结对编程作业
https://github.com/2644521362/KongoCat/tree/master/021900823/TeamWork
| **姓名 | 分工 | 博客链接 |
|---|---|---|
| 李忱轩 | ai算法设计以及后端逻辑实现 | https://www.cnblogs.com/KongoCat/p/15452068.html |
| 黄海涛 | 原型设计以及前端实现 | https://www.cnblogs.com/hht11/p/15452114.html |
一、原型设计
原型作品的链接
https://orgnext.modao.cc/app/58c195ccbb1ee7be2f74ac02d5841c3359aacb9a 《猪尾巴游戏》
原型开发工具
墨刀
基本需求
- 建立一个纸牌游戏对战系统。可以给客户提供线上pk功能,满足客户的便利要求;可以两人同一台手机对战;可以人机对战。
- 纸牌游戏为“猪尾巴纸牌”。
- 系统具备自动出牌功能。
- 系统可以在对战期间统计双方手牌。
- 游戏基本流程
- 游戏由玩家一先手开始,在没有手牌时,两者均只能抽牌。
- 两者都有手牌时,可以凭借场上的情况选择出手牌或者抽牌。
- 最后抽牌堆空,两人比较手牌数,数量少者获胜。
大概思路
-
首先建立一个登录页面,可以在此页面注册id,查看规则。如果忘记密码,可以在此页面找回。


-
- 登录进入游戏模式选择页面,有三种模式,分别是“人机对战”,“在线对战”,“双人对战”。

-
- 进入游戏的对战中,左右分别设置抽牌堆和弃牌堆。上下两端是玩家操纵的区域。
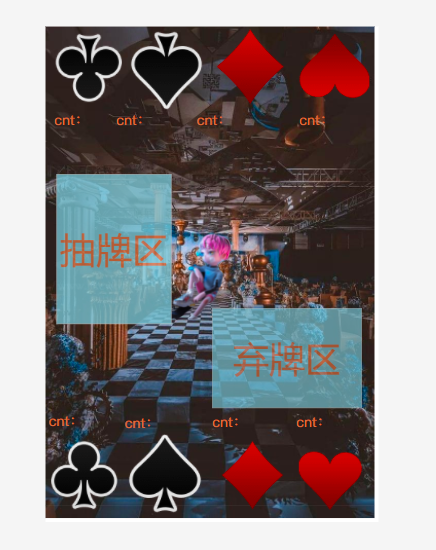
-
- 对战结束后,跳出“胜利”或者“失败”的字样。


-
找回密码页面

[2.2.2]遇到的困难及解决方法:(4分) -
困难描述
第一次使用原型设计工具,在网上又找不到使用教程。所以使用时入手很慢,自己琢磨了半天才知道怎么做出完整的页面。 -
解决过程
自己花时间+多多问使用过的同学完成。
构造原型时没有什么思路,参考之前学长们的博客有了大致思路。
二、原型设计实现
[2.3.1]代码实现思路:
游戏模拟实现类图:(StartUml制作)
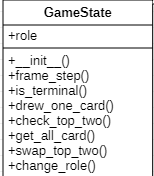
一开始看到AI算法的第一反应想写一个马尔科夫决策,结果写着写着不对劲,因为对花色和牌数进行分类的话,得到的状态数太多,同理,Qlearning算法也同样面临着维度灾难,因此最后选择了DQN算法进行分析,但是这次的训练效果显然不太理想,没有做到人机自我博弈的强化深度学习,但是应该也算是一个合格的人机算法(虽然效果好像不太好,他在面对一个人机,很多时候能抽30多张牌,这显然是不太合理的,但是他的胜率大部分时候都还可以,所以暂时就先这样了,下面从游戏基本实现开始介绍我的算法以及DQN算法的原理以及相关函数。
首先,介绍关于我的游戏模拟,对游戏本身来说,胜负跟13种卡牌的数值无关,只跟花色有关,因此使用5*4矩阵进行场上信息模拟与保存,在下图先放上一张类图进行大纲说明:

其中,GameState内部具有data数据定义,定义了5*4的矩阵
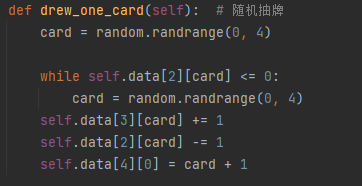
五行四列矩阵,行数区分了 玩家、对手、棋局、弃牌堆(次堆顶)
通过dreew_one_card函数进行随机获取一张牌并且置于顶部:
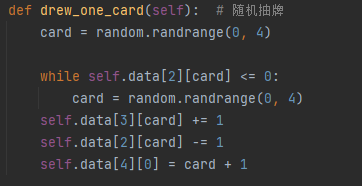
通过frame_step函数进行放置牌 或者 继续终局检测:
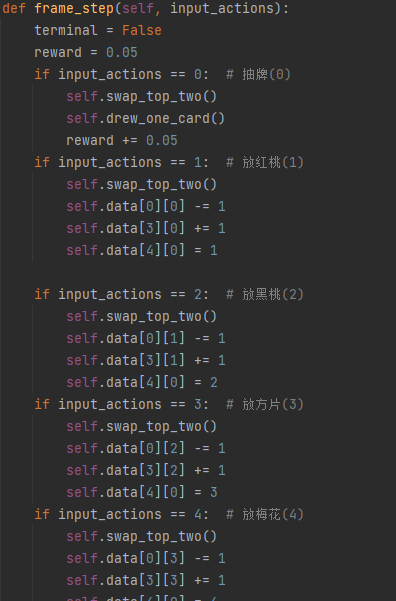
进行完简单的游戏模拟,开始我们的主题,介绍本次人工智能算法中使用的DQN算法:
要进行DQN的介绍,我先介绍关于Q-Learning的基础知识。
大家可能或多或少对于人工智能都有进行一定的了解,那必然就和增强学习离不开干系,我们希望机器能够自动的寻找每一个局面的最优解法,那就要让机器受到奖励与惩罚(就像小白鼠一样
为了得到最优策略Policy,我们考虑估算每一个状态下每一种选择的价值Value有多大。然后我们通过分析发现,每一个状态表示的Q(s,a)和当前得到的Reward以及下一个状态表示的Q(s,a)有关。
众所周知,计算机对于当前状态的判断是5*4的数字阵列,他无法进行数字含义的理解,但是他对于当前矩阵得出Active的过程却需要对数据进行理解,所以我们对状态进行了一个抽象,我们对状态-奖励表,定于一个Q矩阵存储,Q矩阵例子如下:
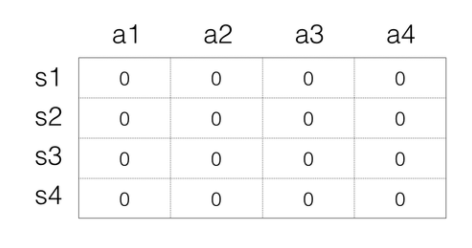
s代表状态,a代表操作,数值代表状态对应的操作进行的奖励,如此定义了一个状态奖励转换矩阵,
下面介绍Qlearning核心算法,即矩阵值的计算方式
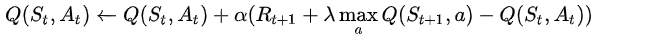
这里 α代表的是学习率,也就是我需要对数据变化幅度的设定,这里用文字解释为:
状态奖励是 当前价值+比例*未来最高价值减去代价
当反复迭代一段时间,矩阵趋于稳定,得到状态转移矩阵(每次选择价值最大的行为去操作
简单介绍了Qlearning,开始进入正题,在面对本题设计时,存在一个很严重的问题,花色4种可能,牌数13种可能,一共有4种玩家(在这里将玩家分类为 玩家 对手 棋局 弃牌堆),也就是状态有1344种可能,这对于内存来说,是一种灾难,我们不可能穷举所有的状态存入矩阵中,更何况还要递归所有的状态以及计算相应的转移价值,这也就是常说的,维度灾难,所以我们需要的是:对于一种状态,我们利用价值函数近似他的价值,通过参数的设计,我们可以得到一个计算公式去计算价值,而不是将每一个状态的价值进行存储,也就是:
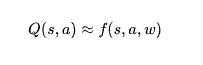
接下来,参数如何获取?权重如何得到是最大的一个问题,终于来到关于和深度学习相结合的一步!
关于这部分知识如果有卷积神经网络有基本的礼节,可以观看b站cs231n系列进行学习,下文仅简单介绍。在本次作业中,我使用keras架构进行网络设计
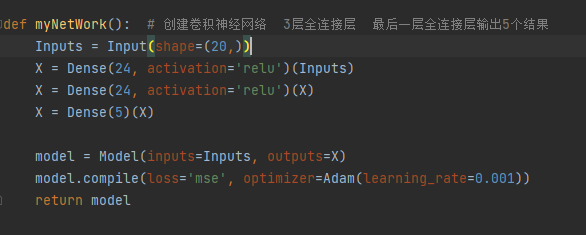
然后通过replay函数进行状态抽取进行拟合与fit训练,在进行标签计算式利用了bellman方程,由于函数想了半天不太好定义预期函数,这里将(未来部分)的价值换成了预测结果的置信度,bellman原方程如下:(说实话我也看不太懂,感觉不太像文字)
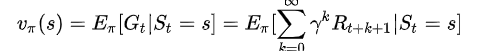
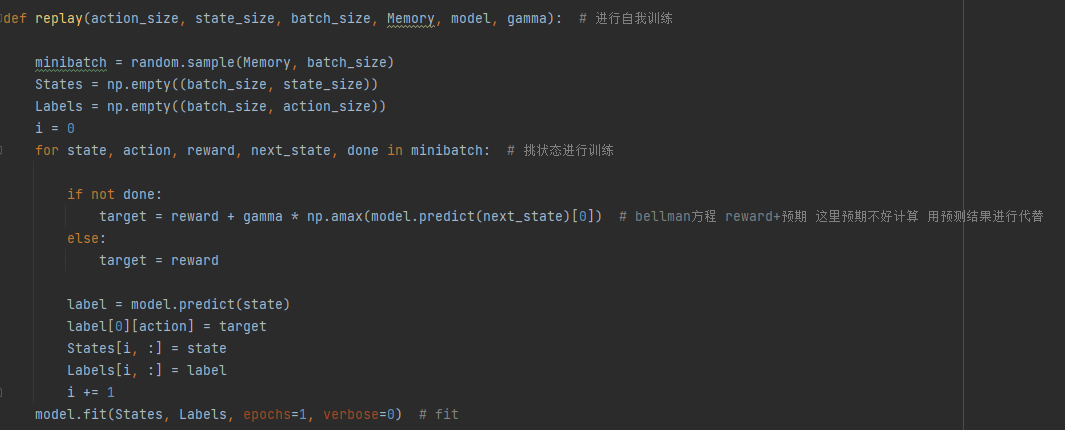
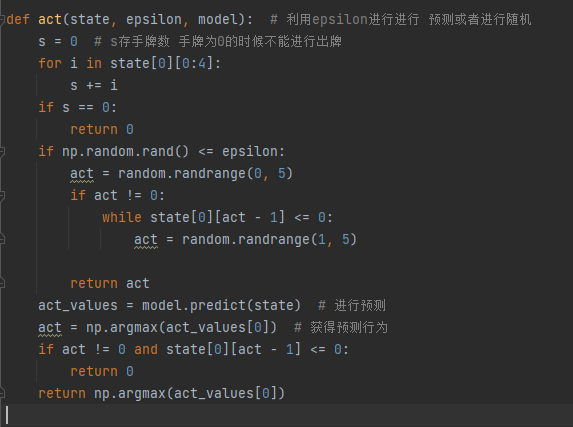
定义完了神经网络与训练方法后(基本都是模板),我们进行自我游戏,我们通过自己打自己的方式获得每一步的状态模拟,有同学可能好奇我们是如何进行最初的抽牌的,我将在下文的reward定义中给出,其次,我们定义了一个epsilon参数,这个参数可以理解为(随机挑选行动的概率),一开始设置为0.8,在每次训练后进行相应的减少,随机行动部分可以保证他在有限的次数内找到解,具体代码函数如下

最后解释下关于act函数,利用epsilon参数进行选择active,如果随机数小于epsilon,进行随机选择,反之进行网络预测
最后展示关于奖励函数
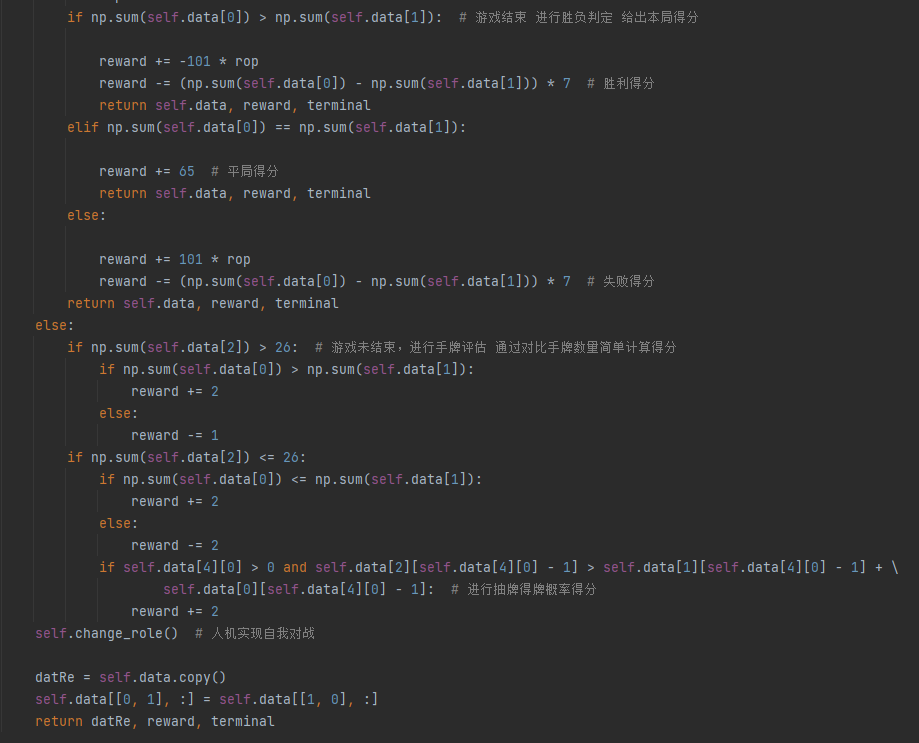
至此,基本的AI设计实现完毕。
[2.3.3]遇到的代码模块异常或结对困难及解决方法。
在一开始Qlearning算法设计ai时,遇到了维度爆炸的问题,即状态不可数的问题。
利用与神经网络结合的办法实现DQN算法进行解决
第一次使用DQN算法进行人工智能的设计,虽然这次感觉训练出来的参数,并不理想,但是对于缺乏逻辑的人机对战中,胜场可以达到20:1
[2.3.4]评价你的队友
黄海涛对李忱轩的评价
- 值得学习的地方:
- 1.队友在之前就已经有过一些知识基础,所以做得算是游刃有余。我的前端从0开始,到最后都没有完成,相比起来简直是天差地别。以后得学习更多东西,以备不时之需。
- 2.时间管理上队友胜我许多,是我很需要学习的。这里需要自我检讨,是我拖累了队友。
- 需要改进的地方:基本上是我在拖后腿了,队友是很优秀的。
李忱轩对黄海涛的评价
- 值得学习的地方:对于大部分人来说,初次面对未知的、没有人帮助的自主学习总会使人心生畏惧,我的队友在本次学习过程中虽然没有得到最终原型设计的实现,但是有整体开发环节的过程,了解了许多开发的问题与需要克服的难关,并且得到了初步的验证、解决与实现
- 需要改进的地方:时间管理过于放松,导致后期项目无法交付以及学习内容有所缺失导致部分功能无法实现
[2.3.5]PSP学习进度条
后端:李忱轩
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 101 | 101 | 7 | 7 | 熟悉增强学习相关知识 |
| 2 | 292 | 393 | 12 | 19 | 学习keras架构,实现初步设计 |
| 3 | 114 | 507 | 19 | 38 | 进行了优化以及网络训练 |
| 前端:黄海涛 | |||||
| 第n周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(h) | 累计学习耗时(h) | 重要成长 |
| ---- | ---- | ---- | ---- | ---- | ---- |
| 第一周 | 500 | 500 | 12 | 12 | 最开始不知道怎么开始,就先学习了基本的HTML,css |
| 第二周 | 500 | 1000 | 12 | 24 | 一周才确定要用微信小程序实现,就又学习了一些微信小程序写法和一点点的js |
| 第三周 | 300 | 1300 | 8 | 32 | 学习怎么写简单动画,开始看接口使用。但是这周有两门考试,就少用很多时间来学 |
| 第四周 | 450 | 1750 | 15 | 47 | 学了接口使用,但是没有在作业里成功使用,最后还是没有完成作业。 |
三、心得
前端--黄海涛:每一次作业都有很多新的要学,对我这种不自觉的选手来说是很不友好的。第一次作业在0基础下学了学python再来做,发现还是有很多东西根本没有理解,还是没有完成作业。这次也是一样,很对不起队友的信任,队友比较早就完成了后端的文字游戏和ai设计,但是我的前端还是一塌糊涂,那时又赶上正好有两门课要考试,就又少了很多时间来学小程序。在队友的监督下,学了微信小程序的wxml,wxss,js来实现原型和作业接口的使用。但是自己还是很不争气的没有学会用js来实现逻辑层的交互。用js也只是完成了数据绑定、页面跳转和一些简单的出牌动画。真的是让我对打代码这件事丧失了很多信心。最后几天想了想自己之前的学习过程,自己可能就不是这块料,最开始转专业也只是从众听了别人的,到这边后感受到的更多的还是挫败感,和之前自己的想象是千差万别。两次作业都没有正常完成,总的来说还是很失败的。自己的态度和学习能力是最大的问题吧。希望可以在下次结对编程时早队友一步完成任务,不要再次辜负了他的信任。
后端--李忱轩:这一次代码实现人工智能还算成功,虽然不知道最后结果,但我觉得应该能超越20%以上的同学了,满足了,这也是我第一次对于神经网络的使用,之前虽然学过深度学习但是也只是纸上谈兵,这一次为了实现ai也特意去(粗略的)学习了一边基础的增强学习算法,应该是收获颇丰了,比较可惜的就是没能实现最终的项目,希望在下一次的软工作业中能够真正实现自己感兴趣的项目,这一次本来打算在前端实现逻辑功能,但是前端压力太大就把逻辑功能放到后端,利用数据库进行存储游戏状态、对局等,也进行了flask架构的python实现,(总算成为了一个后端?),之前自己感觉定义是偏算法岗,但是算法能力不突出,感觉这次以后可以向后端转型,很有收获(嗯!)
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号