
Redis笔记
1、单线程
2、Nosql(非关系型)
3、数据内存操作
4、常用数据类型:string、hash、list、set、zset,bitmap、hyperloglog
布隆过滤器:可以用很小的空间占用来记录海量数据,并查询某一数据是否存在,但是有一定误差,可以明确知道一个数据不存在,但不能明确知道一个数据一定存在。
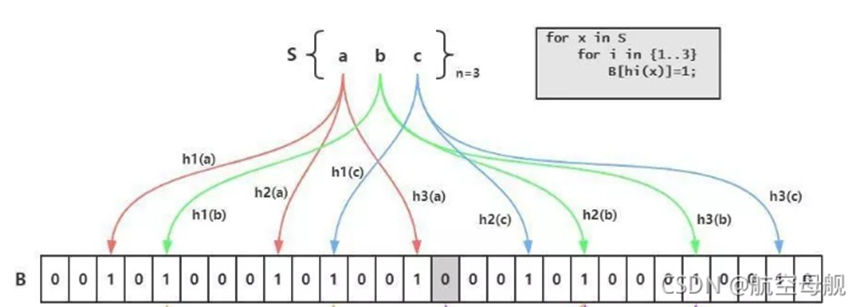
5、Hyperloglog:同样可以用很小的空间占用来统计基数(就是只能统计数量,而没办法去知道具体的内容是什么,比如在线用户数、注册 IP 数、每日访问 IP 数)
6、事务不能回滚,只能提交,普通事务没有隔离性,如果需要隔离性,可以使用watch(用于监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断)来监听,或者使用lua脚本,相当于数据库存储过程,整个lua脚本就是一个事务,高效方便。
7、持久化
1、 快照的方式(RDB),每次抓拍一下全面貌,有save(阻塞)、bgsave(另开线程)两种备份指令,备份慢,启动快
2、 文件追加方式(AOF),在之前的基础追加,备份快,启动慢
3、 混和模式,开启aof模式时,会自动开启混和模式。备份快、启动快,原理是,当我们进行aof操作的时候,把aof文件里的内容转成rdb格式, 之后的aof操作继续追加aof格式。
8、 Redis单独的主从结构只能实现读写分离,如果主节点挂了,不能自动切换。必须配套哨兵或者使用集群才能自动切换
9、 脑裂:主从模式加哨兵模式下,当某个主节点所在机器与其他从节点机器出现网络分区(网络不通),整个集群可能出现两个主节点。
10、 Redis集群默认使用哈希槽,共有16384个,如果某个主节点挂了,此时选举新的从节点为主节点,并不能保证数据的强一致性;如果某个主节点和所属从节点都挂了,整个服务不可用;使用{标识符}+key 操作的话,可以保证同个标识符的key分配在同一节点上。
11、Stackexchange、csredis.core客户端支持连接分片集群、servicestack客户端不支持分片集群的连接
12、碎片管理,可以直接重启redis,或者修改配置文件,配置项是当内存可使用率到达某个值,自动进行碎片整理
13、商品秒杀:Incr\decr:给提前写进的库存自增、自减,再配合消息队列异步处理订单
14、缓存雪崩:同一时间大量的key过期,导致大并发查询关系型数据库。解决方案是设置相同过期时间时加随机因子。
15、缓存穿透:key不存在redis也不存在关系型数据库里。可以使用布隆过滤器,将都不存在的key/id存进布隆过滤器,下次请求,如果该id在布隆过滤器里,则直接返回,相当于黑名单。
16、缓存击穿:key在关系型数据库里,不在redis里,可能时key过期了。可以给key不设置过期时间。
17、缓存预热:项目还没启动时,先把一些数据提前写进redis中
18、内存回收策略:默认不回收,当达到最大内存的时候,在增加新数据的时候会返回 error。可以设置根据过期时间、最长使用时间来删除数据。
19、因为单线程在处理客户端连接、读、写时会造成阻塞,所以采用多路复用机制。
1、一个 socket 客户端与服务端连接时,会生成对应一个套接字描述符(套接字描述符是文件描述符的一种),每一个 socket 网络连接其实都对应一个文件描述符。
2、多个客户端与服务端连接时,Redis 使用 「I/O 多路复用程序」(I/O多路复用程序函数有 select、poll、epoll、kqueue) 将客户端 socket 对应的 FD 注册到监听列表(一个队列)中。当客服端执行 read、write 等操作命令时,I/O 多路复用程序会将命令封装成一个事件,并绑定到对应的 FD 上。
例如:以 Redis 的 I/O 多路复用程序 epoll 函数为例
多个客户端连接服务端时,Redis
会将客户端 socket 对应的 fd 注册进 epoll,然后 epoll 同时监听多个文件描述符(FD)是否有数据到来,如果有数据来了就通知事件处理器赶紧处理,这样就不会存在服务端一直等待某个客户端给数据的情形。
3、「文件事件处理器」使用 I/O 多路复用模块同时监控多个文件描述符(fd)的读写情况,当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器进行处理相关命令操作。
4、整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD 读写的监控,当其中一个 client 端达到写或读的状态,文件事件处理器就马上执行,从而就不会出现 I/O 堵塞的问题,提高了网络通信的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号