字典树知识梳理
字典树
字典树的介绍
字典树又名前缀树,是一种用树形结构实现的数据结构,可以高效地存储和检索集合中的数据
优点:
利用数据的公共前缀来减少查询时间,最大限度地减少无谓的比较
缺点:
字典树的核心思想是以空间换时间(有的时候可能会爆哦),数组要开a[最大能储存的结点数目][字符集大小(如26个小写字母就要开26)]
主要操作有插入和询问
字典树的性质
1.根节点不包含数据,除根节点以外的每个节点包含且只包含一个数据
2.数据是以边权的形式储存的

字典树的储存
看来上面的图,想必就会有读者问,1,2,6,11这几个结点中我是该取,a,ab,aba还是ba这类似的问题
俗话说办法总比困难多
于是某位大佬就相处在每个单词的结尾处做标记这个办法
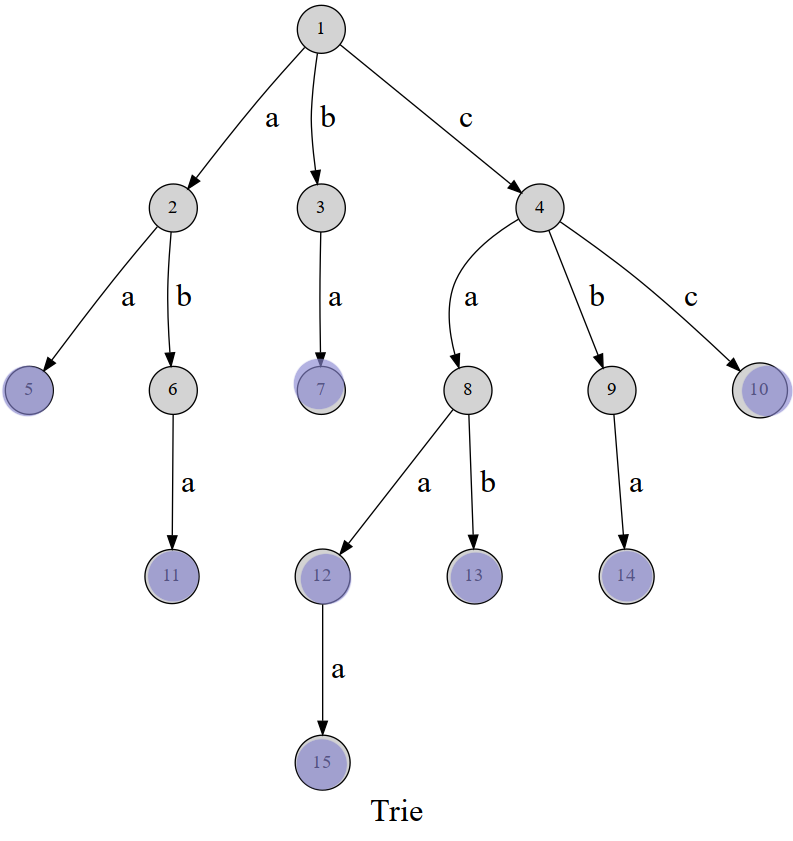
这样我们就知道树里面存的是aa,aba,ba,caa,caaa,cab,cba,cc,而不是其它的
实现
我们用两个数组
来记录每个单词的终结点
一个来记录字典树
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 2 | 5 | 7 | 8 | 11 | 12 | 14 | 15 | |||||||
| b | 3 | 6 | 9 | 13 | |||||||||||
| c | 4 | 10 |
来记录每个单词的终结点
代码
插入
void insert(char *s, int l) { // 插入字符串
int p = 0;
for (int i = 0; i < l; i ++) {
int c = s[i] - 'a';
if (!nex[p][c]) nex[p][c] = ++ cnt; // 如果没有,就添加结点
p = nex[p][c];
}
exist[p] = 1;//记录终结点
}
询问
bool find(char *s, int l) { // 询问字符串
int p = 0;
for (int i = 0; i < l; i++) {
int c = s[i] - 'a';
if (!nex[p][c]) return 0;
p = nex[p][c];
}
return exist[p];//返回终结点
}
完结撒花
欢迎大家留言
小编蒟蒻一个,有什么问题请大佬不惜赐教Orz


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器