业务领域建模Domain Modeling
我的工程实践是《基于情感词典的文本情感分析》,下面以我的工程实践为例,进行业务建模。
1)Collect application domain information
– focus on the functional requirements – also consider other requirements and documents
本项目致力于构建一个基于情感词典的文本情感分析系统,针对电商评论能够很好的提取出文本的情感词、情感值以及主题词(产品特征),使用户能够处理手头的大量评论数据集,得出商品的特征和缺陷,以期望通过评论数据来分析商品的不足与优势。
2) Brainstorming
– listing important application domain concepts – listing their properties/attributes – listing their relationships to each other
- 获取数据集。本项目所针对的目标是京东电子商品评论,获取数据集的主要方式有通过网络爬虫技术进行获取、下载公开的数据集或者利用开源的API进行获取。
- 文本预处理。包括对文本重复值的去除、缺失值的填充、分词、去除停用词以及词频统计和词性标注。并且进行特征提取,包括文本向量化和TF-IDF值的计算。
- 构建领域情感词典。
-
-
整合去重网上公共的情感词典、并加入一些网络用语,组成基础情感词典。
然后研究情感类别划分,在基础情感词典中选取一部分作为种子词。
-
在基础情感词典的基础上基于语义相识度的方法进行扩充。语义相识度的计算方法有:计算词汇的点互信息(PMI)、对word2vec处理后的文本计算词汇直接的余弦距离、使用Hownet计算。
-
计算文本的分词与种子词的语义相识度,选取一些比较相似的加入情感词典,最后整合成电商领域情感词典。
-
4.构建领域情感词典。
-
-
方法一:首先利用Hownet获取中文词语的对应的各项英文义元;其次使用SentiWorldNet数据库检索每个英文义元所处的各个同义词集合;接着计算这些同义词集合的平均情感强度值得到每个义元的情感倾向性强度值;最后计算各项义元的平均情感强度值,即得到中文词语的情感倾向强度值。
-
方法二:首先利用Hownet计算每个情感词的情感倾向值;再计算每个情感词的TF-IDF值;最后将情感词的情感倾向值和TF-IDF值相乘作为情感词最后的情感值。
-
5.提取文本的主题。
-
- 利用双向传播算法完成产品特征的抽取。双向传播算法利用情感词和产品特征之间的句法依存关系模式以及此前jieba分词的词性标注来进行提取。
- 运用LDA主题模型挖掘文本的主题(整个领域的主题)
3) Classifying the domain concepts into:
– classes – attributes / attribute values – relationships
• association, inheritance, aggregation
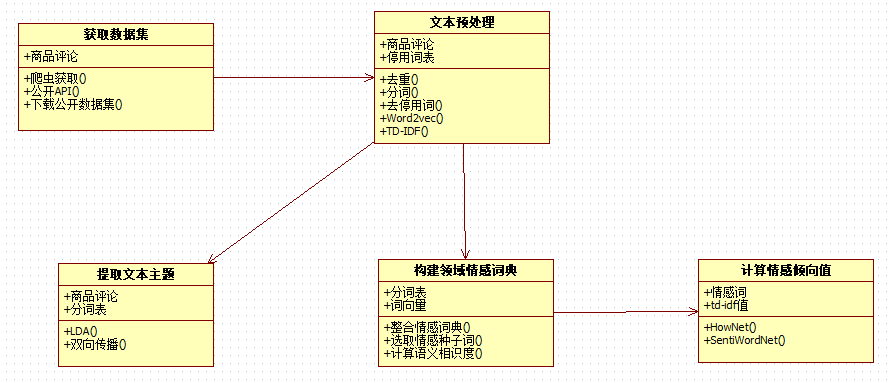
- 获取数据集。商品评论:爬虫抓取商品评论()、利用公开API获取()、下载公开数据集()。
- 文本预处理。商品评论:停用词表:去重()、分词()、去停用词()、word2vec()、TD-IDF()。
- 构建领域情感词典。分词:词向量:整合情感词典()、选取情感种子词()、计算语义相识度()。
- 计算情感倾向值。情感词:TF-IDF:Hownet()、SentiWorldNet()。
- 提取文本的主题。商品评论:分词表:LDA()、双向传播()。
4) Document result using UML class diagram