、#ifdef等内容,完成条件编译内容的替换
(2)、#include中内容,在当前目录或者指定目录,或者默认目录搜索头文件,并将头文件拷贝到源文件中。
(3)、#define的内容,替换define的内容(包括上一步的头文件中的define内容)
此阶段产生[.i]文件。
而你自己写的代码就在文件的最后
2.编译
此阶段完成语法和语义分析,然后生成中间代码,此中间代码是汇编代码,但是还不可执行,gcc编译的中间文件是[.s]文件。
在此阶段会出现各种语法和语义错误,特别要小心未定义的行为,这往往是致命的错误。
第一个阶段和第二个阶段由编译器完成。
3.汇编
此阶段主要完成将汇编代码翻译成机器码指令,并将这些指令打包形成可重定位的目标文件,[.O]文件,是二进制文件。
此阶段由汇编器完成。
4.链接
此阶段完成文件中调用的各种函数跟静态库和动态库的连接,并将它们一起打包合并形成目标文件,即可执行文件。
此阶段由链接器完成。
gcc编译C语言主要用到以下几个程序:C编译器gcc、汇编器as、链接器ld和二进制转换工具objcopy。
g++ [选项] 要编译的文件 [选项] [目标文件]
其中,目标文件可缺省,gcc默认生成可执行的文件名为:a.out
g++ main.cpp 直接生成可执行文件a.exe
g++ main.cpp -o main.exe 生成main.exe可执行文件
g++ -E main.cpp -o main.i 生成预处理后的代码(还是文本文件)
g++ –S main.i -o main.s 生成汇编代码(已经看不懂了)
g++ main.s -o main.exe 生成目标代码(exe文件)



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 在鹅厂做java开发是什么体验
· 百万级群聊的设计实践
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
· 永远不要相信用户的输入:从 SQL 注入攻防看输入验证的重要性
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析