莫队算法
发明者莫涛,通常用于比较暴力的进行区间操作
以简短的框架、简单易记的板子和优秀的复杂度闻名于世
然而由于莫队算法应用的毒瘤,很多可做的莫队模板题都有着较高的难度评级,令很多初学者望而却步
然而,如果真正理解了莫队的算法原理,那么用起来还是很简单的
前置芝士
莫队算法还是比较独立的。不过还是得了解以下的一些知识:
- 分块的基本思想
- STL 中 sort 的用法(手写 cmp 函数或重载运算符实现结构体的多关键字排序)
- 各种卡常技巧
- 倍增/树剖 求LCA(树上莫队所需)
- 数值离散化(用于应付很多题目)
基础实现
莫队算法优化的核心是分块和排序
我们将大小为 \(n\) 的序列分为 \(\sqrt{n}\) 个块,从 \(1\) 到 \(\sqrt{n}\) 编号,然后根据这个对查询区间进行排序
一种方法是把查询区间按照左端点所在块的序号排个序,如果左端点所在块相同,再按右端点排序
排完序后我们再进行左右指针跳来跳去的操作,虽然看似没多大用,但带来的优化实际上极大
排序具体的规则类似这样
bool cmp(node x, node y){
return x.l / len == y.l / len ? x.r < y.r : x.l < y.l;
}
而所谓左右指针的移动,也就相当于一个实际区间与目标区间的匹配过程
对于每组询问 \((l,r)\),我们可以把它看做一个目标区间,而我们的左右指针中间的区域,就是目前维护的实际区间
我们只统计了实际区间内每个点的贡献,而每组询问是要求 \((l,r)\) 之间的所有贡献,所以我们要做的就是通过移动左右指针来使得实际区间与目标区间相匹配,同时在移动的过程中统计新加入的点的贡献,并删除已不在实际区间内的点的贡献,从而得到每个区间询问的答案
关于左右指针的移动,也就是实际区间的伸缩,首先要确定当前的答案是否已经被统计,是否要保留等等
这里设 \((l,r)\) 为一组询问,\(L,R\) 分别为当前的左右指针
-
区间扩展:当 \(L>l\) 或者 \(R<r\),即目标区间有一部分不在实际区间内时,我们需要先向着目标区间移动当前的指针到一个新的地方,再加上那个点的贡献
-
区间收缩:当 \(L<l\) 或者 \(R>r\),即实际区间有一部分或者全部的贡献对于这组询问无用时,我们需要把指针移动出无用的点,所以要先删去这个点的贡献再移动
具体代码实现如下:
for(int i = 1; i <= q; i ++){
while(L > Ask[i].l) Add(-- L);
while(R < Ask[i].r) Add(++ R);
while(L < Ask[i].l) Del(L ++);
while(R > Ask[i].r) Del(R --);
Res[Ask[i].id] = ans;
}
一些拓展
带修莫队
我们知道普通的莫队是不带修改操作的,但是后人总结 + 开发后就使得它可以支持修改操作,这样的莫队被称为带修莫队
带修莫队的原理是什么呢,就是对于每个询问操作给它打一个时间戳,记录下到哪一个操作之前的修改操作在这次询问前都已完成
然后对于一个区间的某个询问,把在它之前所有对这个区间操作都进行,在这个区间之后进行的操作给它改回来,最后统计答案即可
排序规则与普通的差不多,只需判断在左右端点所处的块都相同时按照时间排序即可
带修莫队的块长通常为 \(n^{\frac{2}3}\),分成 \(n^{\frac{1}3}\) 块
下面结合一个例题来说明
[国家集训队]数颜色 / 维护队列
给出两种操作,一种是修改某个位置的数字,另一种是统计一段区间中本质不同的数字的种类数,要求对于每组询问给出正确答案
带修莫队模板题
- 对于修改操作
在输入的时候对于每个询问操作打上对应的修改操作的下标,来标记到每组询问需要进行的修改有哪些
对于每个在这组询问之前的操作,判断它的操作位置是否处于询问的范围之中,如果有,就按操作加减
注意,每次进行完一个操作之后,下次再询问这个操作必定是反转这次操作,而我们无法确定哪个操作在之前被进行过,就把每次操作前后的数交换一下
- 对于询问操作
维护每个数字的出现次数,在转移的过程中判断每个更改这一种类的数字个数是否发生对答案有影响的变化,即原先没有现在有了 或者 原先有现在没了,然后对于答案进行相应的操作即可
#include<cmath>
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<iostream>
#include<algorithm>
#define maxn 1000100
#define INF 0x3f3f3f3f
#define int long long
using namespace std;
char opt;
int a[maxn],ans[maxn],siz[maxn];
int n,m,L=2,R=1,Now,len,cntq,cntc,Ans;
struct change{int pos,col;}c[maxn];
struct question{int l,r,t,id;}q[maxn];
int read(){
int s=0,w=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-') w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') s=(s<<1)+(s<<3)+ch-'0',ch=getchar();
return s*w;
}
bool cmp(question a,question b){
return a.l/len!=b.l/len?a.l<b.l:a.r/len!=b.r/len?a.r<b.r:a.t<b.t;
}
void Add(int x){Ans+=(++siz[x]==1);}
void Del(int x){Ans-=(--siz[x]==0);}
void Modi(int x,int ti){
if(c[ti].pos<=q[x].r&&c[ti].pos>=q[x].l)
Del(a[c[ti].pos]),Add(c[ti].col);
swap(a[c[ti].pos],c[ti].col);
}
signed main(){
n=read();m=read();len=pow(n,2.0/3);
for(int i=1;i<=n;i++) a[i]=read();
for(int i=1;i<=m;i++){
cin>>opt;
if(opt=='Q'){
q[++cntq].l=read(),q[cntq].r=read(),
q[cntq].id=cntq,q[cntq].t=cntc;
}
else c[++cntc].pos=read(),c[cntc].col=read();
}
sort(q+1,q+cntq+1,cmp);
for(int i=1;i<=cntq;i++){
while(L<q[i].l) Del(a[L++]);
while(L>q[i].l) Add(a[--L]);
while(R<q[i].r) Add(a[++R]);
while(R>q[i].r) Del(a[R--]);
while(Now<q[i].t) Modi(i,++Now);
while(Now>q[i].t) Modi(i,Now--);
ans[q[i].id]=Ans;
}
for(int i=1;i<=cntq;i++) printf("%lld\n",ans[i]);
return 0;
}
回滚莫队
有些题目在区间转移时,可能会出现增加或者删除无法实现的问题
在面对这些问题时,我们可以用到另一种莫队——回滚莫队
回滚莫队的本质就是将原来的问题改变成一个只需增加或者只需删除的问题,从而解决其中一种操作难以实现的问题
因此,回滚莫队也分为两类,不删除莫队 和 不添加莫队
不删除莫队,就是保证一开始时实际区间位于每组询问的区间中并且中无任何元素,然后对于每组询问,向外扩展左右指针,在每组询问处理完之后再将指针回到原来位置,这样就可以只用扩展区间来处理出每组询问的答案
不增加莫队同理,只需一开始将实际区间覆盖每组询问的目标区间,然后收缩区间删除元素即可
来回处理的方式使得这种莫队得名回滚莫队,回滚的十分形象
这里也通过两道例题分别说明不删除与不增加莫队的具体实现
歴史の研究
给定一个序列,每次求序列中点权乘出现次数的最大值
这是一道不删除莫队的模板题
先考虑区间的拓展对于答案造成的影响
可以发现,当实际区间新加入一个数时,我们可以将它的出现次数加一,同时判断它的点权乘出现次数是否可以成为新的答案。但是如果删除了一个数,且这个数原先的点权乘次数就是答案大小时,我们无法确定新的答案到底是什么
所以,对于这种删除操作难以实现的问题可以考虑不删除莫队
首先,对于这个数据,我们进行离散化处理再操作
我们初始将左右指针分别置于每个询问左端点所在的块的右端点的右左两边,并保证其中无任何元素,即 \(L>R\)
这时,对于每组询问,首先判断左右端是否处于同一块中。如果处于同一块中,那就从左到右扫一遍直接处理即可
如果左右两端分处于不同的块中,那么询问的左端必定在左指针左边,右端必定在右指针右边。这样对于每组询问,我们只需扩展左右指针不断加入元素直到统计出答案,然后再回滚回初始位置即可。
至此,我们便可以通过只增不删的方法处理询问
#include<cmath>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<iostream>
#include<algorithm>
#define maxn 100010
#define int long long
using namespace std;
int n,m,len,tot,all;
int Ans,lastLB,Res,L=1,R;
int id[maxn],cnt[maxn],Cnt[maxn],rig[maxn];
int a[maxn],b[maxn],lef[maxn],ans[maxn];
struct question{int l,r,now;}q[maxn];
int read(){
int s=0,w=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-') w=1;ch=getchar();}
while(ch>='0'&&ch<='9') s=(s<<1)+(s<<3)+ch-'0',ch=getchar();
return s*w;
}
void Del(int x){--Cnt[a[x]];}
void Add(int x,int& answer){
++Cnt[a[x]];answer=max(answer,b[a[x]]*Cnt[a[x]]);
}
bool cmp(question a,question b){
return id[a.l]^id[b.l]?id[a.l]<id[b.l]:a.r<b.r;
}
void build(){
n=read();m=read();
len=sqrt(n+0.5);tot=(!n%len)?n/len:n/len+1;
for(int i=1;i<=n;i++)a[i]=read(),b[i]=a[i];
sort(b+1,b+n+1);all=unique(b+1,b+n+1)-b-1;
for(int i=1;i<=n;i++)a[i]=lower_bound(b+1,b+all+1,a[i])-b;
for(int i=1;i<=tot;i++)lef[i]=(i-1)*len+1,rig[i]=min(i*len,n);
for(int i=1;i<=tot;i++)for(int j=lef[i];j<=rig[i];j++)id[j]=i;
}
signed main(){
build();
for(int i=1;i<=m;i++)
q[i].l=read(),q[i].r=read(),q[i].now=i;
sort(q+1,q+m+1,cmp);
for(int i=1;i<=m;i++){
if(id[q[i].l]==id[q[i].r]){
for(int j=q[i].l;j<=q[i].r;j++) ++cnt[a[j]];
for(int j=q[i].l;j<=q[i].r;j++)
ans[q[i].now]=max(ans[q[i].now],cnt[a[j]]*b[a[j]]);
for(int j=q[i].l;j<=q[i].r;j++) --cnt[a[j]];
continue;
}
if(id[q[i].l]!=lastLB){
while(R>rig[id[q[i].l]]) Del(R--);
while(L<rig[id[q[i].l]]+1) Del(L++);
Ans=0;lastLB=id[q[i].l];
}
while(R<q[i].r) Add(++R,Ans);int _L=L;Res=Ans;
while(_L>q[i].l) Add(--_L,Res);ans[q[i].now]=Res;
while(_L<L) Del(_L++);
}
for(int i=1;i<=m;i++) printf("%lld\n",ans[i]);
return 0;
}
Rmq Problem / mex
给定一个序列,每次询问一个区间权值的 mex (最小的没出现过的自然数)
这是不添加莫队的模板题
同样,先考虑区间伸缩时删除或者增加一个新的数对答案会造成什么影响
显然,当我们增加一个新的数时,如果这个数就是当前的答案,那答案就必须改变,而我们无法确定新的答案应该在哪个位置。但我们删除一个数字时,只需判断这个数与当前答案的大小关系和它的出现次数就行了
因此,我们要维护一个只支持删除操作的莫队
如果支持删除,那初始左右指针必须涵盖当前的一个询问区间,我们可以将左指针置于询问左端点所处块的左端,右指针置于 \(n\) 结点,然后判断询问的左右端点是否处于同一块。若处于同一块就扫一遍找答案即可,若不处于同一块再不断删除
注意这里有个小结论:既然找的是最小的自然数,而序列最长为 \(n\),那么答案必定在 \([1,n+1]\) 中,不在这个区间内的数可以直接不考虑,也可以初始时直接把大于 \(n+1\) 的数赋值为 \(n+1\)
剩下的操作基本类似于不删除莫队,就是删除、回滚、再删除、再回滚的过程
具体可以看代码
#include<cmath>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<iostream>
#include<algorithm>
#define maxn 1000100
#define int long long
using namespace std;
int n,m,len,tot,Now;
int Ans,lastLB,Res,L=1,R,all;
int id[maxn],cnt[maxn],Cnt[maxn],rig[maxn];
int a[maxn],b[maxn],lef[maxn],ans[maxn];
struct question{int l,r,now;}q[maxn];
int read(){
int s=0,w=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-') w=1;ch=getchar();}
while(ch>='0'&&ch<='9') s=(s<<1)+(s<<3)+ch-'0',ch=getchar();
return s*w;
}
bool cmp(question a,question b){
return id[a.l]^id[b.l]?id[a.l]<id[b.l]:a.r>b.r;
}
void Add(int x){
if(a[x]>n+1) return;Cnt[a[x]]++;
}
void Del(int x,int &minx){
if(a[x]>n+1) return;Cnt[a[x]]--;
if(!Cnt[a[x]]) minx=min(minx,a[x]);
}
void build(){
n=read();m=read();R=n;
len=sqrt(n+0.5);tot=(!n%len)?n/len:n/len+1;
for(int i=1;i<=n;i++)a[i]=read(),b[i]=a[i];
for(int i=1;i<=n;i++)Cnt[a[i]]+=(a[i]<=n+1);while(Cnt[Ans])Ans++;
for(int i=1;i<=tot;i++)lef[i]=(i-1)*len+1,rig[i]=min(i*len,n);
for(int i=1;i<=tot;i++)for(int j=lef[i];j<=rig[i];j++)id[j]=i;
}
signed main(){
build();
for(int i=1;i<=m;i++)
q[i].l=read(),q[i].r=read(),q[i].now=i;
sort(q+1,q+m+1,cmp);
for(int i=1;i<=m;i++){
if(id[q[i].l]==id[q[i].r]){
for(int j=q[i].l;j<=q[i].r;j++) cnt[a[j]]+=(a[j]<=n+1);
int temp=0;while(cnt[temp]) temp++;ans[q[i].now]=temp;
for(int j=q[i].l;j<=q[i].r;j++) cnt[a[j]]-=(a[j]<=n+1);
continue;
}
if(id[q[i].l]!=lastLB){
while(R<n) Add(++R);
while(L<lef[id[q[i].l]]) Del(L++,Ans);
Now=Ans;lastLB=id[q[i].l];
}
while(R>q[i].r) Del(R--,Now);
Res=Now;int _L=L;
while(_L<q[i].l) Del(_L++,Res);
while(_L>L) Add(--_L);
ans[q[i].now]=Res;
}
for(int i=1;i<=m;i++) printf("%lld\n",ans[i]);
return 0;
}
树上莫队
顾名思义,是在树上跑的莫队,而且大多跑的是带修或者普通莫队
区别在于,一般的莫队在数列上跑,树上莫队在树上跑
想一下什么东西可以把树上的数映射到序列中
联想到我们平时写的树剖,就是为了把树上的信息变成线性的再跑线段树之类的,而它用到的就是dfs序
当然也可以用欧拉序这一类同样能处理树上关系的序列
所以我们一般在dfs序或欧拉序上跑莫队,这就是树上莫队
当然它还有一些细节,这里放两个例题说明:
Tree and Queries
给定一棵 \(n\) 个节点的树,根节点为 \(1\)。每个节点上有一个颜色 \(c_i\)。
\(m\) 次操作。操作有一种:u k:询问在以 \(u\) 为根的子树中,出现次数 \(\ge k\) 的颜色有多少种。
如果是问一个序列的一段区间中的颜色数,就是普通莫队板子
但是这是在树上,就按照刚才的思路,转化成dfs序做就好了
这个实现比较简单,看代码就懂了
#include<cmath>
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<iostream>
#include<algorithm>
#define maxn 1000100
#define INF 0x3f3f3f3f
//#define int long long
using namespace std;
int n,m,len,cnt,tot,Ans,all,L=1,R;
int dfn[maxn],siz[maxn],used[maxn],res[maxn];
int fa[maxn],b[maxn],ed[maxn],num[maxn],To[maxn];
int dep[maxn],top[maxn],son[maxn],st[maxn];
int head[maxn],pre[maxn],a[maxn],ans[maxn];
struct edge{int fr,to,nxt;}e[maxn];
struct question{int l,r,k,now;}q[maxn];
int read(){
int s=0,w=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-') w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') s=(s<<1)+(s<<3)+ch-'0',ch=getchar();
return s*w;
}
void addedge(int fr,int to){
e[++tot].fr=fr;e[tot].to=to;
e[tot].nxt=head[fr];head[fr]=tot;
}
void Add(int x){++num[x];++res[num[x]];}
void Del(int x){--res[num[x]];--num[x];}
bool cmp(question a,question b){
return (a.l/len)^(b.l/len)?a.l<b.l:a.r<b.r;
}
void dfs(int u,int fat){
dfn[u]=++cnt;pre[cnt]=a[u];siz[u]=1;
for(int i=head[u];i;i=e[i].nxt){
int to=e[i].to;
if(to==fat) continue;
dfs(to,u);
siz[u]+=siz[to];
}
}
void Ask(){
for(int i=1,u,k;i<=m;i++){
u=read();k=read();
q[i].l=dfn[u];
q[i].r=dfn[u]+siz[u]-1;
q[i].k=k;q[i].now=i;
}
}
void build(){
n=read();m=read();len=sqrt(n+0.5);
for(int i=1;i<=n;i++)b[i]=a[i]=read();
sort(b+1,b+n+1);all=unique(b+1,b+n+1)-b-1;
for(int i=1;i<=n;i++)a[i]=lower_bound(b+1,b+all+1,a[i])-b;
for(int i=1,fr,to;i<=n-1;i++){
fr=read();to=read();
addedge(fr,to);addedge(to,fr);
}
dfs(1,0);Ask();sort(q+1,q+m+1,cmp);
}
int main(){
build();
for(int i=1;i<=m;i++){
while(L<q[i].l) Del(pre[L++]);
while(L>q[i].l) Add(pre[--L]);
while(R<q[i].r) Add(pre[++R]);
while(R>q[i].r) Del(pre[R--]);
ans[q[i].now]=res[q[i].k];
}
for(int i=1;i<=m;i++) printf("%d\n",ans[i]);
return 0;
}
COT2 - Count on a tree II
给定 \(n\) 个结点的树,每个结点有一种颜色。
\(m\) 次询问,每次询问给出 \(u,v\),回答 \(u,v\) 之间的路径上的结点的不同颜色数。
这个题和刚刚那个题有些不同,那个题是询问子树之中的数,这个题是任意两个数之间的颜色数。
dfs序无法搞这个题,因为无法处理两个点的LCA的贡献,但是欧拉序可以
欧拉序的核心思想是:当访问到点 \(i\) 时,加入序列,然后访问 \(i\) 的子树,当访问完时,再把 \(i\) 加入序列
所以一棵以 \(i\) 点为根的子树的欧拉序列的左右两端必定都是 \(i\) 点的欧拉序
然后怎么处理这个题呢,举个例子
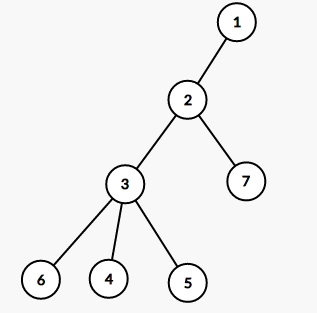
这棵树的欧拉序为 1 2 3 4 4 5 5 6 6 3 7 7 2 1
这里我们设 \(st_i\) 表示访问到 \(i\) 时加入欧拉序的时间,\(ed_i\) 表示回溯经过 \(i\) 时加入欧拉序的时间
先假设 \(st_x<st_y\)
这里有两种情况
-
若 \(lca(x,y) = x\),这时 \(x,y\) 在一条链上,那么 \(st_x\) 到 \(st_y\) 这段区间中,有的点出现了两次,有的点没有出现过,这些点都是对答案没有贡献的,我们只需要统计出现过 \(1\) 次的点就好
-
若 \(lca(x,y)≠x\),此时 \(x,y\) 位于不同的子树内,我们只需要按照上面的方法统计 \(ed_x\) 到$ st_y$ 这段区间内的点
比如
当询问为 2,6 时,\((st_2,st_6)=\) 2 3 4 4 5 5 6 ,其中 \(4,5\) 这两个点都出现了两次,因此不统计进入答案
当询问为 4,7 时,\((ed_4,st_7)=\) 4 5 5 6 6 3 7 但是我们没有统计LCA,所以需要特判LCA
然后问题就解决了,剩下的看代码
#include<queue>
#include<cmath>
#include<vector>
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<climits>
#include<iostream>
#include<algorithm>
#define maxn 1000100
#define INF 0x3f3f3f3f
//#define int long long
using namespace std;
int n,m,len,cnt,tot,Ans,all,L=1,R;
int dfn[maxn],siz[maxn],used[maxn];
int fa[maxn],b[maxn],ed[maxn],num[maxn];
int dep[maxn],top[maxn],son[maxn],st[maxn];
int head[maxn],pre[maxn],a[maxn],ans[maxn];
struct edge{int fr,to,nxt;}e[maxn];
struct question{int l,r,now,lca;}q[maxn];
vector<int> v[maxn];
int read(){
int s=0,w=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-') w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') s=(s<<1)+(s<<3)+ch-'0',ch=getchar();
return s*w;
}
bool cmp(question a,question b){
return st[a.l]^st[b.l]?st[a.l]<st[b.l]:a.r<b.r;
}
void addedge(int fr,int to){
e[++tot].fr=fr;e[tot].to=to;
e[tot].nxt=head[fr];head[fr]=tot;
}
void dfs1(int u,int fat){
dep[u]=dep[fat]+1;
siz[u]=1;fa[u]=fat;
dfn[u]=++cnt;pre[cnt]=u;
for(int i=head[u];i;i=e[i].nxt){
int to=e[i].to;
if(to==fat) continue;
dfs1(to,u);siz[u]+=siz[to];
if(siz[son[u]]<siz[to]) son[u]=to;
}
ed[u]=++cnt;pre[cnt]=u;
}
void dfs2(int u,int tp){
top[u]=tp;
if(son[u]) dfs2(son[u],tp);
for(int i=head[u];i;i=e[i].nxt){
int to=e[i].to;
if(to==fa[u]||to==son[u]) continue;
dfs2(to,to);
}
}
int LCA(int x,int y){
while(top[x]!=top[y]){
if(dep[top[x]] < dep[top[y]]) swap(x,y);
x=fa[top[x]];
}
return dep[x]<dep[y]?x:y;
}
void Ask(){
for(int i=1,fr,to;i<=m;i++){
fr=read();to=read();
if(dfn[fr]>dfn[to]) swap(fr,to);
int lca=LCA(fr,to);q[i].now=i;
if(fr==lca) q[i].l=dfn[fr],q[i].r=dfn[to];
else q[i].l=ed[fr],q[i].r=dfn[to],q[i].lca=lca;
}
}
void build(){
n=read();m=read();len=sqrt(n+0.5);
for(int i=1;i<=n<<1;i++) st[i]=i/len+1;
for(int i=1;i<=n;i++) a[i]=read(),b[i]=a[i];
sort(b+1,b+n+1);all=unique(b+1,b+n+1)-b-1;
for(int i=1;i<=n;i++)a[i]=lower_bound(b+1,b+all+1,a[i])-b;
for(int i=1,fr,to;i<=n-1;i++){
fr=read();to=read();
addedge(fr,to);addedge(to,fr);
}
dfs1(1,0);dfs2(1,1);
Ask();sort(q+1,q+m+1,cmp);
}
void Add(int x){Ans+=(++num[x]==1);}
void Del(int x){Ans-=(--num[x]==0);}
void Deal(int x){used[x]?Del(a[x]):Add(a[x]);used[x]^=1;}
signed main(){
build();
for(int i=1;i<=m;i++){
while(L<q[i].l) Deal(pre[L++]);
while(L>q[i].l) Deal(pre[--L]);
while(R<q[i].r) Deal(pre[++R]);
while(R>q[i].r) Deal(pre[R--]);
if(q[i].lca) Deal(q[i].lca);
ans[q[i].now]=Ans;
if(q[i].lca) Deal(q[i].lca);
}
for(int i=1;i<=m;i++) printf("%d\n",ans[i]);
return 0;
}
复杂度证明
区间排序
建个结构体,用 sort 跑一遍即可。平均复杂度 \(O(n\log n)\)。
左指针的移动
设每个块 \(i\) 中分布有 \(x_i\) 个左端点
由于莫队的添加、删除操作复杂度为 \(O(1)\),那么处理块 \(i\) 的最坏时间复杂度是 \(O(x_i\sqrt n)\),指针跨越整块的时间复杂度为 \(O(\sqrt{n})\),最坏需要跨越 \(n\) 次
总复杂度 \(O(\sum{x_in\sqrt n}+n\sqrt n)=O(n\sqrt n)\)
右指针的移动
设每个块 \(i\) 中分布有 \(x_i\) 个左端点,由于左端点同块的区间右端点有序,那么对于这 \(x_i\) 个区间,右端点最坏只需总共 \(O(n)\) 的时间跳(最坏需跳完整个序列),总共 \(n\sqrt n\)个块,总复杂度 \(O(n\sqrt n)\)
至此可得出,莫队算法的总时间复杂度为 \(O(n\sqrt n)+O(n\sqrt n)+O(n\log n)=O(n\sqrt n)\)
与排序之前相比,降低了一个根号之多,有了质的提升
优化方式
目前我只知道奇偶性优化,之后的学习了会再补
由于在当前块所有的询问完成之后,按照朴素的莫队方法,处理下一个块时会将右指针移回来
略过了中间的询问,从而造成不必要的浪费
如果在回来的过程中顺便处理掉他们,时间复杂度就会优秀不少
具体就是把块按奇偶分,奇数块从左到右扫,偶数块从右到左扫
bool cmp(node x, node y){
return (x.l / len) ^ (y.l / len) ? x.l < y.l : ((x.l / len) & 1) ? x.r < y.r : x.r > y.r;
}
另外,还可以用规定块长的方法优化,但是并不稳定
对于一般的情况,我们都习惯分成 \(\sqrt n\) 块,但是,当询问数 \(m\) 与区间长度 \(n\) 范围差距过大时,这样做的效率并不明显,而是要根据范围的差值大小来适当增加或缩短块长
另:各种莫队的时间复杂度不一,而且比较玄学,这里就不多赘述,想了解的详见 OI Wiki
例题
[国家集训队]小Z的袜子
小B的询问
数列找不同
[CQOI2018]异或序列
【模板】回滚莫队&不删除莫队
[WC2013] 糖果公园

 浙公网安备 33010602011771号
浙公网安备 33010602011771号