
Centos7+Python+selenium+geckodriver+firefox 实现自动定时打卡
前言
- 失踪人口回归啦,考研终于结束了,也划了好几天水,由于现在疫情反扑,加上寒假开始了,这几天又被天天催着打卡,于是就打算直接写一个自动化脚本直接在服务端自动运行岂不美哉
环境准备
Centos7服务器一台python 3.7.2selenuim模块geckodriver驱动firefox浏览器
脚本实现
大致实现简介
- 首先我们回想一下自己平时登录打卡的操作,要先去登录校园网,然后点击健康打卡,而这次实现自动打卡是基于
Python3的selenuim模块实现的,这个模块可以模拟打开浏览器的操作,然后通过解析网页首页html和js来完成操作。
selenuim模块安装
- 直接
pip install selenuim即可 - 模拟打开浏览器
driver=webdriver.Firefox()
driver.get("https://baidu.com")
print(dirver.title)
安装geckodriver
- 这个是火狐的
webdriver,由于我是用火狐模拟的,所以选择下的是这个,大家也可以去下载chrome的
linux 下:
wget https://github.com/mozilla/geckodriver/releases/download/v0.29.0/geckodriver-v0.29.0-linux64.tar.gz
tar -zxvf geckodriver-v0.29.0-linux64.tar.gz
mv geckodriver /usr/local/bin
Windows下:直接下载驱动,然后使用win+R,输入cmd调出控制台,然后输入where Python3查看一下它的存放路径,然后找到Script目录,将驱动置于此目录下即可
firefox安装
Windows下由于可以使用图形化界面,直接安装firefox浏览器即可,这里就不再多做赘述Linux下由于我想部署在服务器上,这样就可以一直自动运行,而不需要像Windows中每次只有开机和联网后他才能运行。但是这也带来了一系列问题,首先命令行界面的服务器是无法像Windows中那样打开浏览器,使用图形化操作的,所以我们这里就要提到一个解决方案,使用无界面的firefox- 有两种可以解决的方法不过
Python3.7以上的推荐使用第二种: - 1、第一种:使用
phantomJS配合selenium,不过由于Python37已经抛弃对于phantomJS的更新,所以我们运行时会遇到如下警告

- 这就再告诉我们他已经新版的
selenium不支持phantomJS,推荐使用无界面的firefox或者Chrome,不过这里也就只是警告而且,其实还是可以正常返回数据的,不过不是很推荐使用了 - 2、第二种:就是按他推荐使用的无界面的
firefox或者Chrome,但是服务器没事哪来的firefox,这就要我们安装一下,一条命令解决centos下: yum install firefox -y,然后使用以下代码实现无头模式:
foptions = webdriver.FirefoxOptions()
foptions.set_headless(headless=True) #新版的headless要设置参数headless=True
foptions.add_argument('--disable-gpu')
driver=webdriver.Firefox(options=foptions)#新版用options代换了firefox_options
具体脚本编写思路(windows端,linux端代码想要的可以私聊我,这里就不贴出来了)
- 首先我们要使用
selenuim模拟打开浏览器,然后载入URL,访问校园网
driver=webdriver.Firefox()
driver.get("https://cas.v.just.edu.cn/cas/login?service=http%3A%2F%2Fmy.just.edu.cn%2F")
- 模拟登录,这里就要查看网页源码来审查元素,可以使用
F12调出控制台,然后定位元素,如下图输入用户名的地方可以通过id=username来定位,同样的方法可以定位到输入密码的位置,而在代码实现时要通过函数find_element_by_id()来实现
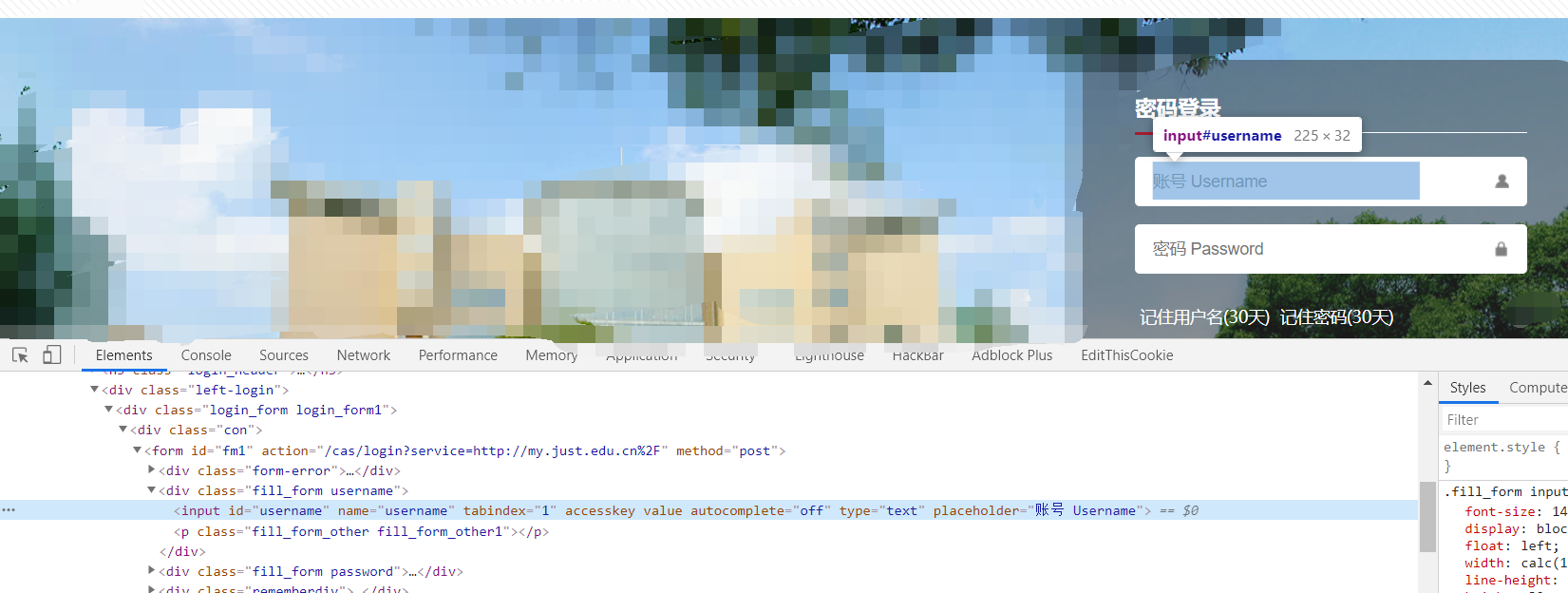
- 定位好用户名,密码输入的后,就要使用
send_keys()函数向服务端发送数据
driver.find_element_by_id("username").send_keys("username")
driver.find_element_by_id("password").send_keys("password")
driver.find_element_by_id("passbutton").click() # 点击提交,由于我学校网站写的比较简单,前端直接通过id就能定位,所以这里还是使用的id定位,其他方式还可以通过name,classname或者xpth(这种最准确)来完成
- 完成登录操作之后,我们就要进行健康信息填报操作了,我这里直接去了个巧,直接先重启一个页面,然后直接访问健康表来完成填报,就没去在模拟点击操作了
now_handle=driver.current_window_handle
driver.switch_to.window(now_handle)
driver.get("https://ec43d80978edf4f14590b58d041fc8baids.v.just.edu.cn/default/work/jkd/jkxxtb/jkxxcj.jsp")
- 信息填报,由于大部分固定好的信息一次填报后就不需要在二次填报,所以就减轻了我们的工作量,就只有仅仅五六项需要我们去操作,但是在完成填报时,又遇到了新的问题,之前填报登录信息时,我们通过简单的定位
id,然后send_keys就能完成,但是这里我发现,有许多地方他不是再简单的直接将js写在页面中,而是通过调用外部的脚本实现,所以这里就要用到新的方法来实现,通过页面执行js,然后在使用execute_script函数执行js函数即可完成,代码如下:
# 14天内是否接触(jc)海外归国人员:
jc = 'document.getElementsByClassName("iCheck-helper")[16].click()'
driver.execute_script(jc)
# 今日是否经过或滞留中高风险(gfx)地区:
gfx = 'document.getElementsByClassName("iCheck-helper")[24].click()'
driver.execute_script(gfx)
# 昨晚体温
driver.find_element_by_id("input_zwtw").send_keys("36.1")
# 今晨体温
driver.find_element_by_id("input_tw").send_keys("36.1")
sleep(5)
# 今日逗留地址
driver.find_element_by_xpath("//*[@id=\"input_jrjzdxxdz\"]").send_keys("学校")
- 执行
sleep(5)的解释:执行过程中,发现又出现一个问题,就是我们输入完数据后,点击提交,发现他始终说我们没提交完,但是我们明明全填好了啊!!!!这时候就祭出我的vscode大杀器,开始调试,发现断点设置再提交的时候,过了一会再提交,发现提交成功,然后再去看了一眼驱动的日志发现如下一句话

- 个人理解貌似是我们执行点击操作的时候太快了,数据还没来得及传输到服务端,我们就完成了点击操作导致的,所以这里一定要先去设置一下延时
5s执行,就可以避免如此问题了 - 选择按钮的选取,由于页面设置了许多按钮选项,遂查看源码后发现,均是基于
classname来分类的,而且有明确编号,所以我们直接采用document.getElementsByClassName("iCheck-helper")[16]逐一遍历,然后执行点击操作即可 - 当所有数据,填好要点提交的时候,我原本还是想直接通过
xpath(这里提供一种准确获取xpath的方法:进入控制台后,选中源码,右键就会发现一个copy xpath)或者id的方法完成点击操作,但是,试了半天都没有成功,于是再次查看源码后发现了原来他是通过事件监听器实现点击操作的,所以我们原本的方法又失效了,这次就还是要通过调用执行js的方法来完成,代码如下:
def click_js():
js = 'document.getElementsByClassName("btn btn-primary obtn")[0].click()'
driver.execute_script(js)
- 至此,信息填报就完成了
- 剩下的我们就要直接去Windows的计划任务中设置一个定时执行就可以了
windows端完整代码:
from selenium import webdriver
from time import sleep
driver=webdriver.Firefox()
driver.get("https://cas.v.just.edu.cn/cas/login?service=http%3A%2F%2Fmy.just.edu.cn%2F")
driver.find_element_by_id("username").send_keys("xxx")
driver.find_element_by_id("password").send_keys("xxx")
driver.find_element_by_id("passbutton").click()# 点击登录
now_handle=driver.current_window_handle #开一个新页面
driver.switch_to.window(now_handle)
driver.get("https://ec43d80978edf4f14590b58d041fc8baids.v.just.edu.cn/default/work/jkd/jkxxtb/jkxxcj.jsp")
# 14天内是否接触(jc)海外归国人员:
jc = 'document.getElementsByClassName("iCheck-helper")[16].click()'
driver.execute_script(jc)
# 今日是否经过或滞留中高风险(gfx)地区:
gfx = 'document.getElementsByClassName("iCheck-helper")[24].click()'
driver.execute_script(gfx)
# 昨晚体温
driver.find_element_by_id("input_zwtw").send_keys("36.1")
# 今晨体温
driver.find_element_by_id("input_tw").send_keys("36.1")
sleep(5)
# 今日逗留地址
driver.find_element_by_xpath("//*[@id=\"input_jrjzdxxdz\"]").send_keys("学校")
# 点击提交
def click_js():
js = 'document.getElementsByClassName("btn btn-primary obtn")[0].click()'
driver.execute_script(js)
sleep(5) #由于数据提交到服务器后端会有一定的时延,
#所以设置一个延迟在执行,不然执行太快,服务器无法识别
click_js()
driver.quit()
linux端计划任务
linux端设置定时执行我们就可以使用计划任务来完成了,这里先安装yum install crontab -y- 接下来就是设置每天定时六点半打卡
crontab -e
30 06 * * * /usr/local/bin/python3 /usr/local/bin/auto_daka.py # 这里的30 06 * * *就是实现每天定时的操作,第六列就是python3的安装路径,不清楚的可以(which python3或者使用realpath python3查看一下),第七列是你要执行的脚本的路径,查找方式同上
service crond restart # 重启服务(有的可能是systemctl restart crond命令),这样每天到点就会打卡啦,然后可以去/var/spool/mail中查看执行情况
crontab -l # 可以查看写好的计划任务
- 在执行计划任务时,一开始发现一直报
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.找不到路径的错,遂发现要在这里把它的绝对路径加进去driver=webdriver.Firefox(options=foptions,executable_path ="/usr/local/bin/geckodriver") - 有关计划任务详解可以见:
https://www.cnblogs.com/yangjisen/p/13171918.html
期间踩得其他坑
- 由于打算部署到服务器,所以不敢直接开搞,就先拿了一台
centos7虚拟机试水,结果发现原先只装了python27,这就要面临同时让python2和python3共存问题,这里参考了一些比较好的文章,这里分享给大家:
https://blog.csdn.net/qq_39091354/article/details/86584046?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control - 按照这个操作期间还会遇到一个问题,就是在安装依赖的时候
yum执行不了了,因为yum是依赖于python2的,而他这里由于先安了python3会导致yum的脚本被改,我们这里只要把这两个文件改回python27就解决了
/usr/bin/yum
/usr/libexec/urlgrabber-ext-down
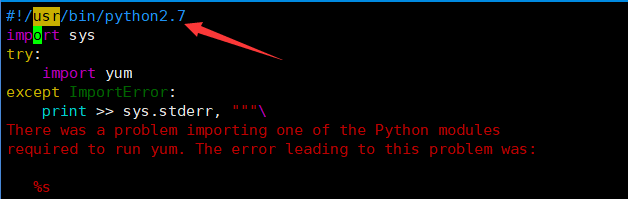

具体可见这篇文章:
https://blog.csdn.net/weixin_41857283/article/details/101363002
- 原本打算把脚本部署到
docker中,奈何pull的那个ubuntu的镜像是台裸机,要全部重头安装,遂放弃了
结语
- 至此,历经一天的脚本和踩坑经历记录完毕,完成了服务端部署脚本自动打卡,再也不用因为忘记打卡被私聊催债啦
- 这里只分享了
windows端的脚本,linux端的脚本,我还打算再加一些功能,这里就先不贴出来了,有需要的可以私聊我

 浙公网安备 33010602011771号
浙公网安备 33010602011771号