pytorc使用多个GPU同时训练模型
pytorch使用同一设备上多个GPU同时训练模型,只需在原有代码中稍作修改即可。
改动1:
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,3' # 这里输入你的GPU_id
改动2:
if torch.cuda.device_count() > 1: model = nn.DataParallel(model) model.to(device)
使用多GPU训练,速度明显得到提升。
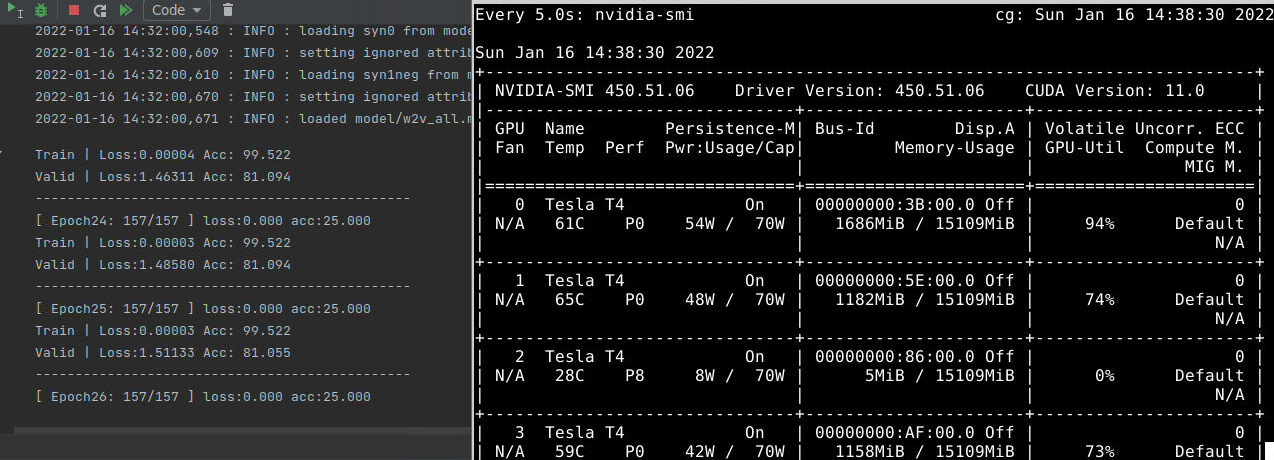
官方示例代码
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '2,3' # 这里输入你的GPU_id
# Parameters and DataLoaders
input_size = 5
output_size = 2
batch_size = 30
data_size = 100
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Dummy DataSet
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),
batch_size=batch_size, shuffle=True)
# Simple Model
class Model(nn.Module):
# Our model
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
# Create Model and DataParallel
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model = nn.DataParallel(model)
model.to(device)
#Run the Model
for data in rand_loader:
input = data.to(device)
output = model(input)
print("Outside: input size", input.size(),
"output_size", output.size())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号