MAPPO学习笔记(2) —— 从MAPPO论文入手
在有了上一节一些有关PPO算法的概念作为基础后,我们就可以正式开始对于MAPPO这一算法的学习。
那么,既然要学习一个算法,就不得不去阅读提出这一算法的论文。那么本篇博客将从MAPPO的论文出发,对MAPPO这一算法进行一定的介绍。论文的地址在这里:https://arxiv.org/pdf/2103.01955.pdf
同时,作者也在github上公布了源码:https://github.com/marlbenchmark/on-policy
但我个人更推荐这个轻量级的MAPPO,因为它的环境更简单,更容易理解:
https://github.com/tinyzqh/light_mappo
1.MAPPO论文
首先看论文的摘要部分,作者在摘要中说,PPO作为一个常见的在线强化学习算法,在许多任务中都取得了极为优异的表现。但是,当我们面对一个多智能体环境时,在线策略的表现往往不如某些离线策略,造成这种结果的原因很多,首先,就像我们上一节提到的,PPO由于是在线策略,即使是使用了另外一个不同的网络来收集数据,但它的网络依旧是在不断更新的,因此数据利用率较低,尤其是在多智能体环境中;另一方面,PPO的一些调参技巧在多智能体环境中也可能并不适用。
为了解决PPO在多智能体环境中遇到的种种问题,作者在PPO的基础上增加了智能体与智能体之间的信息交互,从而提出了MAPPO这一概念,并且作者还将MAPPO与VQN、QMIX等算法进行了对比(在文章中,作者主要使用了星际争霸、Hanabi-Full、multi-agent particle world environments (MPE)与Google Research Football (GRF)这几个不同的环境,有关这几个环境的简单介绍,可以参考:https://blog.51cto.com/u_15485092/5037000# ),当然,从论文的结果看,不出意外的,MAPPO在这几个测试环境中都取得了较为优异的表现。
值得一提的是,文章中作者并没有对MAPPO的整个结构,包括MAPPO的理论进行过多的介绍,于是我们只能够从代码中获取与MAPPO结构有关的信息,这一块很有可能放到下一节代码梳理中进行详细的说明(如果有下一节的话)
这篇论文的第二个部分就是作者对于MAPPO在上述提到的几个环境下结果的展示,我们这里以SMAC的结果为例:
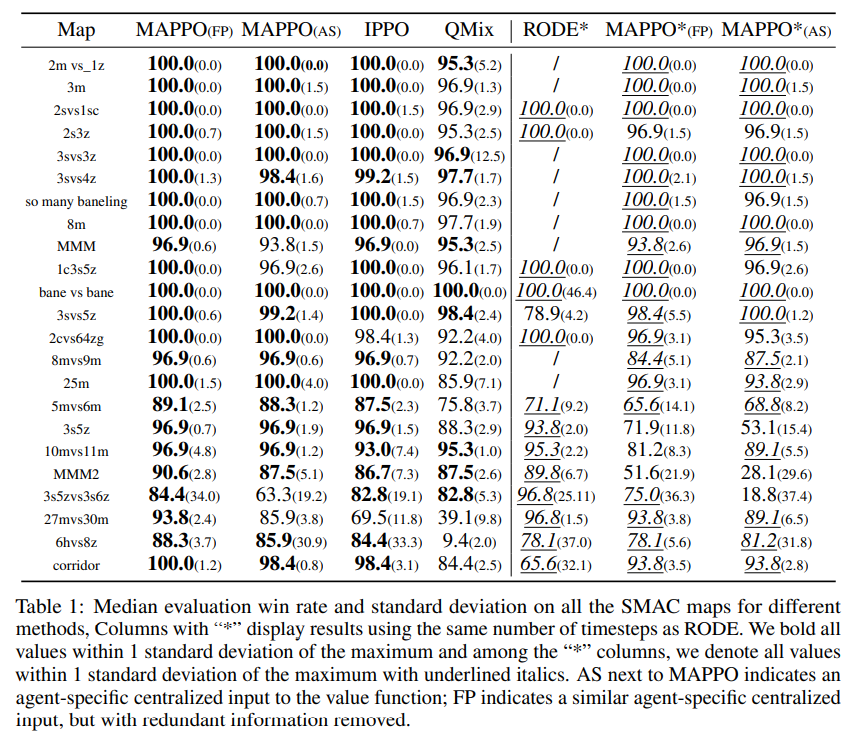
上面这张表格是几个多智能体算法在SMAC环境中的表现,第一列的Map代表该环境中的地图,每一张地图上的地形、兵种配置各不相同,表格中的数字则代表着该算法在目前这张地图中的胜率,从表格中我们不难看出,如果实验结果正确,那么MAPPO的表现是超过IPPO与QMIX的(这里补充说明一下IPPO,IPPO中的"I"代表着independent,意为多个独立的,无信息交互的PPO智能体,将这几个智能体放在同一个环境中进行实验,并将实验结果汇总,就是IPPO的结果)
此外,我们还留意到,即使是同样使用MAPPO算法,后面也有一个小括号(FP)与(AS),它代表着信息输入的几种不同的形式,这个会在之后的部分做介绍。
上面是MAPPO与其它算法在SMAC(星际争霸)环境中的表现对比。除了这个环节之外,作者还在其它的环境中进行了测试,这里附上结果,并不对所有的结果进行详细的说明。
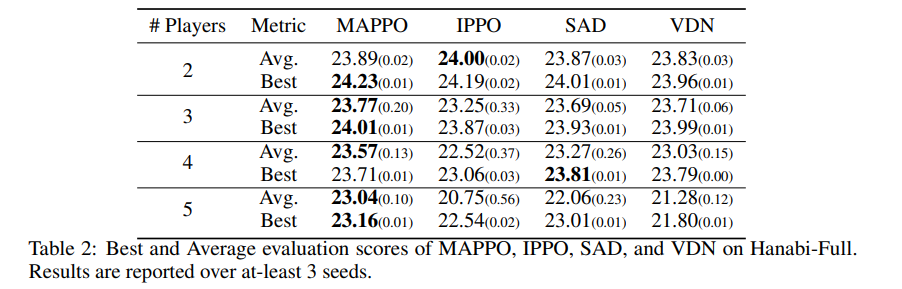
Hanabi的实验结果:
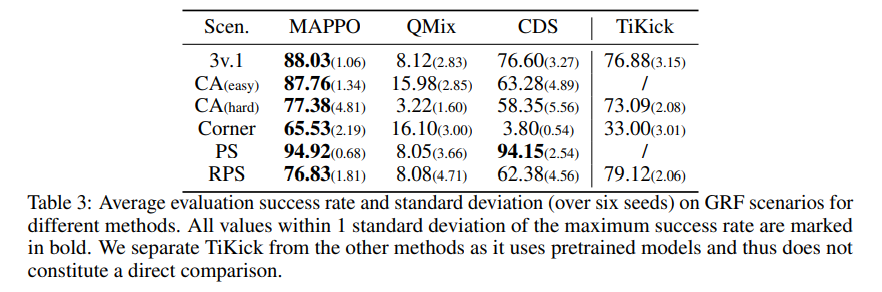
GRF的实验结果:
论文的的第三部分,也是最重要的一个部分,在有了这些实验结果后,接下来作者列出了几个会对实验结果产生较大影响的因素,包括值标准化、值函数的输入表示、训练数据的使用、PPO裁剪、Batchsize,在下面一个部分将会对这些因素进行一一介绍。
1.2. 实验影响因素分析
1. 值标准化
由于在训练过程中,目标值是在不断变化的,因此整个值函数的学习过程是不稳定的,为了应对这一点,作者对value进行了移动移动标准化,当计算GAE时,再将value反标准化,作者发现这样就可以提升MAPPO的效果。
2.值函数的输入形式
当我们将信息输入值函数时,首先要解决的一个问题就是:输入什么样的信息。在论文中,作者给出了以下几种信息输入的形式:
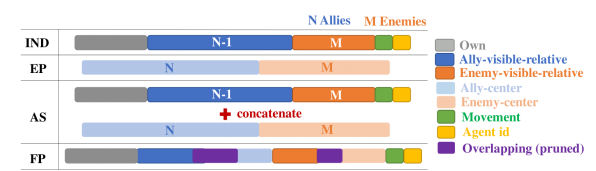
我们先假设存在这样一个环境,在这个环境中,我们把智能体分为两队,那么对于每一个智能体而言,就会存在多个“队友”与“对手”,并且每一队智能体都存在着一个“中心”。
那么上图中的第一种输入形式IND,就是所有智能体的信息的concatenate,而上图中的第二种输入形式EP,就是所有队伍中心信息的concatenate,上图中的第三种输入形式AS,就是EP与IND的concatenate,上图中的第四种输入形式FP,就是在AS的基础上去除了一些冗余的信息。
当然,这四种输入形式的表现在实验中自然会有许多区别,作者在实验环境中测试了这几种输入形式,并给出了数值分析结果,由于篇幅限制,这里还请各位读者自行阅读置顶链接中的原论文。但是结果具体如何,还是要依据实际情况做出实践再进行讨论(具体情况具体分析)。
3.训练数据的使用方式
PPO的一个重要机制就是重要性采样,这个重要性采样机制可以使我们重复地利用样本。那么接下来的问题是,我们该如何去使用这些样本。在PPO算法中,我们经常使用的就是将一个很大的batch分为32个,或者64个mini batch,,并且训练数十或者数百个epoch。但是在MAPPO中,作者发现,MAPPO的性能会随着数据重复使用的频率产生明显的下降,因此,作者进行研究时,对简单的任务使用了15个epoch,而较为复杂的任务则进行了10个或5个epoch (这里要注意强化学习中epoch、episode、time_step的区别)
4. PPO Clipping
在上一篇帖子中,我们提到了使用PPO_clipping来防止计算entropy以及重要性时产生过大的波动,作者在论文中也对最优的裁剪率ε进行了研究,并最终将ε设定为0.2。
以上就是MAPPO的作者在其论文中对一些机制进行的讨论,在下一篇博客中,我们将看一看MAPPO的代码,并从代码的角度加深理解。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗