
python-wordcloud词云库
一、词云介绍
- 词云又叫文字云,是对文本数据中出现频率较高的”关键词“在视觉上的突出呈现,形成关键词的渲染形成类似云一样的彩色图片,从而一眼就可以领略文本数据的主要表达意思。
- wordcloud 是优秀的词云展示第三方库,以词语为基本单位,通过图形可视化的方式,更加直观和艺术的展现文本
二、库安装
- 打开cmd
- 输入 pip install wordcloud
- 输入 pip install imageio
- 输入 pip install jieba
若是提示报错,有可能是pip工具版本过低,需要更新pip包管理工具
只需要输入 pip -m pip install --upgrade pip 即可
三、wordcloud 方法参数
wordcloud.WordCloud 对象
wordcloud.WordCloud(font_path=None, width=400, height=200, margin=2, ranks_only=None, prefer_horizontal=0.9,mask=None, scale=1, color_func=None, max_words=200, min_font_size=4, stopwords=None, random_state=None,background_color='black', max_font_size=None, font_step=1, mode='RGB', relative_scaling=0.5, regexp=None, collocations=True,colormap=None, normalize_plurals=True)
参数说明
- font_path:string
字体路径,需要展现什么字体就把该字体的路径+后缀名写上,如:font_path = "黑体.ttf"
- width:int(default = 400)
输出画布的宽度,默认为400像素
- height:int(default = 200)
输出画布的高度,默认为200像素
- prefer_horizontal:float(default = 0.90)
词语水平方向排版出现的频率,默认0.9,所以词语垂直方向排版出现的频率为0.1
- mask:nd-array or None (default = None)
如果参数为空,则使用二维遮罩绘制词云。如果mask非空,设置的宽高值将被忽略,遮罩形状被mask取代。除全白(#FFFFFF)的部分将不会绘制,其余部分会用于绘制词云。如:bg_pic = imread('读取一张图片.png'),背景图片的画布一定要设置为白色(#FFFFFF),然后显示的形状为不是白色的其他颜色。可以用ps工具将自己要显示的形状复制到一个纯白色的画布上再保存
- scale:float(default = 1)
按照比例进行放大画布,如设置为1.5,则长和高都是原来画布的1.5倍
- min_font_size:int(default = 4)
显示的最小的字体大小
- font_step:int(default = 1)
字体步长,如果步长大于1,会加快运算但是可能会导致结果出现较大的误差
- max_words:number(default = 200)
要显示的词的最大个数
- stopwords:set of strings or None
设置需要屏蔽的词,如果为空,则使用内置的 STOPWORDS
- background_color:color value(default = "black")
背景颜色,如:background_color = 'white'
- max_font_size:int or None(default = None)
显示的最大的字体大小
- mode:string(default = "RGB")
当参数为'RGB' 并且background_color不为空时,背景为透明
- relative_scaling:float(default = 0.5)
词频和字体大小的关联性
- color_func:callable(default = None)
生成新颜色的函数,如果为空,则使用 self.color_func
- regexp:string or None (optional)
使用正则表达式分隔输入的文本
- collocations:bool(default = True)
是否包括两个词的搭配
- colormap:string or matplotlib colormap(default = "ciridis")
给每个单词随机分配颜色,若指定color_func,则忽略该方法
函数
- fit_words(frequencies)
根据词频生成词云
- generate(text)
根据文本生成词云
- generate_from_text(text)
根据文本生成词云
- process_text(text)
将长文本分词并去除屏蔽词(此处指的是英文,中文分词需要用其他库来实现)
- recolor([random_state,color_func,colormap])
对现有输出重新着色。重新着色会比重新生成整个词云快很多
- to_array()
转化为 numpy array
- to_file(filename)
输出到文件
四、示例
案例一
import wordcloud
w = wordcloud.WordCloud()
w.generate("python c++ javascript java c c#")
w.to_file("a.png")

案例二
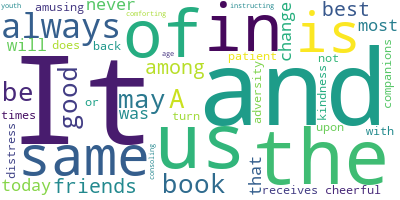
import wordcloud
txt = '''A good book may be among the best of friends. It is the same today that it always was, and it will never change. It is the most patient and cheerful of companions. It does not turn its back upon us in times of adversity or distress. It always receives us with the same kindness; amusing and instructing us in youth, and comforting and consoling us in age.'''
# 将默认黑色背景换成白色并且屏蔽单词'sn'
w = wordcloud.WordCloud(background_color = "white",stopwords={"sn"})
w.generate(txt)
w.to_file("词云.png")
案例三
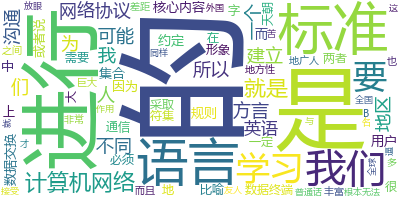
下面示例一个中文,使用的分词库是jieba库
import jieba
import wordcloud
text = '''计算机网络学习的核心内容就是网络协议的学习。网络协议是为计算机网络中进行
数据交换而建立的规则、标准或者说是约定的集合。因为不同用户的数据终端可能采取的字
符集是不同的,两者需要进行通信,必须要在一定的标准上进行。一个很形象地比喻就是我
们的语言,我们大天朝地广人多,地方性语言也非常丰富,而且方言之间差距巨大。A地区的
方言可能B地区的人根本无法接受,所以我们要为全国人名进行沟通建立一个语言标准,这就
是我们的普通话的作用。同样,放眼全球,我们与外国友人沟通的标准语言是英语,所以我
们才要苦逼的学习英语'''
# 使用jieba来对文章进行分词
txt = " ".join(jieba.cut(text))
# font_path 字体路径
w = wordcloud.WordCloud(background_color="white", font_path = "msyh.ttc")
w.generate(txt)
w.to_file("中文词云.png")
案例四
接下来的案例可能需要一些txt文本和图片,可以点击这里下载
使用周杰伦 Mojito 歌词,生成词云
import jieba
import wordcloud
# 打开txt文件
f = open("Mojito.txt", "r", encoding="utf-8")
t = f.read()
f.close()
txt = " ".join(jieba.lcut(t))
w = wordcloud.WordCloud( \
background_color = "white",
font_path = "msyh.ttc"
)
w.generate(txt)
w.to_file("Mojito.png")

案例五
周杰伦历年歌词比较,生成词云
import jieba
import wordcloud
f1 = open("Jay11月的萧邦.txt", "r", encoding="utf-8")
f2 = open("Jay2016-2020单曲歌词.txt", "r", encoding="utf-8")
t1 = f1.read()
t2 = f2.read()
f1.close()
f2.close()
txt1 = " ".join(jieba.lcut(t1))
w1 = wordcloud.WordCloud( \
background_color = "white",
font_path = "msyh.ttc"
)
w1.generate(txt1)
w1.to_file("Jay1.png")
txt2 = " ".join(jieba.lcut(t2))
w2 = wordcloud.WordCloud( \
background_color = "white",
font_path = "msyh.ttc"
)
w2.generate(txt2)
w2.to_file("Jay2.png")


案例六
Jay2016-2020单曲歌词 不规则图形词云
import jieba
import wordcloud
from imageio import imread
mask = imread("smile.jpg")
f = open("Jay2016-2020单曲歌词.txt", "r", encoding="utf-8")
t = f.read()
f.close()
txt = " ".join(jieba.lcut(t))
w = wordcloud.WordCloud(\
background_color = "white",\
font_path = "msyh.ttc", mask = mask,\
)
w.generate(txt)
w.to_file("jaysmile.png")


