python爬虫之路(一)-----requests库详解
requests库
requests库是python实现的最简单易用的http库。
requests库的功能详解。
我们可以自然而然地想到这些方法其实就是http协议对资源的操作。


调用requests的get方法就是构造一个向服务器请求资源的requests对象,这个对象会返回一个包含服务器资源的response对象。

下面我们主要来讲以下requests库的request方法
request()中的参数
------------url:拟获取页面的url链接
------------**kwargs:控制访问的参数,均为可选项
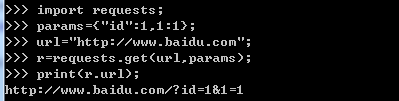
params : 字典形式,将params以字典的方式作为传入url中。
headers :字典形式,http定制头,我们可以这个来把爬虫伪装成浏览器。

data:字典形式、字符串或文件对象,用于向服务器提供或提交数据,作为request的内容
import requests; data={'id':"me","age":10}r=requests.request('post',"http://www.baidu.com",data=data); data="人生苦短,及时行乐";r=requests.request('post',"http://www.baidu.com",data=data);
json :json格式的数据,作为request的内容。
timeout :设置超时时间,以秒为单位,在规定的时间没有返回,抛出timeout异常。
不常用参数:
allow_redicts: True/False 默认为True,重定向开关
stream:True/False 默认为True 获取内容立即下载
verify:True/False 默认为True 认证数字证书开关
cert :本地SSL路径
高级参数:
1.获取cookie
cookies: 我们可以使用cookies参数传入我们设计好的cookies到服务器,此外,我们也可以通过cookies参数,获取响应cookie的一些值。
//获取cookie
import requests
url = 'http://httpbin.org/cookies';
response = requests.get(url) ;
print(response.cookies);
//向服务器传入cookie
import requests
url = 'http://httpbin.org/cookies'
cookies = { 'domain':'httpbin.org', }
response = requests.get(url, cookies=cookies) ;
print(response.text);
2.上传文件
files:字典类型,文件传输
import requests url = "http://www.baidu.com"; fs={"files":open("F://imgs//timg.jpg","rb")}; r=requests.request("post",url,files=fs);
3.设置代理
所谓代理,其实就是把一件事交给别人去做。当我们使用代理去访问服务器时,本机会将请求先发到代理,然后在由代理发到服务器。当接收服务器的响应时,先是代理收到响应,再转发到本机。
import requests proxies={ "http":"http://127.0.0.1:9743", "https":"https://127.0.0.1:9743", } r=requests.request("get","http://www.baidu.com",proxies=proxies); print(r.status_code);
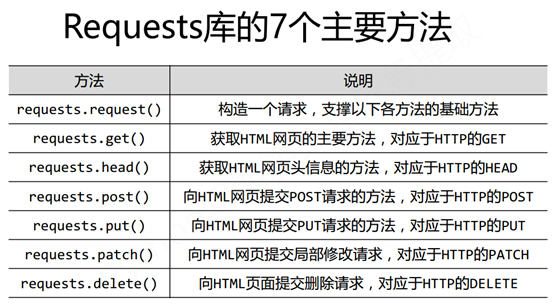
再看一遍Requests库的7个主要方法
其实,get()/post()/head()/put()/patch()/delete()方法,都可以用request方法来取代,其参数也大体相同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号