汇编基本知识(1)
各进制结尾标志:
汇编的预定义符号的前面是@为前缀,所以我们应该要避免@开头的符号
例如 字母,_,等开头
伪指令:
伪指令是内嵌在程序源代码中,由汇编器识别并执行相应动作的命令。与真正的指令不同,伪指令在程序运行时并不执行。
伪指令可用于定义变量、宏以及过程, 可用于命名段以及执行许多其他与汇编器相关的簿记任务。MASM 中伪指令大小写不敏感,如.data, .DATA 和.Data 是等价的,
指令:
汇编语言中的指令是一条汇编语句,在程序被汇编后就变成可执行的机器指令了汇编器把汇
编指令翻译成机器语言字节码,在运行时可以加载至内存由处理器执行。一条汇编指令包含:
标号(可选)
指令助记符(必需)
操作数(通常是必需的)
注释(可选)
数据标号: 数据标号标识了变量的地址,为在代码中引用该变量提供了方便。例如下例就定
义了一个名为count的变量:
count DWORD 100
汇编器为每个标号分配一个数字地址。在一个标号后定义多个数据项是可以的,在下面的例
子中,array 标识了第一个数字(1024 )的位置,其他在内存中相邻数字紧接其后:
array DWORD 1024,2048
DWORD 4096,8192
代码标号: 程序代码区(存放指令的地方)中的标号必须以冒号( :) 结尾。代码标号通常用
做跳转和循环指令的目标地址。例如,下面的JMP (跳转)指令将控制权转到标号target 标识的位
置,从而构成了一一个循环:
target:
mov ax,bx
jmp target
代码标号可以和指令在同一行,也可以独自成行:
L1:mov ax,bx
L2:
数据标号不能以冒号结尾,标号名遵循3.1.7 节中讨论的标识符名的规则。
操作数:
操作数:一条汇编语言指令可以有0~ 3 个操作数,每个操作数都可能是寄存器、内存操作数、常量表达式或IO端口。
在第2 章中讨论过寄存器的名字; 在3.1.2 节中,讨论了常量表达式:内存操作数由变量的名字或包含变量地址的一个或多
个寄存器指定,变量名表明了变量的地址,并且指示计算机引用给定内存地址的内容。下表包含了几个示例操作数。
注释:
1.;2.COMMENT ! ....... !
块注释: 以COMMENT伪指令以及一个用户定义的符号开始,编译器忽略后面所有的文本行,直到另一个相同的用户定义符号出现。例如:
NOP:
1.空 2.对齐
有时编译器或汇编器使用NOP指令把代码对齐到偶数地址边界。在下面的例子中,
第一个MOV 指令生成=个机器字节码,NOP指令将第三条指令的地址对齐到双字(4 的倍数)边界上。
汇编链接执行:
步骤1: 程序员使用文本编辑器创建ASCII 文本文件, 称为源文件(source file )。
步骤2: 汇编器读取源文件并生成目标文件(object file ),目标文件是源文件到机器语言的翻译。另外还可以选择生成列表文件(listing fle )。如果发生了错误,程序员必须回到步骤1修正程序。
步骤3: 链接器读取目标文件并检查程序是否调用了链接库中的过程,链接器从库中复制所需的过程并将其同目标文件合并在一起生成可执行文件(executable file ),还可以选择生成映像文件( map file )。
步骤4: 操作系统的装载器( loader )将可执行文件读人内存,并使CPU 转移到程序的起始地址开始执行。
列表文件包括程序源代码及行号,偏移地址,符号表和翻译后的机器码
链接器创建或更新的文件
映像文件: 映像文件是包含被链接程序的分段信息的文本文件,主要包含以下信息:
模块名。模块名作为链接器生成的可执行文件的基本名(除扩展名外的部分)。
程序文件头中(不是取自文件系统)的时间戳。
程序中各个段组的列表,包括每个段组的起始地址、长度、组名和类别信息。公共符号的列表,包括每个符号的地址、名称、线性地址和定义符号的模块。程序人口地址。
程序数据库文件: 若以-Zi (调试)选项来编译程序,MASM就会创建程序数据库文件(扩展为PDB)。
在链接阶段,链接器读取并更新它。在调试程序的时候,调试器可以根据PDB 文件显示程序的源代码、数据、运行时栈以及其他附加信息。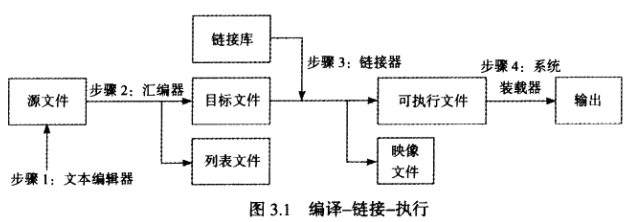
内部数据类型:
初始值:
初始值: 数据定义语句中要指定至少1个初始值,即使这个初始值是0。如果有多个初始值的话,那么应以逗号分隔。
对于整数数据类型,其初始值可以是与变量的数据类型( BYTE,WORD等)尺寸相匹配的整数常量或表达式。如果在
定义中不想初始化变量(赋予变量一个随机值),那么可以使用符号“?”作为初始值。所有的初始值,不管其格式如何,
均由编译器转换为二进制数据。比如00110010b, 32h 和50d 都将产生同样的二进制值, 原因即在于此。
例子:定义BYTE或者SBYTE
在数据定义语句中使用BYTE (定义字节)和SBYTE (定义有符号字节)伪指令,可以为一
个或多个有符号及无符号字节分配存储空间,每个初始值必须是8 位的整数表达式或字符常量。
例如:
valuel BYTE 'A' ;字符常量
value2 BYTB 最小的无符号字节常量
value3 BYTB 255 ;最大的无符号字节常量
value4 SBYTE-128 ;最小的有符号字节常量
value5 SBYTE +127 ;最大的有符号字节常量
使用问号代替初始值可以定义未初始化的变量,这表示将由可执行指令在运行时为变量动态
赋值:
value6 BYTE ?
可选的变量名是一个标号,标记该变量相对其所在段开始的偏移。例如,假设valuel 位于数
据段的偏移OOOO处并占用1个字节的存储空间,那么value2将位于段内偏移值0001的地方:
valuel BYTE 10h
value2 BYTE 20h
遗留的DB伪指令可以定义有符号或无符号的8位的变量:
val1DB 255 无符号字节
val2 DB-128 有符号字节
多个初始值:
如果一条数据定义语句中有多个初始值,那么标号(名字)仅仅代表第一个初始值的偏移。在下例中,假设list位于偏移OOOO处,那么值10将位于偏移OOOO处,值20位于偏移0001处,
第3章 汇编语言基础 61
30位于偏移0002 处,40 位于偏移0003 处:
1ist BYTE 10,20,30,40
下图以字节序列的形式显示了list 的定义情况,方框中的是值,左边是其对应的偏移: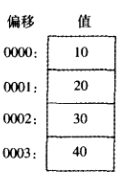
并非所有的数据定义都需要标号(名字),如果想继续定义以list 开始的字节数组,就可以在随后的行上接着定义其他数据:
list BYTE 10,20,30,40
BYTE 50,60,70,80
BYTE 81,82,83,84
在单条数据定义语句中,初始值可使用不同基数,字符和字符串也可以自由混用。在下面的例子中,listl 的内容和list2 的内容是相同的:
list1BYTE 10,32,41h,00100010blist2 BYTE 0Ah,20h, 'A',22h
定义字符串:
字符串可以占用多行,而无须为每行都提供一个标号,如下例所示:
greeting1 BYTE "Welcome to the Encryption Demo program
BYTB"created by Kip Irvine.",odh,Oah,
BYTE "If you wish to modify this program,please '
BYTE "send me a copy.",odh,0ah,0
十六进制字节0Dh 和0Ah 也称为CR/LF( 回车换行符,参见第1章)或行结束字符,在向标
准输出设备上写的时候,
回车换行符将光标移至下面一行左边的开始处。
续行符(\ )用来把两行连接成一条程序语句,续行符只能放在每行的最后
DUP:
DUP 操作符使用一个常量表达式作为计数器为多个数据项分配存储空间。在为字符串和数组
分配空间的时候,DUP 伪指令就十分有用。初始化和未初始化数据均可使用DUP 伪指令定义:
BYTE 20 DUP(0) 20字节、全部等于0
BYTE 20 DUP(?) ; 20字节,未初始化
BYTE 4 DUP (" STACK" ) 20字节," STACKSTACKSTACKSTACK"
定义DWORD 和SDWORD 数据
在数据定义语句中使用DWORD (定义双字)和SDWORD (定义有符号双字)伪指令,可以
例如:
为一个或多个32 位整数分配存储空间,
双字数组: 可以通过显式初始化数组每个元素或使用DUP 操作符创建双字数组。下面是一个包
含无符号初始值的双字数组:
myList DWORD 1,2,3,4,5
下面的是该数组在内存中的图解,假设myList 从偏移OOOO处开始,注意地址是以4 递增的: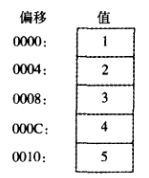
定义QWORD 数据
使用QWORD (定义8字节)伪指令可定义64位(8字节)的数据:
定义TBYTE 数据
3.4.7
使用TBYTE( 定义10字节)伪指令可定义80位( 10字节)的数据。该数据类型最初是用于
存储用二进制数编码的十进制数( binary-codeddecimal )的,对这类数据进行操作需要用浮点指令
集中的特殊指令:
vall TBYTE 1000000000123456789Ah
遗留的DT伪指令仍然可以使用:
val1 DT 1000000000123456789Ah
定义实数
REAL4 定义4字节的单精度实数,REAL8 定义8 字节的双精度实数,REAL10定义10字节
的扩展精度实数。每个伪指令都要求一个或多个与其对应的数据尺寸相匹配的实数常量初始值,
例如:
下表列出了每种实数类型的最少有效数据位数和大致的表示范围。
有效数据位数
数据类型
大致表示范围
单精度实数
1.18X 10-38-3.40X 1038
双精度实数
2.23 X 10-308_1.79X 10308
15
扩展精度实数
3.37 X 10-4932-1. 18 X 104932
19
遗留的DD,DQ和DT伪指令也可以用于定义实数:
rVal1DD-1.2
短实数
rVa12 DQ 3.2E-260
长实数
rVa13 DT 4.6E+4096
扩展精度实数
小尾顺序:
Intel 处理器使用称为小尾顺序( lttle endian order )的方案存取内存数据,小尾的含义就是变
量的最低有效字节存储在地址值最小的地址单元中,其余字节在内存中按顺序连续存储。
考虑一下双字12345678h 在内存中的存储情况,如果将该双字存储在偏移0 处,78h 将存储
在第一个字节中,56h 存储在第- 个字节中,其余存储在第三和第四字节。如下图所示:
78
OOOO
0001:
S6
小尾方式
0002 :
12
0003:
其他有些计算机系统使用大尾顺序(big endian order )的存储方案。下图显示了从偏移0 处
开始的双字12345678h 以大尾顺序方案存储的情况:
大尾方式
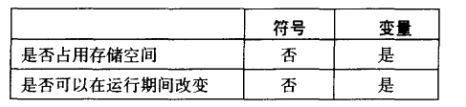
符号常量:
符号常量(或符号定义)是通过将标识符(或符号)与整数表达式或文本联系起来而创建的。
与保留存储空间的变量定义不同,符号常量并不占用任何实际的存储空间。符号常量仅在编译期
间汇编器扫描程序的时候使用,在运行期间不能更改。下表总结了二者的区别:
2
等号伪指令:
格式:
名字=表达式
所有的符号会在预处理阶段进行替换为对应表达式的值
例如:
Count=500
mov ax,Count会替换成 mov ax,500
为什么使用符号是因为更容易维护,他就跟宏一样,如果我们使用了10次Count,只需要更改Count=600,
其余的10各地方的值都会改变
符号常量的运用:
1.键值
2.DUP操作符
例子:
array Count DUP(0)
Count=5
则我们就知道有5个成员
且Count可以重定义 Count=10,则就是10个成员
符号值的改变与运行时候语句执行的顺序无关,仅仅与它定义的顺序有关
计算数组和字符串的大小
$号是返回当前程序语句的偏移值
list WORD 10,20,30
ListSize=($-list) 这就是listsize的大小
如果是算数组个数的话($-list)/2
AASTRING BYTE "DADSAFAFA"
BYTT "FSDFASD"
ListSize=($-AASTRING) 这就是AASTRING的大小
如果是算字符串个数的话($-list)/2
EQU伪指令:
将符号名同整数表达式或者任意文本联系起来
格式如下:
不可以重定义
TEXTEQU伪指令(可重定义):
与EQU非常相似,但是也可以用来创建文本宏
格式:
实地址程序设计

 浙公网安备 33010602011771号
浙公网安备 33010602011771号