BUUCTF 几道crypto WP
[AFCTF2018]Morse
- 简单的莫尔斯密码,最直观的莫尔斯密码是直接采用空格分割的点和划线,这题稍微绕了一下使用的是斜杠来划分
所以首先将斜杠全部替换为空格,然后在在线解密莫尔斯密码,得到一串16进制最后在16进制转字符串即可
[GUET-CTF2019]BabyRSA
- 给出以下条件
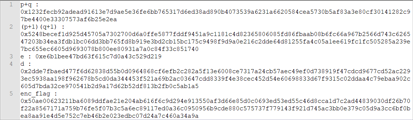
- 这里直接给出欧拉函数,以及p+q的结果,我们知道要想求解m=pow(c,d,n),而这里d的问题已经是直接给出的,
所以剩下就是n的求解,n这里只要把欧拉函数展开在和p+q进行运算即可得到
- (p+1)(q+1)=pq+(p+q)+1 => n=pq=(p-1)(q-1)-(p+q)-1
- 所以最终exp如下:
# -*- coding:utf-8 -*-
# Author : Konmu
# k=p+q
# phi=(p+1)(q+1)
from Crypto.Util.number import long_to_bytes
k=int('0x1232fecb92adead91613e7d9ae5e36fe6bb765317d6ed38ad890b4073539a6231a6620584cea5730b5af83a3e80cf30141282c97be4400e33307573af6b25e2ea',16)
phi=int('0x5248becef1d925d45705a7302700d6a0ffe5877fddf9451a9c1181c4d82365806085fd86fbaab08b6fc66a967b2566d743c626547203b34ea3fdb1bc06dd3bb765fd8b919e3bd2cb15bc175c9498f9d9a0e216c2dde64d81255fa4c05a1ee619fc1fc505285a239e7bc655ec6605d9693078b800ee80931a7a0c84f33c851740',16)
e=int('0xe6b1bee47bd63f615c7d0a43c529d219',16)
d=int('0x2dde7fbaed477f6d62838d55b0d0964868cf6efb2c282a5f13e6008ce7317a24cb57aec49ef0d738919f47cdcd9677cd52ac2293ec5938aa198f962678b5cd0da344453f521a69b2ac03647cdd8339f4e38cec452d54e60698833d67f9315c02ddaa4c79ebaa902c605d7bda32ce970541b2d9a17d62b52df813b2fb0c5ab1a5',16)
c=int('0x50ae00623211ba6089ddfae21e204ab616f6c9d294e913550af3d66e85d0c0693ed53ed55c46d8cca1d7c2ad44839030df26b70f22a8567171a759b76fe5f07b3c5a6ec89117ed0a36c0950956b9cde880c575737f779143f921d745ac3bb0e379c05d9a3cc6bf0bea8aa91e4d5e752c7eb46b2e023edbc07d24a7c460a34a9a',16)
n=phi-k-1
m=pow(c,d,n)
print(long_to_bytes(m))
[NCTF2019]Keyboard
- 这题说实话,算作密码的题目有点牵强感觉,脑洞有点多,感觉更加偏向misc的类型
- 首先密文中给出的字母观察之后发现全是键盘字母键的第一行(从上向下看),并且每一个都按序对应了数字键
q->1,w->2,e->3,r->4...
- 其次发现密文中字母重复的次数全是在1-4次,故而猜测是手机九宫格密码

- 接下来的解决方法两种,一种是手动写,一种是编写脚本
- 我写的exp如下:
# -*- coding:utf-8 -*-
# Author : Konmu
# [NCTF2019]Keyboard
chiper='ooo yyy ii w uuu ee uuuu yyy uuuu y w uuu i i rr w i i rr rrr uuuu rrr uuuu t ii uuuu i w u rrr ee www ee yyy eee www w tt ee'
chiper=chiper.split(' ')
keys=['q','w','e','r','t','y','u','i','o']
values=[1,2,3,4,5,6,7,8,9]
dicts=dict(zip(keys,values))
jiugongge=[' ','abc','def','ghi','jkl','mno','pqrs','tuv','wxyz']
new_dicts=dict(zip(values,jiugongge))
for i in range(len(chiper)):
temp=dicts.get(chiper[i][0])
print(''.join(new_dicts[temp][len(chiper[i])-1]),end='')
[HDCTF2019]bbbbbbrsa
- 这题有个坑的地方就是,一开始没注意他导入库的时候把b64encode重命名成了b32encode,剩下来要解决的问题就是e的求解
这里这题是取得50000-70000之间的随机与phi互素的数,解决方法也很简单,直接在这个范围内爆破就行了
- 第二个坑点就是,由于不是直接参赛时做题,所以对于flag的格式并不了解,只好一个个尝试
(这里你可能会想BUUCTF平台不是告诉你格式了吗?答:由于好多题的最终答案都是改了格式的,所以到底是不是flag{}包裹的,真不好确定இ௰இ)
- exp示例:
# -*- coding:utf-8 -*-
# Author: Konmu
from base64 import b64decode
import gmpy2
from Crypto.Util.number import long_to_bytes
p=177077389675257695042507998165006460849
q=211330365658290458913359957704294614589
n=37421829509887796274897162249367329400988647145613325367337968063341372726061
c='==gMzYDNzIjMxUTNyIzNzIjMyYTM4MDM0gTMwEjNzgTM2UTN4cjNwIjN2QzM5ADMwIDNyMTO4UzM2cTM5kDN2MTOyUTO5YDM0czM3MjM'
c=int(b64decode(c[::-1]))
phi=(p-1)*(q-1)
for e in range(50000,70000):
if(gmpy2.gcd(e,phi)==1):
d=int(gmpy2.invert(e,phi))
m=pow(c,d,n)
if 'flag{' in long_to_bytes(m):
print(long_to_bytes(m))
鸡藕椒盐味
- 这题谐音提示奇偶校验位,但实际感觉应该不是奇偶校验码,准确来说应该是个汉明码的奇偶校验分组码
当监督位为:0000,接收方生成的校验位和收到的校验位相同,否则不同说明出错,所以这题就变成了解决汉明码的校验纠错问题
- 汉明码纠错分为以下几步,首先根据公式:\(2^r\geq k+r+1\)(k表示数据位数,r表示校验位数,r要是最小的符合不等式的值)
根据给出的汉明码1100 1010 0000共十二位,说明k+r=12,则大于13的最小r应为4,故k数据位为8
- 确定共4位校验位,且校验位的排放位置只能在\(2^n\)的位置上,所以确定汉明码中的\(P_1,P_2,P_4,P_8\)这几个位置是校验位
那么将其剔出后的即为数据k(1100 0100)
- 又题中说顺序倒了一下,说明正确的数据应该是0000 0010 0011,则剔出后有效数据为0010 0011
- 到这里已经得到了正确的数据,所以剩下就是求出校验位指出的错误位

注:\(P_1,P_2,P_4,P_8\)的数据填写其二进制的首位,得到发送方校验码:1000
- 计算\(P_1,P_2,P_4,P_8\)
\(P_4=D_5\bigoplus D_6\bigoplus D_7\bigoplus D_8=0\bigoplus 0\bigoplus 1\bigoplus 1=0\)
\(P_3=D_2\bigoplus D_3\bigoplus D_4\bigoplus D_8=0\bigoplus 1\bigoplus 0\bigoplus 1=0\)
\(P_2=D_1\bigoplus D_3\bigoplus D_4\bigoplus D_6\bigoplus D_7=0\bigoplus 1\bigoplus 0\bigoplus 0\bigoplus 1=0\)
\(P_1=D_1\bigoplus D_2\bigoplus D_4\bigoplus D_5\bigoplus D_7=0\bigoplus 0\bigoplus 0\bigoplus 0\bigoplus 1=1\)
注:以上计算说明:以\(P_4\)为例,其检验位检验的是所有二进制(从左到右)第1位为一的数据,即\(D_5,D_6,D_7,D_8\)
- 由检验结果可得接收方校验码:0001
- 接收和发送校验码不一致,说明有错,将其取反即可
最终数据是:1101 1010 0000,将其用python md5算一下即可
[HDCTF2019]basic rsa
# -*- coding:utf-8 -*-
# Author: Konmu
# [HDCTF2019]basic rsa
import gmpy2
from Crypto.Util.number import *
p=262248800182277040650192055439906580479
q=262854994239322828547925595487519915551
e=65533
n=p*q
c=27565231154623519221597938803435789010285480123476977081867877272451638645710
phi=(p-1)*(q-1)
d=int(gmpy2.invert(e,phi))
m=pow(c,d,n)
print(long_to_bytes(m))
浪里淘沙
- 看到密文全是一些单词的重复,所以想到词频统计,首先获取每个单词出现的频率,然后按序排列,最后将排在4,8,11,15,16的单词进行拼接即可
- exp:
# -*- coding:utf-8 -*-
# Author: Konmu
f=open("C:/Users/xxx/Desktop/浪里淘沙.txt",'r')
data=f.read()
statistics={}
frequency=[]
num=[4,8,11,15,16]
def zipin(lsit):
for i in lsit:
statistics.setdefault(data.count(i),str(i))
frequency.append(data.count(i))
frequency.sort()
for i in num:
print(''.join(statistics.get(frequency[i-1])),end='')
print('\n')
return(statistics)
if __name__ == '__main__':
letters=["tonight","success","notice","example","should","crypto","backspace","learn","found","morning","we","system","sublim","the","user","enter"]
print(zipin(letters))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号