TF-IDF具体算法和原理
TF-IDF算法
相关概念
-
信息检索(IR)中最常用的一种文本关键信息表示法
-
基本信息:
- 如果某个词在一篇文档中出现的频率高,并且在语料库中其它词库中其他文档中很少出现,则认为这个词具有很好的类别区分能力。
-
词频TF:Term Frequency,衡量一个term在文档中出现的有多频繁
- 平均而言,出现越频繁的词,其重要性可能就越高
-
考虑到文章长度的差异,需要对词频做标准化
- TF(t) = (t出现在文档中的次数) / (文档中的term总数)
- TF(t) = (t出现在文档中的次数) / (文档中出现最多的term)
-
逆文档频率IDF:Inverse Document Frequency,用于模拟在该语料的实际使用环境中,某一个term有多重要。
- 有些词到处都出现,但是明显没什么卵用。比如各种停用词,过渡句用词之类的。所以只看TF是没什么用的。
- 因此把罕见的词的重要性(weight)提高,把常见词的重要性降低。
-
IDF的具体算法:
- IDF(t) = log(语料库中的文档总数 / (含有该term的文档总数+1 ))
- 加1是为了防止某term出现0次,导致结果无法计算。
- IDF(t) = log(语料库中的文档总数 / (含有该term的文档总数+1 ))
-
TF-IDF = TF * IDF(相乘)
- TF-IDF与一个词在文档中的出现次数成正比
- 与该词在整个语料中的出现次数成反比
缺点:- 简单快速
- 结果也比较符合实际情况
-
缺点:
-
单纯以“词频”衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多
-
无法考虑词与词之间的相互关系
-
这种算法无法体现词的位置信息,出现位置靠前的词语出现位置靠后的词,都被视为重要性相同,这是不正确的
-
一种解决方法是:对全文的第一段和每一段的第一句话,给与较大的权重。
-
-
TF(Term Frequency,缩写为TF)也就是词频啦,即一个词在文中出现的次数,统计出来就是词频TF,显而易见,一个词在文章中出现很多次,那么这个词肯定有着很大的作用,但是我们自己实践的话,肯定会看到你统计出来的TF 大都是一些这样的词:‘的’,‘是’这样的词,这样的词显然对我们的分析和统计没有什么帮助,反而有的时候会干扰我们的统计,当然我们需要把这些没有用的词给去掉,现在有很多可以去除这些词的方法,比如使用一些停用词的语料库等。
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现"中国"、"蜜蜂"、"养殖"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,"蜜蜂"和"养殖"的重要程度要大于"中国",也就是说,在关键词排序上面,"蜜蜂"和"养殖"应该排在"中国"的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词("的"、"是"、"在")给予最小的权重,较常见的词("中国")给予较小的权重,较少见的词("蜜蜂"、"养殖")给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
给出具体的公式:

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

或者

2.计算逆文档频率IDF
需要一个语料库(corpus),用来模拟语言的使用环境。

如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
3.计算TF-IDF
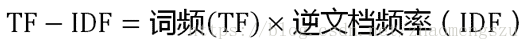
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
还是以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次,则这三个词的"词频"(TF)都为0.02。然后,搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
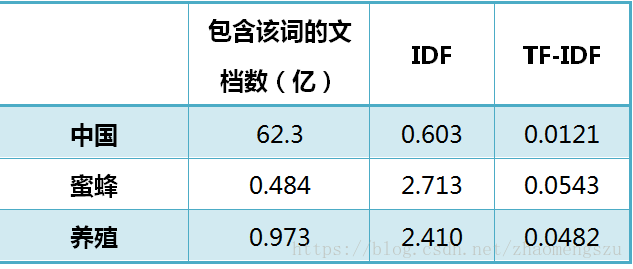
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
除了自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词("中国"、"蜜蜂"、"养殖")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
TF-IDF的具体实现
jieba,NLTK,sklearn,gensim等程序包都可以实现TF-IDF的计算。除算法细节上有差异外,更多的是数据输入/输出格式上的不同。
使用jieba实现TD-IDF算法
输出结果会自动按照TF-IDF值降序排列,并且直接给出的是词条而不是字典ID,便于阅读使用。
可在计算TF-IDF时直接完成分词,并使用停用词表和自定义词库,非常方便。(直接传入句子,不需要提前切分词)
有默认的IDF语料库,可以不训练模型,直接进行计算
以单个文本为单位进行分析。
jieba核心是拿到关键词本身
jieba.analyse.set_stop_words(file_name)
劳动防护 13.900677652
生化学 13.900677652
奥萨贝尔 13.900677652
奧薩貝爾 13.900677652
考察队员 13.900677652
jieba.analyse.TFIDF(idf_path = None)
按照关键词评分的重要性排序的结果。
如果想要进一步知道关键词的具体评分值,加上withWeight=True
使用自定义的TFIDF频率文件
使用sklearn实现TF-IDF算法
sklearn输出格式为矩阵,直接为后续的sklearn建模服务
需要先使用背景语料库进行模型训练。
结果给出的是字典ID而不是具体的词条,直接阅读比较困难
class sklearn.feature_extraction.text.TfidfTransformer()
参数基本和上面一样
使用gensim实现TF-IDF算法
输出格式为list,目的也是为后续的建模分析服务。
需要先使用背景语料库进行模型训练。
结果中给出的是字典ID,而不是具体的词条(jieba给出的是具体词条),直接阅读结果比较困难。
__EOF__

本文链接:https://www.cnblogs.com/L-shuai/p/13817978.html
关于博主:IT小白
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人