
MySQL==> SQL执行流程分析
一、MySQL基本架构
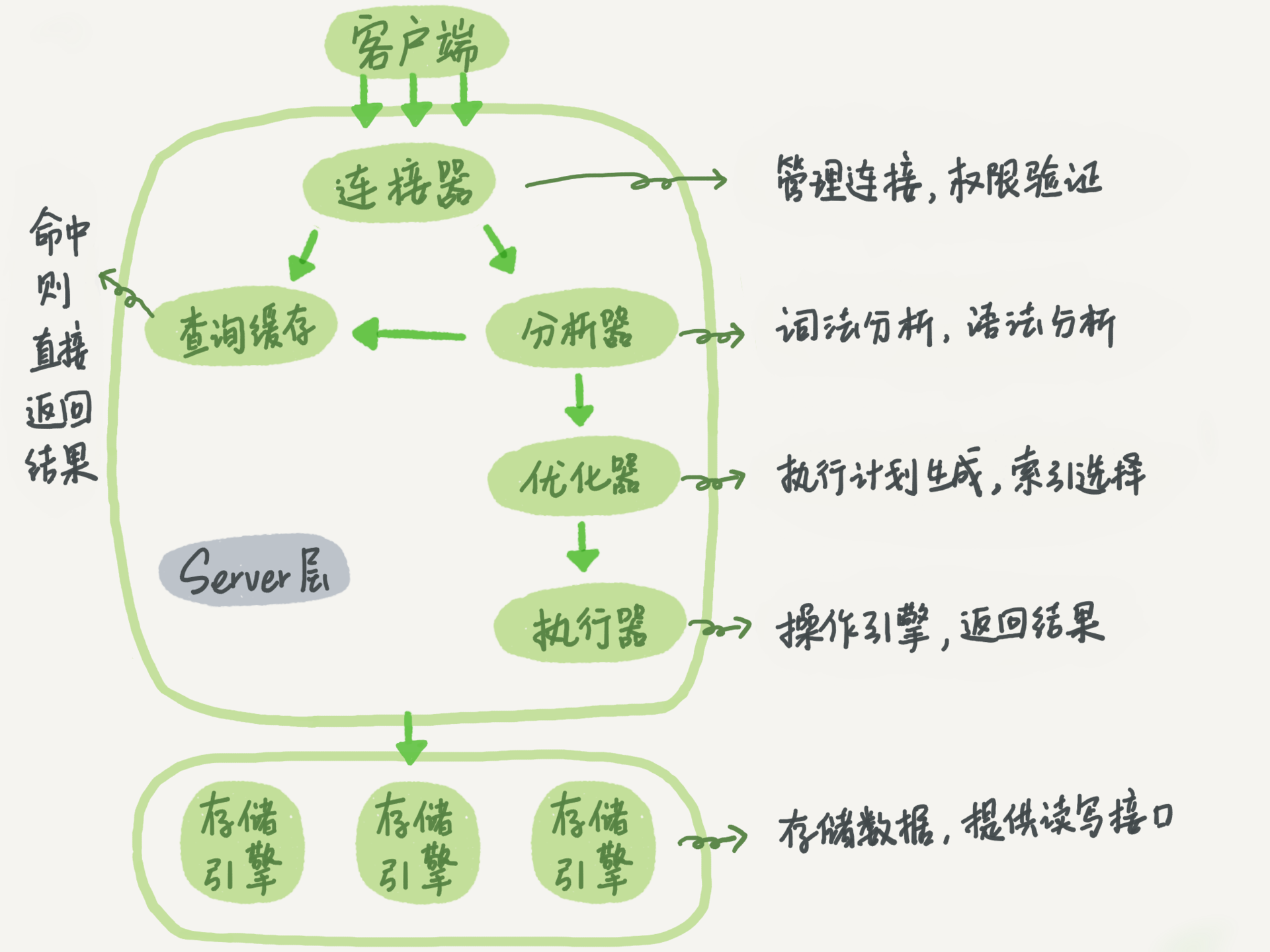 从该图可以看出,MySQL 主要分为 Server 层和存储引擎层:
从该图可以看出,MySQL 主要分为 Server 层和存储引擎层:
- Server 层中包含连接器,查询缓存,分析器,优化器,执行器,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能(存储过程、触发器、视图等)都在这一层实现。
- 存储引擎层主要负责最终数据的存储和提取,其架构模式是插件式的,支持 InnoDB、MyISAM、Memory等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
二、SELECT 语句的执行过程
SELECT 语句的执行过程为:连接、查询缓存、词法分析,语法分析,语义分析,构造执行树,生成执行计划、执行器执行计划,下面开始梳理一次完整的查询流程:
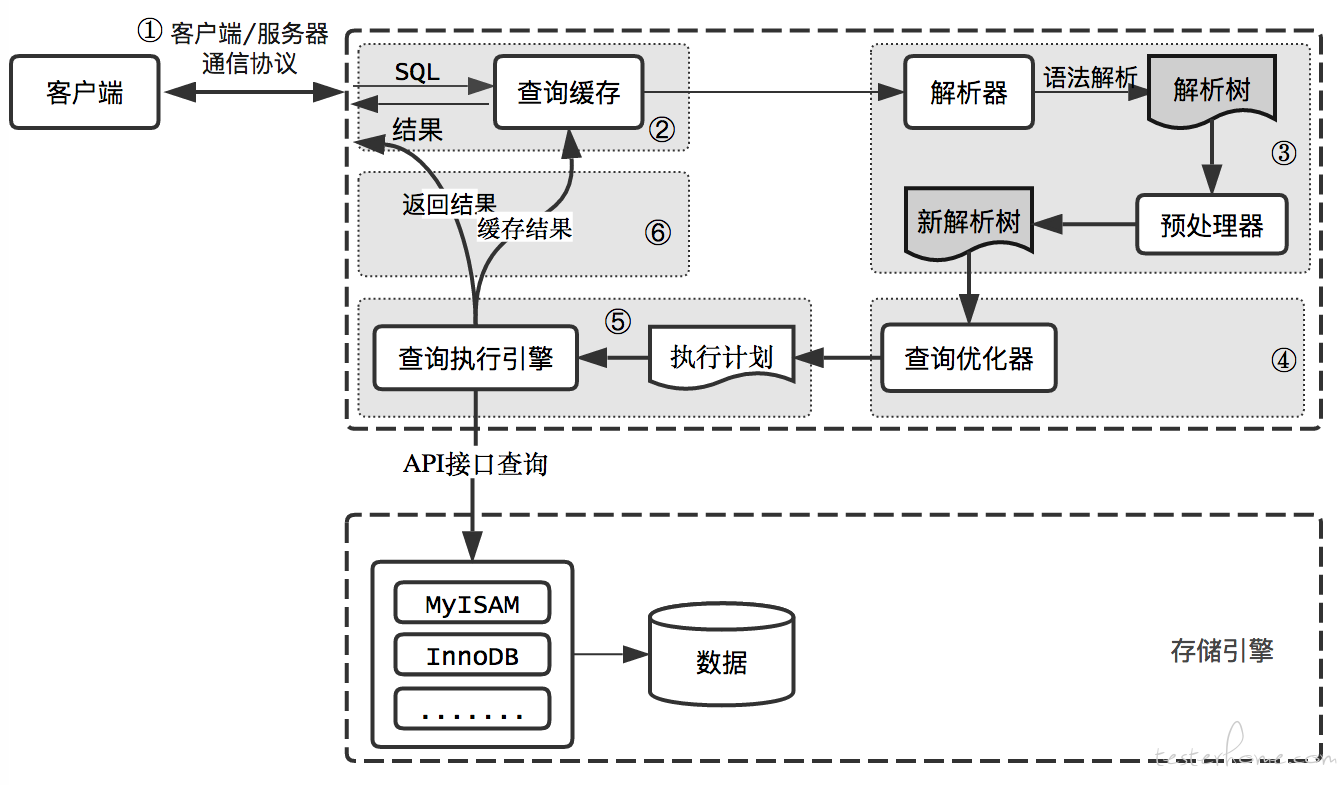
连接器
- 连接器负责与客户端建立连接,获取权限,维持和管理连接
- 连接命令: >mysql -uroot -p123456 -h127.0.0.1 -P3306 -A
- 其中 mysql 是自带的一个客户端连接工具
- 连接的基本流程: 认证用户名+密码 -> 权限列表中查询拥有的权限
- 后续的权限判断,都依赖于此时读到的权限.因此在修改权限之后要想生效需要重新登录
- 连接建立后,无其他动作,则此连接将处于空闲状态.
- 查看命令: >show processlist
- Command列若显示为Sleep,则表示空闲
- 若连接后无任何动作,连接器会自动断开
- 控制参数: wait_timeout, 默认8小时
- 针对非交互式连接
- 例: jdbc的方式
- 控制参数: interactive_timeout, 默认8小时
- 针对交互式连接(交互式连接:即在mysql_real_connect()函数中使用了CLIENT_INTERACTIVE选项)
- 例:终端的连接方式
- 资料:
- 长连接&短连接
- 建议使用长连接,减少资源建立时的开销,因为建立连接的过程比较复杂(开空间,验证密码,查权限...)
- 但是如果都使用长连接,则可能会导致MySQL占用内存增长过快而出现内存溢出
- 原因是MySQL在执行过程中临时使用的内存是管理在连接对象里面的.这些资源是要到连接断开时才会释放的.
- 长期积累会导致内存溢出,被系统强行kill掉,现象就是MySQL异常重启
- 解决:
- 定期断开长连接.使用一段时间/程序判断执行过一个占用内存极大的查询过后断开连接,之后在重连
- MySQL5.7之后,可在每次执行一个较大的操作后,执行mysql_reset_connection来重新初始化连接资源.此过程不需要重连和重新做权限验证.会将连接恢复到刚刚创建完成时的状态.
- mysql_reset_connection参考资料:
查询缓存
- 执行过的查询会被 MySQL 以 key-value 的形式缓存起来. key 是查询语句, value 是查询结果
- 实际使用时不建议开启此功能.原因是 MySQL 在执行 update 时会将整个表的所有缓存都失效
- 定制化配置:
- query_cache_type=DEMAND, 默认的 SQL 都不使用查询缓存.
- 显示指定使用缓存:
- select SQL_CACHE * from tb_xxx where id=xxx;
- MySQL8.0以上版本已将此功能废弃
分析器
- 解析SQL语句
- 词法分析: 解析输入的语句的每个单词,将 select 识别为查询语句,from 之后的字符串识别为表等
- 从 information schema 里面获得表的结构信息
- 语法分析: 基于词法分析的结果,语法分析器会判断是否满足 MySQL 语法规则
优化器
- 经过分析器之后, MySQL 即知道具体需要做什么操作,但是在具体操作之前要先经过优化器
- 优化:
- 表中若存在多个索引时,选择该使用哪个索引
- 多表关联时,决定各表的连接顺序
执行器
- 具体该执行的操作.
- 执行之前要先判断对表的操作是否具备权限.如果没有会返回权限错误的提示
- 如果存在查询缓存,会在查询缓存返回结果时来做权限验证,查询会在优化器之前调用 precheck 验证权限
- 具备权限之后,即打开表开始执行.打开表时会根据表的引擎定义来选择具体的引擎,并调用其接口来执行
- 执行过程(无索引,InnoDB):
- 调用 InnoDB 引擎取此表的第一行数据,判断 Where 条件是否满足,满足则将此行存在结果集中, 不满足则跳过
- 调用 InnoDB 引擎取下一行数据,重复上述逻辑,直到最后一行
- 执行器将所有满足条件的行作为结果集返回给客户端
- 问题:
- 对表的权限验证为何是在执行器阶段来执行?
- SQL语句要操作的表不只是SQL字面上那些,例如触发器,得在执行器阶段(过程中)才能确定。优化器等其他阶段是无能为力的
- 对表的权限验证为何是在执行器阶段来执行?
存储引擎
- 负责数据的存储和提取
总结
- 1、客户端与服务端连接,连接器来负责建立连接
- cmd: mysql -uroot -p123456 -h127.0.0.1 -P3306 -A
- 过程:
- 验证用户名+密码
- 从权限列表中查询所拥有的权限
- 2、判断是否命中查询缓存,检查当前是否开启了查询缓存(query_cache_type)
- 如果开启了查询缓存,则用当前 sql 作为 key 去缓存中查询,如果存在,则直接返回结果
- 3、分析SQL: 分析器工作,分析SQL,先做词法分析
- 识别出关键字如 select,insert, from 后的表, where 后的查询条件等
-
4、语法分析,基于词法分析的结果,来识别当前的SQL是否满足语法规定,比如关键字的使用先后顺序等
- 5、优化SQL执行,优化器工作,优化SQL的执行
- 如:选择要使用的索引
- 如:连表时选择的连接顺序
- 6、执行SQL,执行器工作,执行SQL语句
- 判断对此表是否具有查询权限
- 权限具备,则打开表开始执行
- 根据表的引擎定义,选择具体的引擎,去调引擎的接口执行查询
- 查询到的数据放入内存中,放入结果集里.
- 查询完毕后,将结果集返回给客户端
三、UPDATE 语句执行过程
UPDATE 语句执行过程总体上和 SELECT 语句是差不多的,分为:连接、查询缓存、词法分析,语法分析,语义分析,构造执行树,生成执行计划、执行器执行计划。但是有两个过程是完全不一样的:
- 第一个是查询缓存阶段,SELECT 语句是去缓存查有没有相同 SELECT 语句,并将其结果取出返回给客户端,而 UPDATE 语句是去清空该表的查询缓存。
- 第二个是执行器阶段,SELECT 语句是将磁盘上的数据取出,而 UPDATE 语句是先查到这些数据,然后进行更新并写入磁盘。
- 其他包括连接、词法分析、语法分析、生成执行计划等过程都是一样的。
更新流程涉及到两个重要的日志模块,binlog(归档日志) 和 redo log(重做日志)
binlog
binlog 记录了对 MySQL 数据库执行更改的所有操作,但是不包括 SELECT 和 SHOW 这类操作,因为这类操作对数据本身并没有修改。若操作本身并没有导致数据库发生变化,那么该操作也会写入二进制日志。MySQL 的主从赋值就是依靠 binlog。
redo log
redo log又称重做日志文件,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。在实例和介质失败(media failure)时,redo log文件就能派上用场,如数据库掉电,InnoDB存储引擎会使用 redo log 恢复到掉电前的时刻,以此来保证数据的完整性。
binlog 和 redo log 的区别
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是 “在某个数据页上做了什么修改”。binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完。binlog 是可以追加写入的,“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
通过以上对 binlog 和 redo log 的描述,我们再来看看 UPDATE 语句的执行过程:
- 例如
- mysql> update T set c=100 where ID=2;
- 流程
- 执行器先调用引擎接口取 ID=2 这一行
- 如果 ID 是主键,引擎直接用树搜索找到这一行。
- 如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器
- 否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据
- 把这个值改为 100,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中
- 同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。
- 然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
- 执行器先调用引擎接口取 ID=2 这一行
redo 两阶段提交
根据上面的介绍,可以发现 redo log 的写入拆成了两个步骤:prepare 和 commit,这就是"两阶段提交"。binlog 是 MySQL 内部实现二阶段提交的协调者,它为每个事务分配一个事务 ID。
- 原因
- 由于 redo log 和 binlog 是两个独立的逻辑,如果不用两阶段提交,要么就是先写完 redo log 再写 binlog,或者采用反过来的顺序,会导致数据的不一致出现。
- 简单说,redo log 和 binlog 都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。
- 一阶段
- 开启事务,redo log 和 undo log 已经记录了对应的日志,此时事务状态为
prepare
- 开启事务,redo log 和 undo log 已经记录了对应的日志,此时事务状态为
- 二阶段
binlog完成write 和 fsync后,成功,事务一定提交了,否则事务回滚 发送 commit,清除 undo 信息,刷 redo,设置事务状态为 completed。
- 举例
- 账本记上 卖一瓶可乐(redo log为 prepare状态),然后收钱放入钱箱(bin log记录)然后回过头在账本上打个勾(redo log置为commit)表示一笔交易结束。
- 如果收钱时交易被打断,回过头来整理此次交易,发现只有记账没有收钱,则交易失败,删掉账本上的记录(回滚)。
- 如果收了钱后被终止,然后回过头发现账本有记录(prepare)而且钱箱有本次收入(bin log),则继续完善账本(commit),本次交易有效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号