Embedding和Word2Vec用法
Embedding
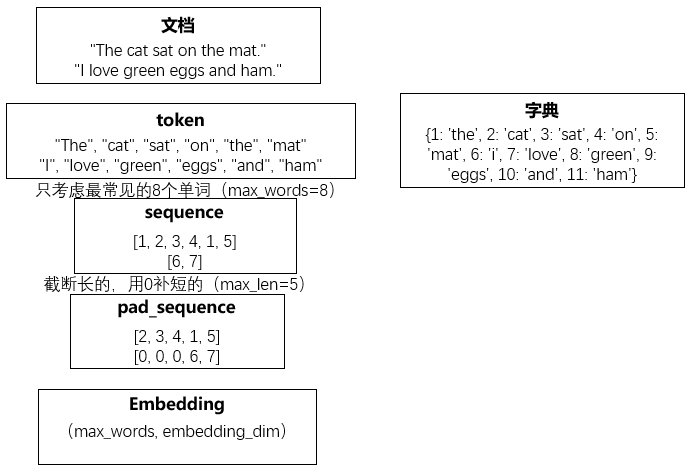
Embedding 层的输入是一个二维整数张量, 形状为(samples,sequence_length),即(样本数,序列长度)
较短的序列应该用 0 填充,较长的序列应该被截断,保证输入的序列长度是相同的
Embedding 层输出是(samples,sequence_length,embedding_dimensionality) 的三维浮点数张量。
- 首先,我们需要对文本进行分词处理,然后对分词结果进行序列化
- 再统一输入的序列长度,最后把统一长度的序列化结果输入到 Embedding 层中
整个过程可以用下面的图描述:
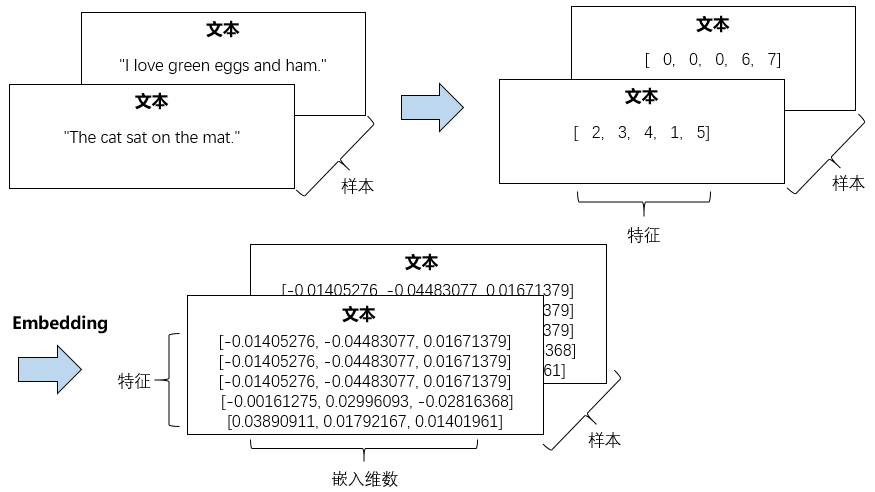
从样本的角度看,我们可以用下面的图描述这个过程:
gensim库提供了一个word2vec的实现,我们使用几个API就可以方便地完成word2vec
gensim实现Word2Vec
示意代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 | <code-pre class="code-pre code-pre-line" id="pre-bSn5x8"><code-line class="line-numbers-rows"></code-line>from torch import nn<code-line class="line-numbers-rows"></code-line>from gensim.models import Word2Vec<code-line class="line-numbers-rows"></code-line># w2v模型位置<code-line class="line-numbers-rows"></code-line>w2v_path = "model/w2v_all.model"<code-line class="line-numbers-rows"></code-line>class Preprocess():<code-line class="line-numbers-rows"></code-line> def __init__(self,sentences,sen_len,w2v_path=w2v_path):<code-line class="line-numbers-rows"></code-line> self.w2v_path = w2v_path<code-line class="line-numbers-rows"></code-line> self.sentences = sentences<code-line class="line-numbers-rows"></code-line> self.sen_len = sen_len<code-line class="line-numbers-rows"></code-line> self.idx2word = []<code-line class="line-numbers-rows"></code-line> self.word2idx = {}<code-line class="line-numbers-rows"></code-line> self.embedding_matrix = []<code-line class="line-numbers-rows"></code-line> <code-line class="line-numbers-rows"></code-line> def get_w2v_model(self):<code-line class="line-numbers-rows"></code-line> # 把之前保存的w2v模型加载进来<code-line class="line-numbers-rows"></code-line> self.embedding = Word2Vec.load(self.w2v_path)<code-line class="line-numbers-rows"></code-line> self.embedding_dim = self.embedding.vector_size<code-line class="line-numbers-rows"></code-line><code-line class="line-numbers-rows"></code-line> def add_embedding(self,word):<code-line class="line-numbers-rows"></code-line> # 把word加进embedding 并赋值一个随机向量<code-line class="line-numbers-rows"></code-line> vector = torch.empty(1,self.embedding_dim) #return a tensor filled with uninitialed dada. shape is (1*embedding_dim)<code-line class="line-numbers-rows"></code-line> #从均匀分布U(a,b)中生成值,填充参数vector,默认a=0,b=1<code-line class="line-numbers-rows"></code-line> torch.nn.init.uniform_(vector)<code-line class="line-numbers-rows"></code-line> self.word2idx[word] = len(self.word2idx) #为word2idx字典填充后,word2idx长度会加1<code-line class="line-numbers-rows"></code-line> self.idx2word.append(word)<code-line class="line-numbers-rows"></code-line> print("word:",word)<code-line class="line-numbers-rows"></code-line> # torch.cat是将两个张量(tensor)拼接在一起 按维数0拼接(竖着拼)<code-line class="line-numbers-rows"></code-line> self.embedding_matrix = torch.cat([self.embedding_matrix,vector],0)<code-line class="line-numbers-rows"></code-line> print("embedding_matrix.shape",self.embedding_matrix.shape)<code-line class="line-numbers-rows"></code-line> <code-line class="line-numbers-rows"></code-line> def make_embedding(self,load=True):<code-line class="line-numbers-rows"></code-line> print("get embedding..")<code-line class="line-numbers-rows"></code-line> #加载embedding模型<code-line class="line-numbers-rows"></code-line> if load:<code-line class="line-numbers-rows"></code-line> print("加载word to vec模型")<code-line class="line-numbers-rows"></code-line> self.get_w2v_model()<code-line class="line-numbers-rows"></code-line> else:<code-line class="line-numbers-rows"></code-line> raise NotImplementedError<code-line class="line-numbers-rows"></code-line><code-line class="line-numbers-rows"></code-line> # 制作一个word2idx的字典<code-line class="line-numbers-rows"></code-line> # 制作一个idx2word的list<code-line class="line-numbers-rows"></code-line> # 制作一个word2vector的list<code-line class="line-numbers-rows"></code-line> for i,word in enumerate(self.embedding.wv.key_to_index ):<code-line class="line-numbers-rows"></code-line> print('get words #{}'.format(i+1), end='\r')<code-line class="line-numbers-rows"></code-line> # 例:self.word2idx['李']=1<code-line class="line-numbers-rows"></code-line> # self.idx2word[1]='李'<code-line class="line-numbers-rows"></code-line> # self.vector[1]='李'<code-line class="line-numbers-rows"></code-line> self.word2idx[word]=len(self.word2idx)<code-line class="line-numbers-rows"></code-line> self.idx2word.append(word)<code-line class="line-numbers-rows"></code-line> self.embedding_matrix.append(self.embedding.wv[word])<code-line class="line-numbers-rows"></code-line> # 将embedding_matrix转为tensor类型<code-line class="line-numbers-rows"></code-line> self.embedding_matrix = torch.tensor(self.embedding_matrix)<code-line class="line-numbers-rows"></code-line> # 将PAD和UNK加入embedding中<code-line class="line-numbers-rows"></code-line> self.add_embedding("<PAD>")<code-line class="line-numbers-rows"></code-line> self.add_embedding("<UNK>")<code-line class="line-numbers-rows"></code-line> print("total words: {}".format(len(self.embedding_matrix)))<code-line class="line-numbers-rows"></code-line> return self.embedding_matrix<code-line class="line-numbers-rows"></code-line><code-line class="line-numbers-rows"></code-line> def pad_sequence(self,sentence):<code-line class="line-numbers-rows"></code-line> # 将每个句子变成统一的长度<code-line class="line-numbers-rows"></code-line> if len(sentence)>self.sen_len:<code-line class="line-numbers-rows"></code-line> sentence = sentence[:self.sen_len] #截断<code-line class="line-numbers-rows"></code-line> else:<code-line class="line-numbers-rows"></code-line> pad_len = self.sen_len-len(sentence)<code-line class="line-numbers-rows"></code-line> for _ in range(pad_len):<code-line class="line-numbers-rows"></code-line> sentence.append(self.word2idx["<PAD>"])<code-line class="line-numbers-rows"></code-line> assert len(sentence)==self.sen_len<code-line class="line-numbers-rows"></code-line> return sentence<code-line class="line-numbers-rows"></code-line><code-line class="line-numbers-rows"></code-line> def sentence_word2idx(self):<code-line class="line-numbers-rows"></code-line> # 把句子里面的字转成对应的index<code-line class="line-numbers-rows"></code-line> sentence_list = []<code-line class="line-numbers-rows"></code-line> for i,sen in enumerate(self.sentences):<code-line class="line-numbers-rows"></code-line> print('sentence count #{}'.format(i+1), end='\r')<code-line class="line-numbers-rows"></code-line> sentence_idx = []<code-line class="line-numbers-rows"></code-line> for word in sen:<code-line class="line-numbers-rows"></code-line> if(word in self.word2idx.keys()):<code-line class="line-numbers-rows"></code-line> sentence_idx.append(self.word2idx[word])<code-line class="line-numbers-rows"></code-line> else:<code-line class="line-numbers-rows"></code-line> sentence_idx.append(self.word2idx["<UNK>"])<code-line class="line-numbers-rows"></code-line> # 把每个句子长度统一<code-line class="line-numbers-rows"></code-line> sentence_idx = self.pad_sequence(sentence_idx)<code-line class="line-numbers-rows"></code-line> sentence_list.append(sentence_idx)<code-line class="line-numbers-rows"></code-line> return torch.LongTensor(sentence_list)<code-line class="line-numbers-rows"></code-line><code-line class="line-numbers-rows"></code-line> def labels_to_tensor(self,y):<code-line class="line-numbers-rows"></code-line> #把标签label也转为tensor<code-line class="line-numbers-rows"></code-line> y = [int(label) for label in y]<code-line class="line-numbers-rows"></code-line> return torch.LongTensor(y)</code-pre> |
1 2 3 4 5 6 7 8 9 | <code-pre class="code-pre code-pre-line" id="pre-i6E3YZ"><code-line class="line-numbers-rows"></code-line>def train_word2vec(x):<code-line class="line-numbers-rows"></code-line> # 训练word embedding<code-line class="line-numbers-rows"></code-line> """<code-line class="line-numbers-rows"></code-line> Embedding 层的输入是一个二维整数张量, 形状为(samples,sequence_length),即(样本数,序列长度)<code-line class="line-numbers-rows"></code-line> Embedding 层输出是(samples,sequence_length,embedding_dimensionality) 的三维浮点数张量。<code-line class="line-numbers-rows"></code-line> """<code-line class="line-numbers-rows"></code-line> model = word2vec.Word2Vec(x,vector_size=250,window=5,min_count=5,workers=12,epochs=10,sg=1) #iter is epochs<code-line class="line-numbers-rows"></code-line> return model</code-pre> |
__EOF__

本文作者:lishuaics
本文链接:https://www.cnblogs.com/L-shuai/p/15814311.html
关于博主:IT小白
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/L-shuai/p/15814311.html
关于博主:IT小白
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人