MAPPO学习笔记(3)——从MAPPO代码入手
写在前面:
在经过了漫长时间的焦头烂额之后,很多事情总算告一段落,于是便有时间继续分享自己的拙见。当然,MAPPO这一块的研究内容,甚至于MARL这一块的内容尚不完善,各位看官还请带着批判性的眼光一起学习。
在上一篇博客中,我推荐过两个MAPPO项目:
官方代码:https://github.com/marlbenchmark/on-policy/tree/main/onpolicy
轻量版代码:https://github.com/tinyzqh/light_mappo
本想偷懒介绍轻量版的代码,但看到网上亦有许多大佬对官方代码进行果令人叹为观止的解读,深感佩服之余不禁在想,和尚碰得,为何我碰不得。遂在本篇对官方代码进行解读,方便大家理解,一起学习。
轻量版代码将在下一篇:MAPPO学习笔记(4)——应用篇 进行介绍。
1.代码结构
项目构成如下所示(我们只看与算法有关的algorithms文件下的内容):

r_mappo下的algorithm的两个文件,分别是网络结构与策略。r_mappo.py文件中则包含了策略更新等方法,r_actor_critic.py会在rMAPPOPolicy.py中被调用,而rMAPPOPolicy则会作为参数“Policy”,传递给r_mappo.py中的R_MAPPO()。
2.文件内容详解
我们按照层级顺序,从下到上来看。
2.1 r_actor_critic.py
先把代码摆在这(代码较长,酌情打开):
点击查看代码
import torch
import torch.nn as nn
from onpolicy.algorithms.utils.util import init, check
from onpolicy.algorithms.utils.cnn import CNNBase
from onpolicy.algorithms.utils.mlp import MLPBase
from onpolicy.algorithms.utils.rnn import RNNLayer
from onpolicy.algorithms.utils.act import ACTLayer
from onpolicy.algorithms.utils.popart import PopArt
from onpolicy.utils.util import get_shape_from_obs_space
class R_Actor(nn.Module):
"""
Actor network class for MAPPO. Outputs actions given observations.
:param args: (argparse.Namespace) arguments containing relevant model information.
:param obs_space: (gym.Space) observation space.
:param action_space: (gym.Space) action space.
:param device: (torch.device) specifies the device to run on (cpu/gpu).
"""
def __init__(self, args, obs_space, action_space, device=torch.device("cpu")):
super(R_Actor, self).__init__()
self.hidden_size = args.hidden_size
self._gain = args.gain
self._use_orthogonal = args.use_orthogonal
self._use_policy_active_masks = args.use_policy_active_masks
self._use_naive_recurrent_policy = args.use_naive_recurrent_policy
self._use_recurrent_policy = args.use_recurrent_policy
self._recurrent_N = args.recurrent_N
self.tpdv = dict(dtype=torch.float32, device=device)
obs_shape = get_shape_from_obs_space(obs_space)
base = CNNBase if len(obs_shape) == 3 else MLPBase
self.base = base(args, obs_shape)
if self._use_naive_recurrent_policy or self._use_recurrent_policy:
self.rnn = RNNLayer(self.hidden_size, self.hidden_size, self._recurrent_N, self._use_orthogonal)
self.act = ACTLayer(action_space, self.hidden_size, self._use_orthogonal, self._gain, args)
self.to(device)
self.algo = args.algorithm_name
def forward(self, obs, rnn_states, masks, available_actions=None, deterministic=False):
"""
Compute actions from the given inputs.
:param obs: (np.ndarray / torch.Tensor) observation inputs into network.
:param rnn_states: (np.ndarray / torch.Tensor) if RNN network, hidden states for RNN.
:param masks: (np.ndarray / torch.Tensor) mask tensor denoting if hidden states should be reinitialized to zeros.
:param available_actions: (np.ndarray / torch.Tensor) denotes which actions are available to agent
(if None, all actions available)
:param deterministic: (bool) whether to sample from action distribution or return the mode.
:return actions: (torch.Tensor) actions to take.
:return action_log_probs: (torch.Tensor) log probabilities of taken actions.
:return rnn_states: (torch.Tensor) updated RNN hidden states.
"""
obs = check(obs).to(**self.tpdv)
rnn_states = check(rnn_states).to(**self.tpdv)
masks = check(masks).to(**self.tpdv)
if available_actions is not None:
available_actions = check(available_actions).to(**self.tpdv)
actor_features = self.base(obs)
if self._use_naive_recurrent_policy or self._use_recurrent_policy:
actor_features, rnn_states = self.rnn(actor_features, rnn_states, masks)
actions, action_log_probs = self.act(actor_features, available_actions, deterministic)
return actions, action_log_probs, rnn_states
def evaluate_actions(self, obs, rnn_states, action, masks, available_actions=None, active_masks=None):
"""
Compute log probability and entropy of given actions.
:param obs: (torch.Tensor) observation inputs into network.
:param action: (torch.Tensor) actions whose entropy and log probability to evaluate.
:param rnn_states: (torch.Tensor) if RNN network, hidden states for RNN.
:param masks: (torch.Tensor) mask tensor denoting if hidden states should be reinitialized to zeros.
:param available_actions: (torch.Tensor) denotes which actions are available to agent
(if None, all actions available)
:param active_masks: (torch.Tensor) denotes whether an agent is active or dead.
:return action_log_probs: (torch.Tensor) log probabilities of the input actions.
:return dist_entropy: (torch.Tensor) action distribution entropy for the given inputs.
"""
obs = check(obs).to(**self.tpdv)
rnn_states = check(rnn_states).to(**self.tpdv)
action = check(action).to(**self.tpdv)
masks = check(masks).to(**self.tpdv)
if available_actions is not None:
available_actions = check(available_actions).to(**self.tpdv)
if active_masks is not None:
active_masks = check(active_masks).to(**self.tpdv)
actor_features = self.base(obs)
if self._use_naive_recurrent_policy or self._use_recurrent_policy:
actor_features, rnn_states = self.rnn(actor_features, rnn_states, masks)
if self.algo == "hatrpo":
action_log_probs, dist_entropy ,action_mu, action_std, all_probs= self.act.evaluate_actions_trpo(actor_features,
action, available_actions,
active_masks=
active_masks if self._use_policy_active_masks
else None)
return action_log_probs, dist_entropy, action_mu, action_std, all_probs
else:
action_log_probs, dist_entropy = self.act.evaluate_actions(actor_features,
action, available_actions,
active_masks=
active_masks if self._use_policy_active_masks
else None)
return action_log_probs, dist_entropy
class R_Critic(nn.Module):
"""
Critic network class for MAPPO. Outputs value function predictions given centralized input (MAPPO) or
local observations (IPPO).
:param args: (argparse.Namespace) arguments containing relevant model information.
:param cent_obs_space: (gym.Space) (centralized) observation space.
:param device: (torch.device) specifies the device to run on (cpu/gpu).
"""
def __init__(self, args, cent_obs_space, device=torch.device("cpu")):
super(R_Critic, self).__init__()
self.hidden_size = args.hidden_size
self._use_orthogonal = args.use_orthogonal
self._use_naive_recurrent_policy = args.use_naive_recurrent_policy
self._use_recurrent_policy = args.use_recurrent_policy
self._recurrent_N = args.recurrent_N
self._use_popart = args.use_popart
self.tpdv = dict(dtype=torch.float32, device=device)
init_method = [nn.init.xavier_uniform_, nn.init.orthogonal_][self._use_orthogonal]
cent_obs_shape = get_shape_from_obs_space(cent_obs_space)
base = CNNBase if len(cent_obs_shape) == 3 else MLPBase
self.base = base(args, cent_obs_shape)
if self._use_naive_recurrent_policy or self._use_recurrent_policy:
self.rnn = RNNLayer(self.hidden_size, self.hidden_size, self._recurrent_N, self._use_orthogonal)
def init_(m):
return init(m, init_method, lambda x: nn.init.constant_(x, 0))
if self._use_popart:
self.v_out = init_(PopArt(self.hidden_size, 1, device=device))
else:
self.v_out = init_(nn.Linear(self.hidden_size, 1))
self.to(device)
def forward(self, cent_obs, rnn_states, masks):
"""
Compute actions from the given inputs.
:param cent_obs: (np.ndarray / torch.Tensor) observation inputs into network.
:param rnn_states: (np.ndarray / torch.Tensor) if RNN network, hidden states for RNN.
:param masks: (np.ndarray / torch.Tensor) mask tensor denoting if RNN states should be reinitialized to zeros.
:return values: (torch.Tensor) value function predictions.
:return rnn_states: (torch.Tensor) updated RNN hidden states.
"""
cent_obs = check(cent_obs).to(**self.tpdv)
rnn_states = check(rnn_states).to(**self.tpdv)
masks = check(masks).to(**self.tpdv)
critic_features = self.base(cent_obs)
if self._use_naive_recurrent_policy or self._use_recurrent_policy:
critic_features, rnn_states = self.rnn(critic_features, rnn_states, masks)
values = self.v_out(critic_features)
return values, rnn_states
上面的代码定义了R_Actor与R_Critic,这里想必不需要多加赘述,使用上述代码构造的Actor与Critic,均使用了三种不同的网络结构:CNN、MLP与RNN,具体选择哪种通过参数进行控制。
在Actor中,通过选择的网络结构输出feature后,由act负责输出动作以及对应的概率:

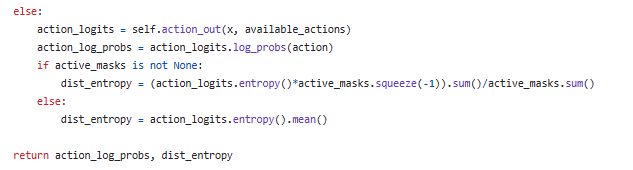
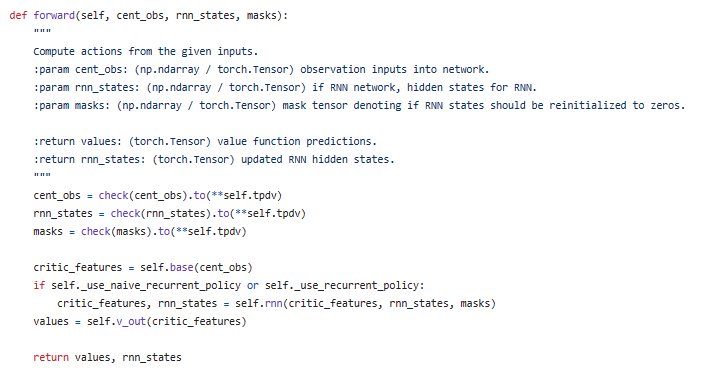
Critic接收模型参数、中心化观测空间和设备信息作为输入。在初始化过程中,它根据参数设置网络的各种属性,并构建基础模型(CNNBase或MLPBase)。如果使用循环神经网络(RNN)策略,则还会构建RNN层。然后,它定义了前向传播方法,根据输入计算出值函数预测值和更新后的RNN隐藏状态。
2.2 rMAPPOPolicy.py
前面定义了Actor与Critic,现在将它们用起来,构造一个基本的策略,这个策略包含以下几个功能:
2.2.1.计算给定输入的动作和值函数预测(get_actions方法):
点击查看get_actions代码
def get_actions(self, cent_obs, obs, rnn_states_actor, rnn_states_critic, masks, available_actions=None,
deterministic=False):
"""
Compute actions and value function predictions for the given inputs.
:param cent_obs (np.ndarray): centralized input to the critic.
:param obs (np.ndarray): local agent inputs to the actor.
:param rnn_states_actor: (np.ndarray) if actor is RNN, RNN states for actor.
:param rnn_states_critic: (np.ndarray) if critic is RNN, RNN states for critic.
:param masks: (np.ndarray) denotes points at which RNN states should be reset.
:param available_actions: (np.ndarray) denotes which actions are available to agent
(if None, all actions available)
:param deterministic: (bool) whether the action should be mode of distribution or should be sampled.
:return values: (torch.Tensor) value function predictions.
:return actions: (torch.Tensor) actions to take.
:return action_log_probs: (torch.Tensor) log probabilities of chosen actions.
:return rnn_states_actor: (torch.Tensor) updated actor network RNN states.
:return rnn_states_critic: (torch.Tensor) updated critic network RNN states.
"""
actions, action_log_probs, rnn_states_actor = self.actor(obs,
rnn_states_actor,
masks,
available_actions,
deterministic)
values, rnn_states_critic = self.critic(cent_obs, rnn_states_critic, masks)
return values, actions, action_log_probs, rnn_states_actor, rnn_states_critic
方法的输入参数如下:
cent_obs:集中化的输入,用于 Critic 网络。
obs:局部智能体输入,用于 Actor 网络。
rnn_states_actor:如果 Actor 是 RNN,表示 Actor 的 RNN 状态。
rnn_states_critic:如果 Critic 是 RNN,表示 Critic 的 RNN 状态。
masks:表示应该重置 RNN 状态的点。
available_actions:表示智能体可用的动作(如果为 None,则表示所有动作都可用)。
deterministic:是否应该从分布中选择动作的模式或进行采样。
方法返回的结果如下:
values:值函数的预测值(torch.Tensor)。
actions:要执行的动作(torch.Tensor)。
action_log_probs:所选动作的对数概率(torch.Tensor)。
rnn_states_actor:更新后的 Actor 网络的 RNN 状态(torch.Tensor)。
rnn_states_critic:更新后的 Critic 网络的 RNN 状态(torch.Tensor)。
2.2.2.计算值函数的预测值(get_values方法)
点击查看get_values代码
def get_values(self, cent_obs, rnn_states_critic, masks):
"""
Get value function predictions.
:param cent_obs (np.ndarray): centralized input to the critic.
:param rnn_states_critic: (np.ndarray) if critic is RNN, RNN states for critic.
:param masks: (np.ndarray) denotes points at which RNN states should be reset.
:return values: (torch.Tensor) value function predictions.
"""
values, _ = self.critic(cent_obs, rnn_states_critic, masks)
return values
方法的输入参数如下:
cent_obs:集中化观测。
rnn_states_critic:如果 Critic 是 RNN,表示 Critic 的 RNN 状态。
masks:表示应该重置 RNN 状态的点。
方法返回的结果如下:
values:值函数的预测值(torch.Tensor)。
2.2.3.对当前动作进行评估(evalute_actions方法)
点击查看evaluate_actions代码
def evaluate_actions(self, cent_obs, obs, rnn_states_actor, rnn_states_critic, action, masks,
available_actions=None, active_masks=None):
"""
Get action logprobs / entropy and value function predictions for actor update.
:param cent_obs (np.ndarray): centralized input to the critic.
:param obs (np.ndarray): local agent inputs to the actor.
:param rnn_states_actor: (np.ndarray) if actor is RNN, RNN states for actor.
:param rnn_states_critic: (np.ndarray) if critic is RNN, RNN states for critic.
:param action: (np.ndarray) actions whose log probabilites and entropy to compute.
:param masks: (np.ndarray) denotes points at which RNN states should be reset.
:param available_actions: (np.ndarray) denotes which actions are available to agent
(if None, all actions available)
:param active_masks: (torch.Tensor) denotes whether an agent is active or dead.
:return values: (torch.Tensor) value function predictions.
:return action_log_probs: (torch.Tensor) log probabilities of the input actions.
:return dist_entropy: (torch.Tensor) action distribution entropy for the given inputs.
"""
action_log_probs, dist_entropy = self.actor.evaluate_actions(obs,
rnn_states_actor,
action,
masks,
available_actions,
active_masks)
values, _ = self.critic(cent_obs, rnn_states_critic, masks)
return values, action_log_probs, dist_entropy
方法的输入同2.2.1,但输出结果略有不同,该方法最后会输出值函数预测、动作概率,以及策略熵。
2.2.4 计算动作(act方法)
点击查看act代码
def act(self, obs, rnn_states_actor, masks, available_actions=None, deterministic=False):
"""
Compute actions using the given inputs.
:param obs (np.ndarray): local agent inputs to the actor.
:param rnn_states_actor: (np.ndarray) if actor is RNN, RNN states for actor.
:param masks: (np.ndarray) denotes points at which RNN states should be reset.
:param available_actions: (np.ndarray) denotes which actions are available to agent
(if None, all actions available)
:param deterministic: (bool) whether the action should be mode of distribution or should be sampled.
"""
actions, _, rnn_states_actor = self.actor(obs, rnn_states_actor, masks, available_actions, deterministic)
return actions, rnn_states_actor
代码较简单,不多加赘述,返回动作与rnn状态(如果使用rnn)
2.3 r_mappo.py
这一部分较为重要,里面包含了策略的训练流程。
先把mappo的伪代码摆在这里以供参考:

for _ in range(self.ppo_epoch):
if self._use_recurrent_policy:
data_generator = buffer.recurrent_generator(advantages, self.num_mini_batch, self.data_chunk_length)
elif self._use_naive_recurrent:
data_generator = buffer.naive_recurrent_generator(advantages, self.num_mini_batch)
else:
data_generator = buffer.feed_forward_generator(advantages, self.num_mini_batch)
for sample in data_generator:
value_loss, critic_grad_norm, policy_loss, dist_entropy, actor_grad_norm, imp_weights \
= self.ppo_update(sample, update_actor)
可以看到,数据从经验回放池中被提取,更新动作由ppo_update完成,接下来我们先看ppo_update函数:
ppo_update可以概括为三个部分:
1.获取并计算必要的数据:
share_obs_batch, obs_batch, rnn_states_batch, rnn_states_critic_batch, actions_batch, \
value_preds_batch, return_batch, masks_batch, active_masks_batch, old_action_log_probs_batch, \
adv_targ, available_actions_batch = sample
old_action_log_probs_batch = check(old_action_log_probs_batch).to(**self.tpdv)
adv_targ = check(adv_targ).to(**self.tpdv)
value_preds_batch = check(value_preds_batch).to(**self.tpdv)
return_batch = check(return_batch).to(**self.tpdv)
active_masks_batch = check(active_masks_batch).to(**self.tpdv)
# Reshape to do in a single forward pass for all steps
values, action_log_probs, dist_entropy = self.policy.evaluate_actions(share_obs_batch,
obs_batch,
rnn_states_batch,
rnn_states_critic_batch,
actions_batch,
masks_batch,
available_actions_batch,
active_masks_batch)
sample是从经验回放池中获取的数据,在获取需要的数据后,确保其格式正确,最后将计算得到的值函数、动作的对数概率和动作分布的熵分别赋值给变量 values、action_log_probs 和 dist_entropy。这些值可以在后续的优化过程中使用。
2.对Actor的更新:
# actor update
imp_weights = torch.exp(action_log_probs - old_action_log_probs_batch)
surr1 = imp_weights * adv_targ
surr2 = torch.clamp(imp_weights, 1.0 - self.clip_param, 1.0 + self.clip_param) * adv_targ
if self._use_policy_active_masks:
policy_action_loss = (-torch.sum(torch.min(surr1, surr2),
dim=-1,
keepdim=True) * active_masks_batch).sum() / active_masks_batch.sum()
else:
policy_action_loss = -torch.sum(torch.min(surr1, surr2), dim=-1, keepdim=True).mean()
policy_loss = policy_action_loss
self.policy.actor_optimizer.zero_grad()
if update_actor:
(policy_loss - dist_entropy * self.entropy_coef).backward()
if self._use_max_grad_norm:
actor_grad_norm = nn.utils.clip_grad_norm_(self.policy.actor.parameters(), self.max_grad_norm)
else:
actor_grad_norm = get_gard_norm(self.policy.actor.parameters())
self.policy.actor_optimizer.step()
首先计算 imp_weights,通过计算动作的新对数概率 action_log_probs 和旧对数概率 old_action_log_probs_batch 的指数差异计算得到。
接下来,使用imp_weights计算 surr1 与 surr2。关于这一步,可以参考PPO的更新过程。
然后,根据是否使用策略激活掩码,计算了策略动作损失 policy_action_loss。如果使用策略激活掩码,则将损失乘以 active_masks_batch,并对其进行求和并归一化。否则,直接对损失进行求和并取平均。
接下来,将 policy_action_loss 赋值给 policy_loss,将 Actor 网络的梯度置零,准备进行反向传播和梯度更新。
如果此时需要对Actor进行更新,则计算总的损失 policy_loss 减去动作分布的熵 dist_entropy 乘以熵系数 self.entropy_coef,并进行反向传播。
接下来,根据是否使用最大梯度范数进行梯度裁剪或计算梯度范数,并进行梯度更新。
3.对Critic的更新:
#critic update
value_loss = self.cal_value_loss(values, value_preds_batch, return_batch, active_masks_batch)
self.policy.critic_optimizer.zero_grad()
(value_loss * self.value_loss_coef).backward()
if self._use_max_grad_norm:
critic_grad_norm = nn.utils.clip_grad_norm_(self.policy.critic.parameters(), self.max_grad_norm)
else:
critic_grad_norm = get_gard_norm(self.policy.critic.parameters())
self.policy.critic_optimizer.step()
return value_loss, critic_grad_norm, policy_loss, dist_entropy, actor_grad_norm, imp_weights
相比于Actor的更新,Critic的更新较为简单,首先代码调用了 self.cal_value_loss 方法来计算 value_loss。该方法根据值函数的预测值 values、旧的值函数预测值 value_preds_batch、回报值 return_batch 和策略激活掩码 active_masks_batch 计算值函数的损失。然后,就可以根据是否使用最大梯度范数进行梯度裁剪或计算梯度范数,进行梯度更新。
MAPPO的更新策略大致如上,细心的看官会有疑问,上面基本就是将PPO的更新代码照抄了一遍,哪里体现了“多智能体”呢?
为了解决这个问题,我们需要暂时离开算法部分,关注环境如何获取数据,以及代码如何执行。
3.数据获取
3.1 sharedReplayBuffer.py
第一个“秘密”隐藏在/onpolicy/utils/shared_buffer.py中,该文件定义了适用于多智能体训练的ReplayBuffer,请看下面这几行代码:
self.share_obs = np.zeros((self.episode_length + 1, self.n_rollout_threads, num_agents, *share_obs_shape),
dtype=np.float32)
self.obs = np.zeros((self.episode_length + 1, self.n_rollout_threads, num_agents, *obs_shape), dtype=np.float32)
self.rnn_states = np.zeros(
(self.episode_length + 1, self.n_rollout_threads, num_agents, self.recurrent_N, self.hidden_size),
dtype=np.float32)
self.rnn_states_critic = np.zeros_like(self.rnn_states)
self.value_preds = np.zeros((self.episode_length + 1, self.n_rollout_threads, num_agents, 1), dtype=np.float32)
self.returns = np.zeros_like(self.value_preds)
self.advantages = np.zeros((self.episode_length, self.n_rollout_threads, num_agents, 1), dtype=np.float32)
self.actions = np.zeros(
(self.episode_length, self.n_rollout_threads, num_agents, act_shape), dtype=np.float32)
self.action_log_probs = np.zeros(
(self.episode_length, self.n_rollout_threads, num_agents, act_shape), dtype=np.float32)
self.rewards = np.zeros(
(self.episode_length, self.n_rollout_threads, num_agents, 1), dtype=np.float32)
在ReplayBuffer中定义这些变量时,都将num_agents作为新的维度放了进去。与之对应的,在读取或存储数据时,是对环境中所有智能体的数据进行统一操作。
接下来我们顺藤摸瓜,既然经验回放池如此,那么环境中是什么样。这里以on-policy/onpolicy/envs/football/Football_Env.py为例:
for idx in range(self.num_agents):
self.action_space.append(spaces.Discrete(
n=self.env.action_space[idx].n
))
注意看这里,在环境文件中,如果存在复数的agent,那么就会将这些动作空间拼到一起,形成一个联合动作空间,等到需要使用时再通过维度变换将其分开。至于shared_obs也是同理。有关具体的维度变化情况,各位可以参考https://zhuanlan.zhihu.com/p/386559032 , 大佬写得非常详细,各位可以配合食用。
至此,大致的步骤都已明了,希望通过我浅薄的理解,能使大家对这个代码有更多的了解。
接下来是实战使用,敬请期待(这次绝不拖更)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗