深入理解 Docker 核心原理:Namespace、Cgroups 和 Rootfs
![]()
通过这篇文章你可以了解到 Docker 容器的核心实现原理,包括 Namespace、Cgroups、Rootfs 等三个核心功能。
如果你对云原生技术充满好奇,想要深入了解更多相关的文章和资讯,欢迎关注微信公众号。
搜索公众号【探索云原生】即可订阅
后续文章会演示如何从零实现一个简易的 Docker,这里先简单了解下 Docker 的核心原理。
首先我们思考一个问题:容器与进程有何不同?
进程:就是程序运行起来后的计算机执行环境的总和。
即:计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。
容器:核心就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。
对于 Docker 等大多数 Linux 容器来说,Cgroups 技术是用来制造约束的主要手段,而 Namespace 技术则是用来修改进程视图的主要方法。
1. 基于 Namespace 的视图隔离
当我们通过 docker run -it 启动并进入一个容器之后,会发现不论是进程、网络还是文件系统,好像都被隔离了,就像这样:
[root@docker cpu]# docker run -it busybox
/ #
/ # ps
PID USER TIME COMMAND
1 root 0:00 sh
7 root 0:00 ps
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
120: eth0@if121: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
/ # ls
bin dev etc home lib lib64 proc root sys tmp usr var
- ps 命令看不到宿主机上的进程
- ip 命令也只能看到容器内部的网卡
- ls 命令看到的文件好像也和宿主机不一样
这就是 Docker 核心之一,借助 Linux Namespace 技术实现了视图隔离。
看起来容器和宿主机隔离开了
在 Linux 下可以根据隔离的属性不同分为不同的 Namespace :
- 1)PID Namespace
- 2)Mount Namespace
- 3)UTS Namespace
- 4)IPC Namespace
- 5)Network Namespace
- 6)User Namespace
通过不同类型的 Namespace 就可以实现不同资源的隔离,比如前面通过 ip a 只能看到容器中的网卡信息,就是通过 Network Namespace进行了隔离。
不过 Linux Namespace 技术实际上修改了应用进程看待整个计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容。
我们只需要进入到对应 namespace 就可以突破这个隔离了,演示一下:
首先启动一个 busybox,然后使用 ip a 查看网卡信息
[root@docker ~]# docker run --rm -it busybox /bin/sh
/ #
/ # ip a show eth0
116: eth0@if117: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
容器中 ip 为 172.17.0.2
然后在新终端中通过 nsenter 进入到该容器 network namespace 试试:
首先通过 docker inspect 命令找到容器对应的 PID
[root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
75e821d24261 busybox "/bin/sh" 32 seconds ago Up 31 seconds great_heisenberg
[root@docker ~]# docker inspect -f '{{.State.Pid}}' 75e821d24261
3533
然后使用 nsenter --net 命令进入该 PID 对应进程的 network namespace
[root@docker ~]# nsenter --target 3533 --net
[root@docker ~]# ip a show eth0
116: eth0@if117: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
可以看到,此时我们执行 ip a 拿到的信息和在容器中执行是完全一致的。
说明 Docker 确实是使用 namespace 进行隔离的。
这里顺便提一下 Namespace 存在的问题,Namespace 最大的问题就是隔离得不彻底。
- 首先,既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
所以,也出现了像 Firecracker、gVisor、Kata 之类的沙箱容器,不使用共享内核来提升安全性。
- 其次,在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:时间。
容器中修改了时间,实际修改的是宿主机的时间,会导致所有容器时间都被修改,因为是共享的。
2. 基于 Cgroups 的资源限制
docker run 启动容器时可以通过增加 --cpus 或者 --memory flag 来指定 cpu、内存限制。
就像这样:通过 --cpus=0.5 限制只能使用 0.5 个核心,然后执行一个 while 死循环,并查看 cpu 占用情况。
[root@docker ~]# docker run -d --cpus 0.5 busybox sh -c "while true; do :; done"
d281fb2dc96cff371e9607197502c6ea3e04f4d0f3fd2ad38991c2321271736b
查看 CPU 占用情况
[root@docker ~]# top
top - 15:38:20 up 286 days, 4:02, 3 users, load average: 0.72, 0.46, 0.36
Tasks: 96 total, 2 running, 48 sleeping, 0 stopped, 0 zombie
%Cpu(s): 52.0 us, 0.0 sy, 0.0 ni, 47.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.3 st
KiB Mem : 1006956 total, 157876 free, 201008 used, 648072 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 538972 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3763 root 20 0 4392 400 336 R 50.0 0.0 0:49.43 sh
3790 root 20 0 162112 4416 3724 R 0.3 0.4 0:00.01 top
1 root 20 0 43884 4280 2552 S 0.0 0.4 1:56.18 systemd
可以看到,因为限制了 cpu 为 0.5,因此只占用了 0.5 核心,也就是 top 命令中看到的 50。
这就是 Docker 另一个核心功能,基于 Linux Cgroups 技术实现的资源限制。
Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。
Linux Cgroups 的全称是 Linux Control Group。
它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下,可以使用
mount -t cgroup 命令进行查看,大概长这样:
[root@docker ~]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
可以看到,在/sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。
即:这台机器当前可以被 Cgroups 进行限制的资源种类。
比如,对 CPU 子系统来说,我们就可以看到如下几个配置文件:
[root@docker ~]# ls /sys/fs/cgroup/cpu
cgroup.clone_children cgroup.sane_behavior cpuacct.stat cpuacct.usage_all cpuacct.usage_percpu_sys cpuacct.usage_sys cpu.cfs_period_us cpu.rt_period_us cpu.shares docker release_agent tasks
cgroup.procs cpuacct.usage cpuacct.usage_percpu cpuacct.usage_percpu_user cpuacct.usage_user cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat notify_on_release system.slice user.slice
这些配置文件定义了如何对 CPU 进行限制,以及需要对哪些进程进行限制。
那么配置文件又如何使用呢?下面我们来演示一下具体使用。
例子:限制 CPU 使用
你需要在对应的子系统下面创建一个目录,比如,我们现在进入 /sys/fs/cgroup/cpu 目录下创建一个名为 container 的目录:
[root@docker ~]# cd /sys/fs/cgroup/cpu
[root@docker cpu]# mkdir container
这个目录就是一个“控制组”。
你会发现,操作系统会在你新创建的 container 目录下,自动生成该子系统对应的资源限制文件。
[root@docker cpu]# ls container
cgroup.clone_children cpuacct.stat cpuacct.usage_all cpuacct.usage_percpu_sys cpuacct.usage_sys cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.procs cpuacct.usage cpuacct.usage_percpu cpuacct.usage_percpu_user cpuacct.usage_user cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
接下来我们就通过修改配置文件对 CPU 进行限制,这里就用前面创建的 container 这个“控制组”。
主要通过以下三个文件来实现
- cpu.cfs_quota_us:每个控制周期内,进程可以使用的 cpu 时间,默认为 -1,即不做限制。
- cpu.cfs_period_us:控制周期,默认为 100 ms
- tasks:记录被限制进程的 PID 列表
cgroups 会限制所有在 tasks 中的进程,在 cpu.cfs_period_us 周期内,最多只能使用 cpu.cfs_quota_us 的 cpu 资源。
比如,100ms 能限制只能使用 20ms,即最多占用 0.2 核心
首先,我们在后台执行这样一条脚本:
[root@docker cpu]# while : ; do : ; done &
[1] 3892
显然,它执行了一个死循环,可以把计算机的 CPU 吃到 100%。根据它的输出,我们可以看到这个脚本在后台运行的进程号(PID)是 3892。
执行 Top 查看一下 CPU 占用,可以看到这个 3892 进程占用了差不多 100% 的 CPU,把一个核心占满了。
[root@docker cpu]# top
top - 16:07:06 up 286 days, 4:31, 3 users, load average: 0.59, 0.50, 0.50
Tasks: 97 total, 2 running, 48 sleeping, 0 stopped, 0 zombie
%Cpu(s):100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1006956 total, 166520 free, 190840 used, 649596 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 549216 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3892 root 20 0 115684 532 0 R 92.0 0.1 0:48.64 bash
此时,我们就可以通过配置 cgroups 来实现对该进程的 CPU 使用情况进行限制。
默认情况下 container 控制组里的 CPU quota 还没有任何限制(即:-1),CPU period 则是默认的 100 ms(100000 us),因此上述进程可以占用整个 CPU。
[root@docker cpu]# cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
-1
[root@docker cpu]# cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
100000
接下来,我们可以通过修改这配置文件来设置 CPU 限制。比如,向 container 组里的 cfs_quota 文件写入 20 ms(20000 us)来做限制。
[root@docker cpu]# echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
[root@docker cpu]# cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
20000
最后则是将进程 PID 写入 tasks 文件里,是配置生效。
[root@docker cpu]# echo 3892 > /sys/fs/cgroup/cpu/container/tasks
[root@docker cpu]# cat /sys/fs/cgroup/cpu/container/tasks
3892
然后查看是否生效:
[root@docker cpu]# top
top - 16:13:56 up 286 days, 4:38, 3 users, load average: 0.20, 0.61, 0.59
Tasks: 94 total, 2 running, 48 sleeping, 0 stopped, 0 zombie
%Cpu(s): 21.6 us, 0.0 sy, 0.0 ni, 78.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.3 st
KiB Mem : 1006956 total, 166552 free, 190808 used, 649596 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 549248 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3892 root 20 0 115684 532 0 R 19.9 0.1 5:56.94 bash
可以看到,果然 3892 CPU 被限制到了 20%。
除 CPU 子系统外,Cgroups 的每一个子系统都有其独有的资源限制能力,比如:
- blkio,为块设备设定I/O 限制,一般用于磁盘等设备;
- cpuset,为进程分配单独的 CPU 核和对应的内存节点;
- memory,为进程设定内存使用的限制。
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。
而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
而至于在这些控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定了,比如这样一条命令:
docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
在启动这个容器后,我们可以通过查看 Cgroups 文件系统下,CPU 子系统中,“docker”这个控制组里的资源限制文件的内容来确认:
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us
20000
3. 容器镜像的秘密
这部分主要解释以下三个问题
- 1)为什么在容器中修改了文件宿主机不受影响?
- 2)容器中的文件系统是哪儿来的?
- 3)docker 镜像又是怎么实现的?
这也是 Docker 的第三个核心功能:容器镜像(rootfs),将运行环境打包成镜像,从而避免环境问题导致应用无法运行。
1. 文件系统
容器中的文件系统是什么样子的?
因为容器中的文件系统经过 Mount Namespace 隔离,所以应该是独立的。
其中 Mount Namespace 修改的,是容器进程对文件系统“挂载点”的认知。只有在“挂载”这个操作发生之后,进程的视图才会被改变。而在此之前,新创建的容器会直接继承宿主机的各个挂载点。
不难想到,我们可以在容器进程启动之前重新挂载它的整个根目录“/”。而由于 Mount Namespace 的存在,这个挂载对宿主机不可见,所以容器进程就可以在里面随便折腾了。
Linux 中 chroot 命令(change root file system)就能很方便的完成上述工作。
而 Mount Namespace 正是基于对 chroot 的不断改良才被发明出来的,它也是 Linux 操作系统里的第一个 Namespace。
至此,第一个问题 为什么在容器中修改了文件宿主机不受影响?有答案了,因为使用 Mount Namespace 隔离了。
2. rootfs
上文提到 Mount Namespace 会修改容器进程对文件系统挂载点的认知,而这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。
rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。在 Linux 操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本的内核镜像。
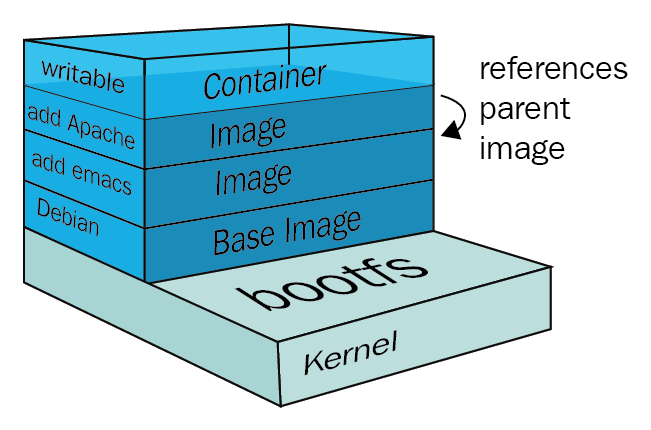
所以说,rootfs 只包括了操作系统的“躯壳”,并没有包括操作系统的“灵魂”。实际上,同一台机器上的所有容器,都共享宿主机操作系统的内核。
这也是容器相比于虚拟机的主要缺陷之一:毕竟后者不仅有模拟出来的硬件机器充当沙盒,而且每个沙盒里还运行着一个完整的 Guest OS 给应用随便折腾。
不过,正是由于 rootfs 的存在,容器才有了一个被反复宣传至今的重要特性:一致性。由于 rootfs 里打包的不只是应用,而是整个操作系统的文件和目录,也就意味着,应用以及它运行所需要的所有依赖,都被封装在了一起。
第二个问题:容器中的文件系统是哪儿来的?实际上是我们构建镜像的时候打包进去的,然后容器启动时挂载到了根目录下。
3. 镜像层(Layer)
Docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。
通过引入层(layer)的概念,实现了 rootfs 的复用。不必每次都重新创建一个 rootfs,而是基于某一层进行修改即可。
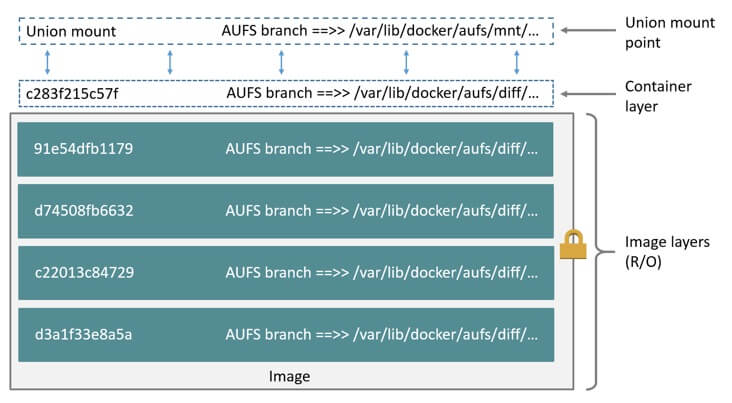
Docker 镜像层用到了一种叫做联合文件系统(Union File System)的能力。Union File System 也叫 UnionFS,最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下。
例如将目录 A 和目录 B 挂载到目录 C 下面,这样目录 C 下就包含目录 A 和目录 B 的所有文件。
由于看不到目录 A 和 目标 B 的存在,因此就好像 C 目录就包含这么多文件一样
Docker 镜像分为多个层,然后使用 UFS 将这多个层挂载到一个目录下面,这样这个目录就包含了完整的文件了。
UnionFS 在不同系统有各自的实现,所以 Docker 的不同发行版使用的也不一样,可以通过 docker info 查看。常见有 aufs(ubuntu 常用)、overlay2(centos 常用)
就像下图这样:union mount 在最上层,提供了统一的视图,用户看起来好像整个系统只有一层一样,实际上下面包含了很多层。
镜像只包含了静态文件,但是容器会产生实时数据,所以容器的 rootfs 在镜像的基础上增加了可读写层和 Init 层。
即容器 rootfs 包括:只读层(镜像rootfs)+ init 层(容器启动时初始化修改的部分数据) + 可读写层(容器中产生的实时数据)。
只读层(镜像rootfs)
它是这个容器的 rootfs 最下面的几层,即镜像中的所有层的总和,它们的挂载方式都是只读的(ro+wh,即 readonly+whiteout)
可读写层(容器中产生的实时数据)
它是这个容器的 rootfs 最上面的一层,它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。
而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中,删除操作实现比较特殊(类似于标记删除)。
AUFS 的 whiteout 的实现是通过在上层的可写的目录下建立对应的 whiteout 隐藏文件来实现的。
为了实现删除操作,aufs(UnionFS 的一种实现) 会在可读写层创建一个 whiteout 文件,把只读层里的文件“遮挡”起来。
比如,你要删除只读层里一个名叫 foo 的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo 的文件。这样,当这两个层被联合挂载之后,foo 文件就会被.wh.foo 文件“遮挡”起来,“消失”了。
init 层(容器启动时初始化修改的部分数据)
它是一个以“-init”结尾的层,夹在只读层和读写层之间,Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
为什么需要 init 层?
比如 hostname 这样的数据,原本是属于镜像层的一部分,要修改的话只能在可读写层进行修改,但是又不想在 docker commit 的时候把这些信息提交上去,所以使用 init 层来保存这些修改。
可以理解为提交代码的时候一般也不会把各种配置信息一起提交上去。
docker commit 只会提交 只读层和可读写层。
最后一个问题:docker 镜像又是怎么实现的?通过引入 layer 概念进行分层,借助 联合文件系统(Union File System)进行叠加,最终构成了完整的镜像。
这里只是镜像的主要内容,具体怎么把这些内容打包成 image 格式就是 OCI 规范了
4. 小结
至此,我们大致清楚了 Docker 容器的实现主要使用了如下 3 个功能:
- 1)Linux Namespace 的隔离能力
- 2)Linux Cgroups 的限制能力
- 3)基于 rootfs 的文件系统
如果你对云原生技术充满好奇,想要深入了解更多相关的文章和资讯,欢迎关注微信公众号。
搜索公众号【探索云原生】即可订阅
5. 参考
https://draveness.me/docker/
https://en.wikipedia.org/wiki/Linux_namespaces
https://0xax.gitbooks.io/linux-insides/content/Cgroups/linux-cgroups-1.html
https://coolshell.cn/articles/17061.html
深入剖析Kubernetes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号