
OFcms代码审计
1|0前言
今天看到一篇审计Java的文章,于是在没有继续系统学习基础的情况下,又一次当其搬运工,打算熟悉熟悉java项目搭建流程,然后再跟着过一下Java代码审计流程,全文除搭建的坑,其余漏洞代码分析均CV大佬思路。。。
2|0环境搭建
- 源码地址:https://gitee.com/oufu/ofcms
- 环境依赖:
a. 建议采用 idea 工具开发
b. mysql 5.6+
c. jdk 1.8
d. tomcat 8 5.通过war包直接放TOMCAT下面 到附件中下载
e. phpstudy
2|1大致安装步骤:
- 首先就是直接用idea打开下载好的源码文件
- 然后将ofcms-master\ofcms-master\ofcms-admin\src\main\resources\dev\conf目录下的db-config.properties 改成db.properties 修改数据库连接
- 修改db.properties中的数据库密码为本地设置的mysql密码
- 配置好数据库后,先用IDEA中的数据连接插件Database Navigator测试数据库连通性(插件安装步骤见:https://blog.csdn.net/Liu_wen_wen/article/details/125958039)
- 安装成功后,在视图->工具窗口中选中DB Browser,配置本地数据库用户名密码



- 连接成功后返回数据表项

- 安装Maven依赖,这个其实在你打开项目的时候,idea就自动检测了,一般等他下载完就可以了
- 这里要是下载太慢可以配置阿里加速源
- 若是使用 IDEA 自带的 maven,从 IDEA 所在目录开始:IntelliJ IDEA\plugins\maven\lib\maven3\conf\settings.xml。若是自己下载的 maven 则从 IDEA 所在目录开始:maven的安装目录\conf\settings.xml。
- 将其中的 url 进行修改。(可用 ctrl + F 进行直接搜索)

-
安装tomcat,社区版不自带这个,我之前是装了smart tomcat,这里直接在设置->插件中下载就行,下载好,重启idea就行,就会在设置界面中多一个tomcat server

-
配置tomcat

-
选择好之后,进行部署到ofcms-admin

-
全部完成后,就可以构建项目了,项目构建成功后,访问http://localhost:8080/ofcms-admin/即可以安装
-
这里还有几个坑,要是在本地的phpstudy中使用mysql,直接导入ofcms-V1.1.3\doc\sql\ofcms-v1.1.3.sql文件,再重启即可
-
然后刷新页面即安装成功
-
PS:构建过程中若出现junit缺少jar包,在文件->项目结构->库中点击加号,然后弹出对话框,选择Java,找到idea的安装目录lib下,选择junit的jar包,选择junit.jar,然后重新构建即可

3|0漏洞审计复现
3|1任意文件读取
漏洞分析
这个文件的getTemplates函数,可以看到从前台获取dir、up_dir、res_path值,直接把dir拼接到pathfile,并未对其处理,直接获取pathfile目录下的所有目录dirs和文件files,但是获取的文件后缀只能是html、xml、css、js
这里先看一下java的文件拼接
示例代码如下:
找了一个在线平台(https://www.bejson.com/runcode/java/)运行一下后,发现File类,会直接拼接路径
public File(String parent,String child) 以parent为父路径,child为子路径创建File对象。
进而在从前台获取file_name参数,默认为index.html,再判断files是否为空,如果不为空,循环所有文件files和file_name进行对比,有则返回该文件,无则返回所有文件files的第一个文件,最终读取该文件内容
复现

3|2任意文件写入
漏洞分析
文件位置:
ofcms-admin/src/main/java/com/ofsoft/cms/admin/controller/cms/TemplateController.java
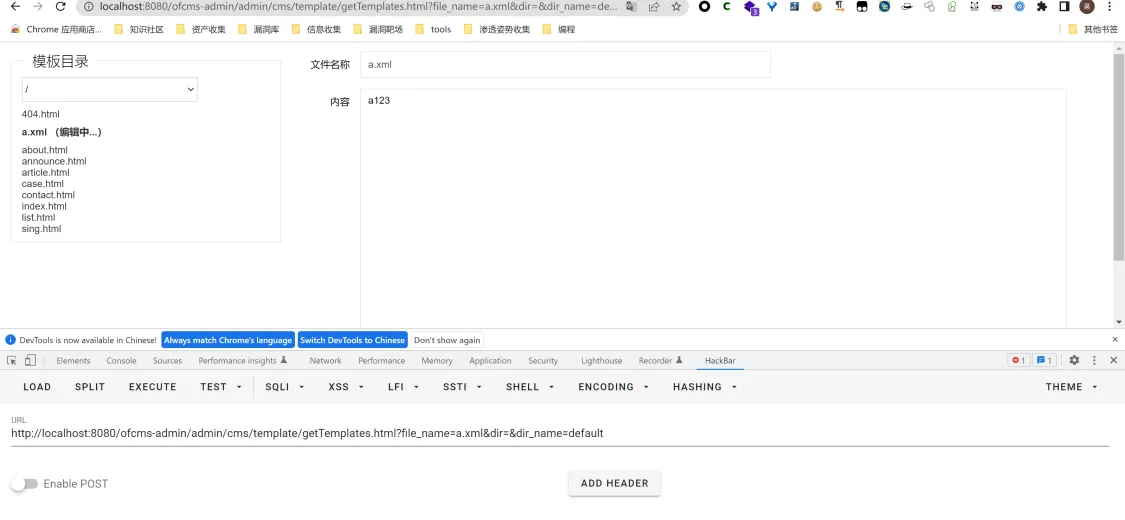
在TemplateController.java文件里的save函数,从前台主要获取file_name、file_content两个参数,可以发现该函数的file_name是直接和pathfile目录拼接上的,所以是可以路径穿越的,导致文件可以写到任意位置下
复现
在admin目录下写一个a.xml,默认会写在根目录下:

这里在写入完文件后,会发现全局也搜不到文件位置,但是又显示处理成功,那么为了能验证效果,这里要配合一下上面的任意文件读取,这也就是为什么要创建一个.xml文件的原因
3|3模板注入(危害程度不大,仅能影响自己系统)
漏洞分析
在后台的模板管理处,可以直接修改模板语句导致模板注入

直接在index.html中插入如下语句:
<#assign ex="freemarker.template.utility.Execute"?new()> ${ ex("calc") }

然后访问首页

3|4SQL注入
漏洞分析
文件位置
ofcms-admin/src/main/java/com/ofsoft/cms/admin/controller/system/SystemGenerateController.java
漏洞代码:
这里直接获取到sql参数后,直接执行update,没有经过任何过滤
跟了一下函数实现,发现也是直接使用的executeUpdate()
复现
payload:sql=update of_cms_ad set ad_id=updatexml(1,concat(1,user()),1)

3|5任意文件上传
漏洞分析
文件位置:ofcms-admin/src/main/java/com/ofsoft/cms/admin/controller/ComnController.java
这个文件下的ComnController.java、UeditorAction.java文件,其中的upload、editUploadImage、uploadImage、uploadFile、uploadVideo和uploadScrawl函数都是可以进行上传的,可以看到用的都是getFile函数:
- 漏洞代码(ComnController.java)
先看一下upload函数,其中getFile函数先获取文件和上传路径,然后创建新文件,跟一下getFile函数
这里又用getFiles处理上传路径,然后返回文件名,继续跟一下getFiles函数
这里if判断请求类型不是MultipartRequest后会用MultipartRequest继续处理请求和上传路径,那么再继续跟一下MultipartRequest
这里先调用了父类的构造方法,然后又调用wrapMultipartRequest处理请求和文件上传路径,继续跟一下wrapMultipartRequest
这里可以看到详细的文件上传时文件处理了,先是根据给出的上传路径创建目录路径,会事先判断目录是否存在或者是否可以创建,全都满足后,即可进入下一步判断文件名是否为空,最后在进入isSafeFile函数进行文件类型判断,所以这里再跟一下isSafeFile函数
这里先将文件名转为小写,然后判断是否为jsp和jspx后缀,若是则删除文件,所以这里应该是要绕过的,但是这里我们可以利用Windows或中间件文件上传特性来避免结尾为jsp或jspx
复现
漏洞路径http://localhost:8080/ofcms-admin/admin/comn/service/upload
随意找一下一个上传路径

然后抓包

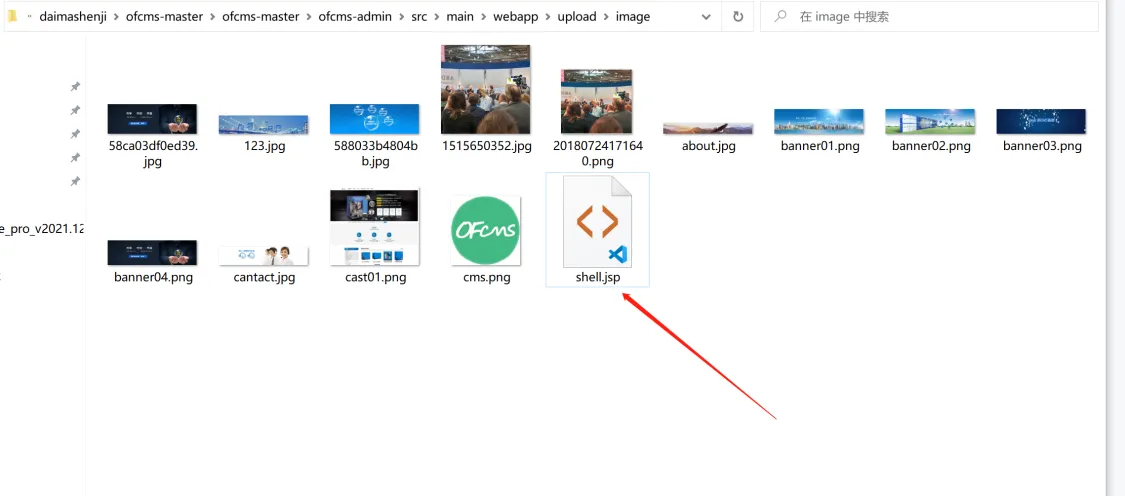
改为image/jpg,并且文件名后多加一个点,即为shell.jsp.,即可以上传成功

到文件路径下查看
本来想用冰蝎连一下,发现连不了,最后在参考文章的最后看到了这样一句话,关于上传jsp文件为什么执行不了——是因为存在jfinal过滤器,所以没有办法传上去。
3|6XXE漏洞
漏洞分析
文件位置:ofcms-admin\src\main\java\com\ofsoft\cms\admin\controller\ReprotAction.java
其中的expReport方法
getParamsMap() 有传参
后边将输入的值传递给 hm 和 jrxmlFileName
服务器接收用户输入的j参数后,拼接生成文件路径,这里没有进行过滤,可以穿越到其它目录,但是限制了文件后缀为jrxml。
定位 getParamsMap()方法 没有过滤
接下来会调用JasperCompileManager.compileReport()方法,跟进该方法看看
在compileReport方法中又调用了JRXmlLoader.load()方法,继续跟踪
复现
复现锤子啊,这个xxe貌似是旧版本的,新版本的compileReport函数已经被修复了。
4|0小结
整体上说算是完整的搭建和跟了一遍整体代码,发现对很多java的基本函数了解程度还是不够,需要继续进一步学习,其中有部分漏洞算是自己重新分析了一下,其他的就是跟这个大佬的文章复现的。这个cms应该还是有很多洞的,等把炼石计划的java基础学完,再继续重新分析一波吧,尽请期待OFcms代码审计(二)!!!无限期拖更!!!
__EOF__

本文链接:https://www.cnblogs.com/Konmu/p/18460151.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)