
Java-Executor框架
Executor框架
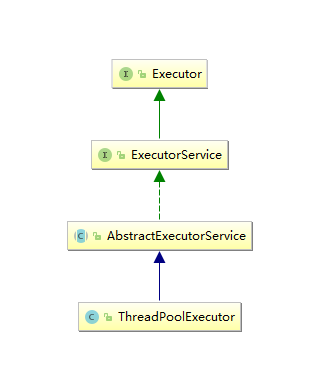
Executor的接口只有一个execute方法:
public interface Executor { void execute(Runnable command); }
可以像下面一样使用

public class TaskExecution { private static final int THREADS = 10; //可容纳10个线程的固定长度的线程池 private static final Executor exec = Executors.newFixedThreadPool(THREADS); public static void main(String[] args) { exec.execute(() -> { //.... } } }
Executors的静态工厂方法来创建线程池(例如,newFixedThreadPool的创建):Execotors里还有newCachedThreadPool、newSingleThreadExecutor、newScheduledThreadPool
newFixedThreadPool是固定长度的线程池;newCachedThreadPool可缓存的线程池,当超过规模是回收空闲线程,而当需求增加时,则可以添加新的线程,线程池规模不存在限制;newSingleThreadExecutor是一个单线程的Executor,创建单个工作者线程来执行任务;newScheduledThreadPool创建一个固定长度的线程池,而且以延迟或者定时的方式来执行任务。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
解释一下: 第一个nThreads是corePoolSize,核心线程池大小,保持存活的工作线程的最小数目,当小于corePoolSize时,会直接启动新的一个线程来处理任务,而不管线程池中是否有空闲线程;
第二个是maximumPoolSize,线程池中线程的最大数目
第三个是keepAliveTime,空闲线程的存活时间
第四个是时间的单位,毫秒,this.keepAliveTime = unit.toNanos(keepAliveTime),在ThreadPoolExecutor的构造器里转化为纳秒
第五个是工作队列,阻塞队列实现的
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler); } public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.acc = System.getSecurityManager() == null ? null : AccessController.getContext(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }
ExecutorService的生命周期:运行、关闭、中止
public interface ExecutorService extends Executor { void shutdown(); List<Runnable> shutdownNow(); boolean isShutdown(); boolean isTerminated(); boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException; }
shutdown():执行平缓的关闭过程,不在接受新任务,等已提交的任务执行完成
shutdownNow():尝试取消正在执行的任务,不再启动队列里未开始的任务
awaitTermination:可以等待ExecutorService达到中止状态,也可以通过isTerminated来轮询
延时任务与周期任务
以前说到延时任务只想到Timer,现在知道了一个ScheduleThreadPoolExecutor,可以用ScheduleExecutorService或者ScheduleThreadPool的schedule()方法
说说为什么要用ScheduleThreadPoolExecutor而不是Timer把:
1.Timer只有一个线程,如果TimerTask执行时间大于周期,那么在一个任务结束后可能快速调用好几次等着的任务或者丢失执行期间的任务
2.如果TimerTask抛出一个为检查的异常,但是Timer线程不捕获,然后出了错Timer认为整个Timer被取消了,而不是恢复线程
携带结果的Callable和Future
Runnable的缺点:Runnable不能返回一个值或者抛出一个受检异常
这是一个ExecutorService接口的submit抽象方法:
Future<?> submit(Runnable task);

Future表示一个任务的生命周期,并提供了相应的方法来判断是否已经完成或取消,以及获取任务的结果和取消任务等。在将Runnable或Callable提交到Executor的过程中,包含了一个安全发布的过程,类似的,设置Future结果的过程中也包含了一个安全发布。
get方法有两个,第一个就是没完成一直阻塞着,第二种就是设置了任务时限,超时还没完成的会抛出TimeoutException异常,可以捕获他然后做处理。
CompletionService:
一个栗子:
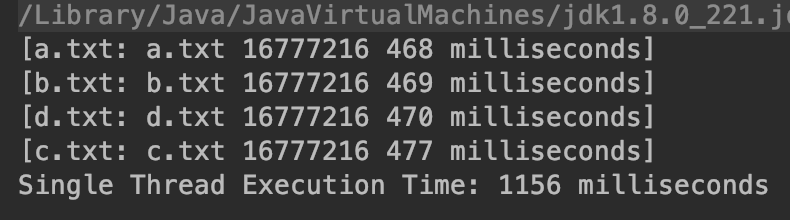
import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.util.concurrent.*; public class CompletionServiceAndBlockingQueueTest { private static final String[] files = {"a.txt", "b.txt", "c.txt", "d.txt"}; private static final ConcurrentHashMap<String, String> map = new ConcurrentHashMap<String, String>(); private static final ExecutorService executor = Executors.newFixedThreadPool(files.length); private static final CompletionService<String> completionService = new ExecutorCompletionService<String>(executor); public static void main(String[] args) { for (String s : files) { // 交给线程池 completionService.submit(() -> countStringLength(s)); } try { for (int i = 0; i < files.length; i++) { // 通过阻塞队列实现的,当任务完成时可以获得到结果,否则阻塞 Future<String> future = completionService.take(); String fileName = future.get(); System.out.println("[" + fileName + ": " + map.get(fileName) + "]"); } } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } // 主线程里做 long startTime = System.currentTimeMillis(); for (String s : files) { countStringLength(s); } System.out.println("Single Thread Execution Time: " + (System.currentTimeMillis() - startTime) + " milliseconds"); } private static String countStringLength(String s) { int count = 0; long startTime = System.currentTimeMillis(); long endTime; try (FileReader fileReader = new FileReader(s); BufferedReader reader = new BufferedReader(fileReader)) { String temp; while ((temp = reader.readLine()) != null) { count += temp.length(); } } catch (FileNotFoundException fe) { fe.printStackTrace(); } catch (IOException ie) { ie.printStackTrace(); } finally { endTime = System.currentTimeMillis(); String result = s + " " + count + " " + (endTime - startTime) + " milliseconds"; map.put(s, result); } return s; } }
结果:执行的时间和cpu数和硬盘是有关系的
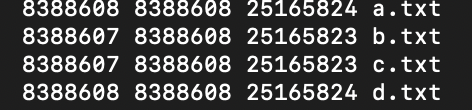
shell: wc *.txt
参考: 《Java并发编程实战》

