

mysql记录操作进阶
操作使用方法
插入数据 insert:


1. 插入完整数据(顺序插入) 语法一: INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n); 语法二: INSERT INTO 表名 VALUES (值1,值2,值3…值n); 2. 指定字段插入数据 语法: INSERT INTO 表名(字段1,字段2,字段3…) VALUES (值1,值2,值3…); 3. 插入多条记录 语法: INSERT INTO 表名 VALUES (值1,值2,值3…值n), (值1,值2,值3…值n), (值1,值2,值3…值n); 4. 插入查询结果 语法: INSERT INTO 表名(字段1,字段2,字段3…字段n) SELECT (字段1,字段2,字段3…字段n) FROM 表2 WHERE …;
更新数据 update:
语法: UPDATE 表名 SET 字段1=值1, 字段2=值2, WHERE CONDITION; 示例1: UPDATE t1 set id=5 where name='wuye'; 示例2: UPDATE mysql.user SET password=password(‘123’) where user=’root’ and host=’localhost’;
删除数据 delete:
语法: DELETE FROM 表名 WHERE CONDITION; 示例: DELETE FROM mysql.user WHERE password=’’;
查询数据 select:
1、单表查询
2、多表查询
单表查询
单表查询语法:
SELECT DISTINCT 字段1,字段2... FROM 表名 WHERE 条件 GROUP BY field HAVING 筛选 ORDER BY field LIMIT 限制条数
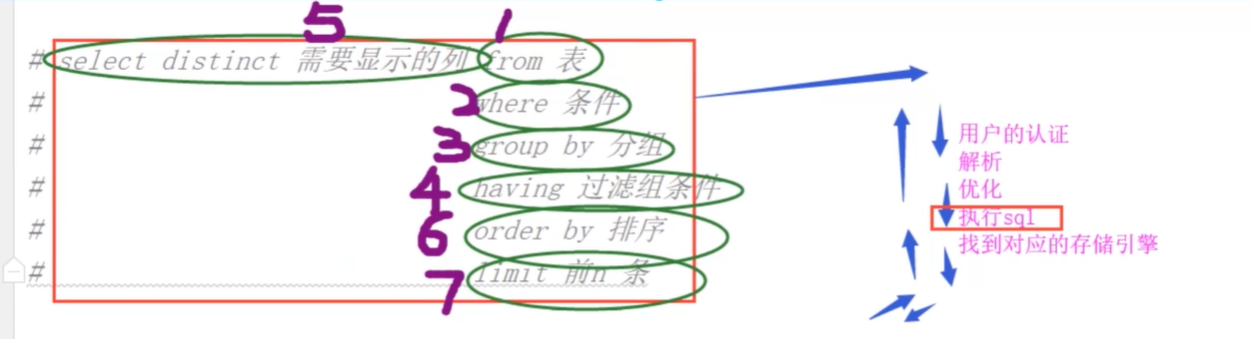
关键字执行的优先级:
from where group by select distinct having order by limit # 1.找到表:from # 2.拿着where指定的约束条件,去文件/表中取出一条条记录 # 3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组 # 4.执行select(去重) # 5.将分组的结果进行having过滤 # 6.将结果按条件排序:order by # 7.限制结果的显示条数
select name as n from 表 where n = 'wuye';# 无法执行,这个时候执行顺序还没有为name重新命名 select emp_name,age as n from 表 where age > 18 order by n;按顺序已为age重新命名,可按n进行排序
where语句
# 比较运算 > < = >= <= != <> # select name,salary from employee where salary > 5000; # 范围筛选 # 多选一 字段名 in (值1,值2,值3) # 20000,30000,3000,19000,18000,17000 # select * from employee where salary in (20000,30000,3000,19000,18000,17000) # 在一个模糊的范围里 between 10000 and 20000 # 在一个数值区间 1w-2w之间的所有人的名字 # select emp_name from employee where salary between 10000 and 20000; # 字符串的模糊查询 like # 通配符 % 匹配任意长度的任意内容 # select * from 表 where 字段 like '张%'; # 匹配以张开头的所有名字 # 通配符 _ 匹配一个字符长度的任意内容 # select * from 表 where 字段 like '张_'; # 匹配张三两个字的名字 # select * from 表 where 字段 like '张__'; # 匹配张无忌三个字的名字 # 正则匹配 regexp 更加细粒度的匹配的时候 # select * from 表 where 字段 regexp 正则表达式 # select * from employee where emp_name regexp '^j[a-z]{5}' # 逻辑运算 - 条件的拼接 # 与 and # 或 or # 非 not # select * from employee where salary not in (20000,30000,3000,19000,18000,17000) # 身份运算 - 关于null is null /is not null # 查看岗位描述不为NULL的员工信息 # select * from employee where post_comment is not null; # 查看岗位是teacher且名字是jin开头的员工姓名、年薪 #select emp_name,salary*12 from employee where post='teacher' and emp_name like 'jin%' #select emp_name,salary*12 from employee where post='teacher' and emp_name regexp '^jin.*'
group by 分组
#!/usr/bin/env python # -*- coding:utf-8 -*- # 分组 group by # select * from employee group by post # 会把在group by后面的这个字段,也就是post字段中的每一个不同的项都保留下来 # 并且把值是这一项的的所有行归为一组 # 聚合 把很多行的同一个字段进行一些统计,最终的到一个结果 # count(字段) 统计这个字段有多少项 # sum(字段) 统计这个字段对应的数值的和 # avg(字段) 统计这个字段对应的数值的平均值 # min(字段) 统计这个字段对应的数值的最小值 # max(字段) 统计这个字段对应的数值的最大值 # 分组聚合 (不能根据分组查出来最大最小值对应的具体的人,只能返回该组的第一个人) # 求各个部门的人数 # select count(*) from employee group by post; # 求公司里 男生 和女生的人数 # select count(id) from employee group by sex; # 求各部门的平均薪资 # select post,avg(salary) from employee group by post; # 求各部门的平均年龄 # select avg(age) from employee group by post; # 求各部门年龄最小的 # select post,min(age) from employee group by post; # 求各部门年龄最大的 # select max(age) from employee group by post; # 求各部门薪资最高的(不能返回薪资最高的人对应的人名,如果想需要用到多表查询) # select max(salary) from employee group by post; # 求各部门薪资最低的 # select min(salary) from employee group by post; # 求最晚入职的 # select max(hire_date) from employee; # 求最早入职的 # select min(hire_date) from employee; # 求各部门最晚入职的 # select max(hire_date) from employee group by post; # 求各部门最早入职的 # select min(hire_date) from employee group by post; # 求部门的最高薪资或者求公司的最高薪资都可以通过聚合函数取到 # 但是要得到对应的人,就必须通过多表查询 # 总是根据会重复的项来进行分组 # 分组总是和聚合函数一起用 最大 最小 平均 求和 有多少项
having,order by,limit
#!/usr/bin/env python # -*- coding:utf-8 -*- # having 条件 # 过滤 组 # 部门人数大于3的部门 # select post from employee group by post having count(*) > 3 # 1.执行顺序 总是先执行where 再执行group by分组 # 所以相关先分组 之后再根据分组做某些条件筛选的时候 where都用不上 # 2.只能用having来完成 # 平均薪资大于10000的部门 # select post from employee group by post having avg(salary) > 10000 # select * from employee having age>18 # order by # order by 某一个字段 asc; 默认是升序asc 从小到大 # order by 某一个字段 desc; 指定降序排列desc 从大到小 # order by 第一个字段 asc,第二个字段 desc; # 指定先根据第一个字段升序排列,在第一个字段相同的情况下,再根据第二个字段排列 # limit # 取前n个 limit n == limit 0,n # 考试成绩的前三名 # 入职时间最晚的前三个 # 分页 limit m,n 从m+1开始取n个 # 员工展示的网页 # 18个员工 # 每一页展示5个员工 # limit n offset m == limit m,n 从m+1开始取n个
多表查询
使用示例数据如下:
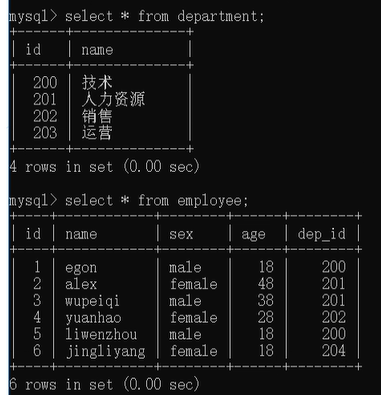
内连接
# 内连接:(内联查询 inner join) -> 两表或多表满足条件的所有数据查询出来(两表之间共有的数据) """ # 两表查询 select 字段 from 表1 inner join 表2 on 必要的关联条件 # 多表查询 select 字段 from 表1 inner join 表2 on 必要的关联条件1 inner join 表3 on 必要的关联条件2 ... """ # 基本语法 inner join on on后面接必要的关联条件 select * from employee inner join department on employee.dep_id = department.id; # 用as起别名(推荐) select * from employee as e inner join department as d on e.dep_id = d.id; # as可以省略 select * from employee e inner join department d on e.dep_id = d.id; # where 默认实现的就是内联查询的效果 select * from employee e,department d where e.dep_id = d.id; select * from employee e inner join department d on e.dep_id = d.id;
外连接
#(1) 左连接(左联查询 left join) 以左表为主,右表为辅,完整查询左表所有数据,右表没有的数据补null select * from employee e left join department d on e.dep_id=d.id; #(2) 右连接(右联查询 right join) 以右表为主,左表为辅,完整查询右表所有数据,左表没有的数据补null select * from employee e right join department d on e.dep_id=d.id; #(3) 全连接(全连接 union) 所有的数据都合并起来(左右连接合并起来) select * from employee e left join department d on e.dep_id=d.id union select * from employee e right join department d on e.dep_id=d.id;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号