UI自动化测试——Selenium框架
一、selenium
selenium是WEB的UI测试框架,可以和主流的编程语言(Python,Java,Net,PHP,JavaScript)整合来测试WEB系统,同时也是支持主流的浏览器(IE,Firefox,Chrome)。Selenium通过driver的驱动方式来操作浏览器,对浏览器进行各种交互式的验证(点击,输入,下拉框选项等等)
二、Selenium环境搭建步骤:
1、安装selenium库 :pip install selenium
2、安装Chrome浏览器
3、下载driver的驱动,并且把数据配置到path的环境变量
A、driver的驱动要与浏览器的版本完全匹配(99%)
B、把driver的应用程序放在python的安装目录下 https://registry.npmmirror.com/binary.html?path=chromedriver/
三、自动化测试
1、自动化测试:自动化测试就是通过代码或者是工具模拟人的行为来进行对WEB(APP)来进行操作。
2、UI自动化测试的技术栈:
1、编程语言(oop)
2、单元测试框架UnitTest
3、数据驱动(测试的数据分离到文件中)
4、参数化
5、selenium WEB测试框架
6、页面对象设计模式
7、持续集成
四、元素定位
1、原理:
webdriver之所以能够操作控制浏览器,是因为它首先需要定位到被操作的元素属性,然后才可以对浏览器做各种操作
2、如何定位
①单元素定位
②多元素定位:指的是元素的属性都一致,返回的是列表,可以根据列表的索引来定位元素属性
在selenium框架中,操作元素定位使用的类是By,里面方法有8种,那么也就是说,定位页面的元素属性方法有8种,分别是:
ID = "id" #ID不能是唯一的
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text" 模糊搜索
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
3、步骤:
#从selenium中导入webdriver
from selenium import webdriver
#导入时间的库
import time as t
#实例化webdrive,并且指定要测试的浏览器
drive=webdriver.Chrome()
#打开浏览器后导航到百度
drive.get('http://www.baidu.com')
#send keys 是输入的方法(通过ID的属性定位到百度的搜索输入框)
drive.find_element(By.ID,'kw').send_keys('QQ异常')
drive.find_element_by_id('kw').send_keys('selenium')
t.sleep(3)
#退出浏览器
drive.quit()
五、练习
注意,使用的类是By时,必须要提前导入,from selenium.webdriver.common.by import By
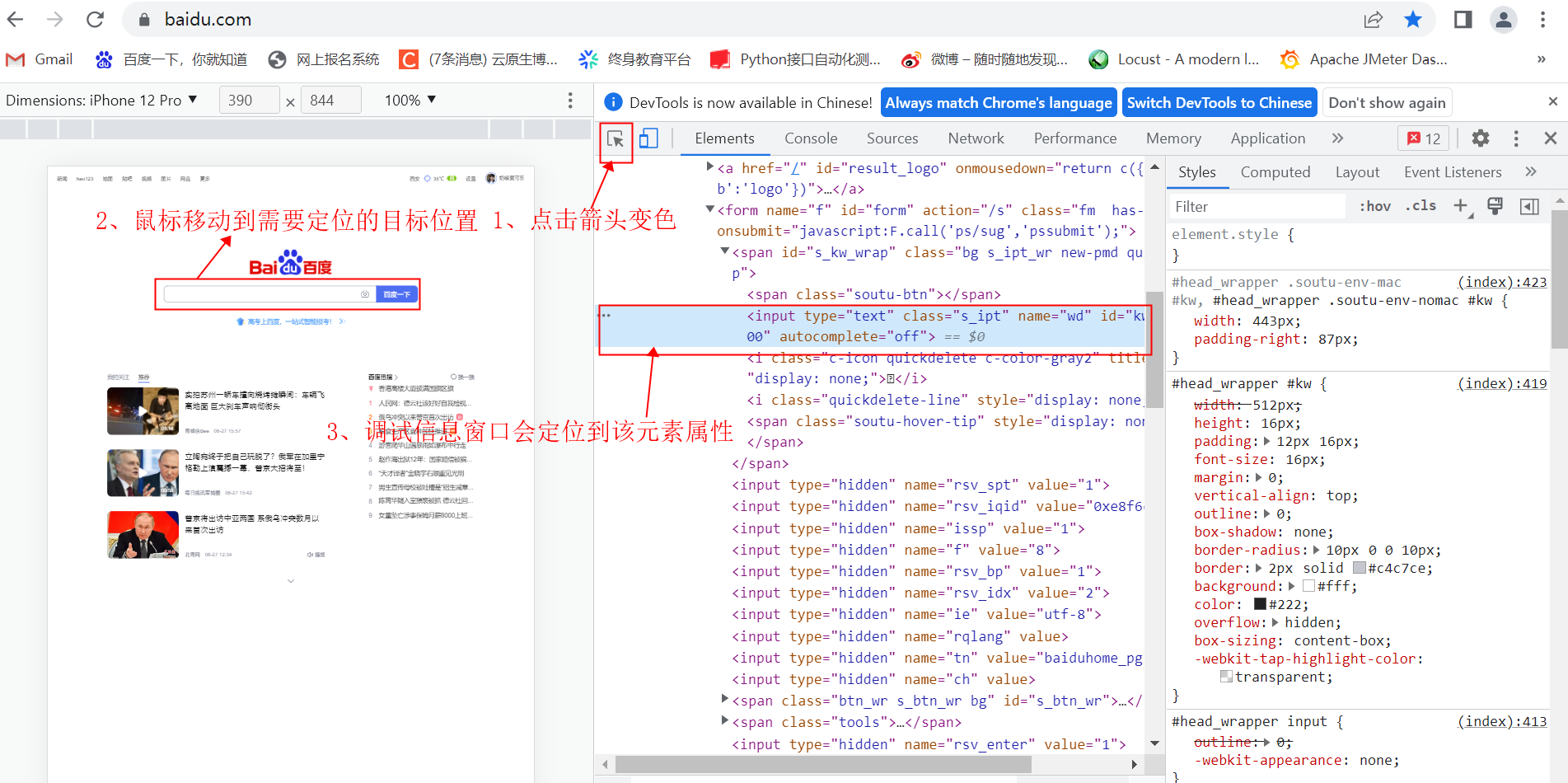
1、单个元素
①通过ID
通过元素属性ID定位到元素,方法是find_element_by_id。以百度搜索输入框为例,它的代码是:

它的id属性为kw,在搜索框输入关键字'selenium'的代码如下:
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element_by_id('kw').send_keys('selenium')
driver.quit()
②通过NAME
from selenium import webdriver
import time as t
driver=webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element_by_name('wd').send_keys('selenium')
t.sleep(2)
driver.quit()
③通过class_name
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element_by_class_name('s_ipt').send_keys('selenium')
time.sleep(3)
driver.quit()
④通过xpath
# full xpath元素属性
driver.find_element_by_xpath('/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input').send_keys('美食 图片')
from selenium import webdriver
import time as t
driver=webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element_by_xpath('//*[@id="kw"]').send_keys('selenium')
t.sleep(3)
driver.quit()
⑤通过超链接link_text
link_text用于对超链接的处理
from selenium import webdriver
import time as t
driver=webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element_by_link_text(u'新闻').click()
t.sleep(2)
driver.quit()
⑥partial_link_text
也用于对超链接的处理,与link_text不同的是,它是按模糊搜素方式进行处理的
代码为:
driver.find_element_by_partial_link_text(u'闻').click()
⑦通过css_selector
当使用ID、NAME等方式定位不到元素的时候,可以使用css_selector,方法是find_element_by_css_selector。获取方法是西安定位到元素属性后,用鼠标点击该属性,copy选项选择copy selector 选项
代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element_by_css_selector('#kw').send_keys('selenium')
time.sleep(3)
driver.quit()
2、多个元素
①tag name
多个元素定位(元素属性都一致)
A、获取到的元素属性,它是一个列表
B、按照我们需要被定位的元素属性,它在列表中是第几位,那么
就使用它的索引来定位
drive=webdriver.Chrome()
drive.get('http://www.baidu.com')
inputs=drive.find_elements_by_tag_name('input')
inputs[7].send_keys('selenium')
t.sleep(3)
drive.quit()
六:框架定位
进入iframe框架的三种方式:
1、ID
2、name
3、索引
drive=webdriver.Chrome()
drive.get('https://www.taobao.com/')
drive.find_element(By.LINK_TEXT,'亲,请登录').click()
t.sleep(5)
drive.find_element(By.NAME,'fm-login-id').send_keys('admin')
t.sleep(3)
drive.quit()
七、UI自动化常用的方法
1、
drive=webdriver.Chrome()
drive.get('http://www.baidu.com')
#current_url获取当前测试网页的地址
print(drive.current_url)
#page_source获取当前页码的代码
print(drive.page_source)
#获取当前测试网页的title
print(drive.title)
drive.quit()
2、网页前进与后退
from selenium import webdriver
import time as t
#页面的前进与后退
drive=webdriver.Chrome()
drive.get('http://www.baidu.com')
t.sleep(2)
drive.get('http://www.bing.com')
t.sleep(2)
drive.back()
print(drive.current_url)
t.sleep(2)
drive.forward()
print(drive.current_url)
drive.quit()
3、多窗口的处理的逻辑:
1、先获取当前窗口的句柄
2、点击后打开新的窗口
3、获取所有的窗口句柄
4、针对所有的窗口句柄循环,循环内部判断,如果不是当前的窗口,
那么就是新的窗口,那么就需要切换到新的窗口
driver=webdriver.Chrome()
driver.get('http://mail.sina.com.cn/')
nowHandler=driver.current_window_handle
t.sleep(3)
driver.find_element(By.LINK_TEXT,'注册').click()
t.sleep(3)
allHandlers=driver.window_handles
for handler in allHandlers:
if handler!=nowHandler:
#切换到新的窗口
driver.switch_to.window(handler)
t.sleep(3)
driver.find_element(By.NAME,'email').send_keys('adbff')
t.sleep(3)
driver.close()
t.sleep(2)
driver.switch_to.window(nowHandler)
t.sleep(3)
driver.find_element(By.ID,'freename').send_keys('drfrgfv')
t.sleep(3)
driver.quit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号