一类(One-Class)分类器
本文摘自博客和论文,参考文献请看文末。
一类分类技术概念
与传统的分类技术不同,一类分类技术仅采用隶属于一个类别的样本来训练分类器,其通常被用于某种极端场景,即训练样本仅包含正常样本,而异常样本不可得的情况。该技术也已被用于解决极度不平衡分类问题,因为在此类问题上,传统的类不平衡学习方法通常不能取得较好的分类效果。
目前,最为常用的一类分类器包括基于高斯概率密度估计的方法、基于Parzen窗的方法、自编码器法、基于聚类的方法、基于K近邻的方法、一类支持向量机、支持向量数据描述法及一类极限学习机等。无论哪种方法,都是用于刻画一个覆盖关系,从而更好地描述正常样本的分布,使之与异常样本区分开来。
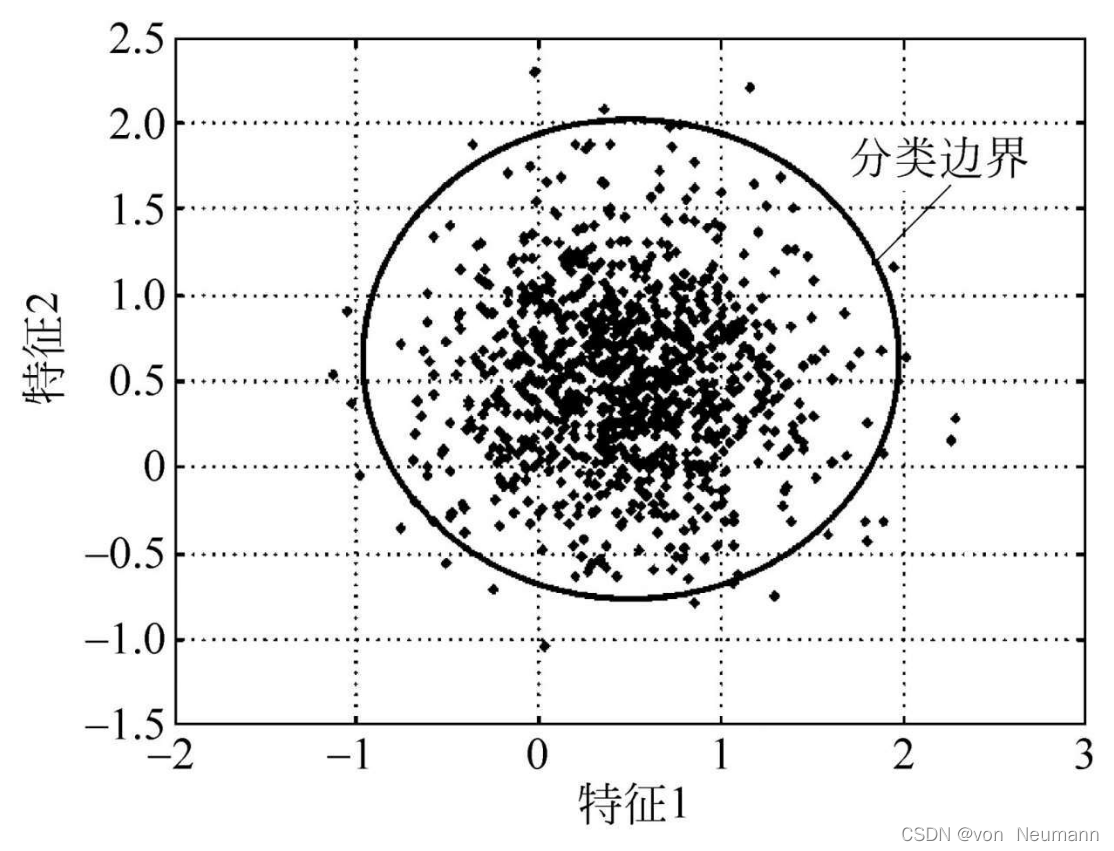
下图给出了一个一类分类器的示意图。从该图中不难看出,训练样本均属于同一类,一类分类技术就要找到一个覆盖模型来区分该类样本与未出现的异常样本。特别需要指出的是,为了保证分类器的泛化性能,可以允许一定比例的离群样本被误分。
应用领域
由于单类分类器的优良特性, 这些模型已经广泛应用于文本分类、入侵检测、手写体识别、图像处理等领域.单类分类器一般可以用于解决如下类别样本数目不平衡问题:
(1) 比如两个训练类别中的样本数目比例高至9∶1, 如医学图像等异常样本数据极少的情况.
(2) 异常类样本获取代价较高的问题:比如某些卫星网络故障诊断, 要获取故障样本所付出的代价太高, 不可能为了获取故障样本而特意让卫星系统出现故障.
(3) 异常类样本数目几乎无穷问题:比如入侵检测中攻击数量和种类层出不穷, 而且有的攻击产生变种, 根本就不清楚该拿哪些攻击样本来训练入侵检测器.
单类分类方法同样可以用于野值与新颖值的检测.在这种场合, 野值与新颖值被看作成异常类数据[31].由于单类分类器只训练正常类的训练数据, 因此在解决方法上不同于传统的两类 (或者多类) 分类问题.在单类分类问题的错误率监测上, 存在着两个标准:正常类错误率与异常类错误率.这两个错误率是相关的, 正常类错误率高的往往导致异常类错误率低, 反之亦然.因此, 在最后评价一个单类分类器的性能, 应从这两个方面综合考虑.
单类分类器由于只需要一类数据作为训练样本, 减化了数据预处理的时间, 在卫星通信系统和大型网络管理系统的故障诊断和入侵检测中都有着极大的应用前景.
参考资料
深入理解机器学习——类别不平衡学习(Imbalanced Learning):常用技术概览
潘志松,陈斌,缪志敏,倪桂强.One-Class分类器研究[J].电子学报,2009,37(11):2496-2503.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号