初识二分法
二分查找只能用在插入、删除操作不频繁,一次排序多次查找的场景中。
针对动态变化的数据集合,二分查找将不再适用。
数据量太小不适合二分查找,优势微乎其微,杀鸡用牛刀,遍历就够了
数据量太大也不适合二分查找。二分查找底层依赖数组这种数据结构的,所以太大的数据用数组存储就比较吃力,甚至内存不足以支持
例:在一个给定的有序数组[以下默认为升序]中快速寻找某个数的下标
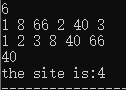
循环实现:
1 #include<iostream> 2 #include<algorithm> 3 using namespace std; 4 int main() 5 { 6 int n; 7 cin>>n; 8 int a[n]; 9 for(int i=0;i<n;i++){ 10 cin>>a[i]; 11 } 12 sort(a,a+n); 13 for(int i=0;i<n;i++){ 14 cout<<a[i]<<' '; 15 } 16 cout<<endl; 17 int value; 18 cin>>value; 19 int low=0,high=n-1,mid; 20 int ret=1; 21 while(low<=high) 22 { 23 mid=(low+high)/2; 24 if(a[mid]==value){ 25 cout<<"the site is:"<<mid; 26 ret=0; 27 break; 28 }else if(a[mid]<value){ 29 low=mid+1; 30 }else{ 31 high=mid-1; 32 } 33 } 34 if(ret){ 35 cout<<"no found"; 36 } 37 return 0; 38 }
容易出错的 3 个地方。
1. 循环退出条件是 low<=high,而不是 low<high。
2.mid=(low+high)/2 这种写法是有问题的。因为如果 low和 high比较大的话,两者之和就有可能会溢出。改进的方法是将mid的计算方式写成low+(high-low) 2。更进一步,如果要将性能优化到极致的话,可以将这里的除以 2操作转化成位运算low+((high-low)>>1)或者(low&high)+((low^high)>>1)[注意运算符的优先级,千万不能写成这样:low+(high-low)>>1]。相比除法运算来说,计算机处理位运算要快得多。
3.low 和 high 的更新.如果直接写成 low=mid 或者 high=mid,就可能会发生死循环。
递归实现(函数部分):
1 int search(int a[],size,value){ 2 return searchValue(a,0,size-1,value); 3 } 4 int searchValue(int a[],int low,int high,int value){ 5 if(low>high){ 6 return -1; 7 } 8 int mid = low+((high - low)>>1); 9 if(a[mid]<value){ 10 return mid; 11 }else if(a[mid]<value){ 12 searchValue(a,mid+1,high,value); 13 }else{ 14 searchValue(a,low,mid-1,value); 15 } 16 }
本文来自博客园,作者:泥烟,CSDN同名, 转载请注明原文链接:https://www.cnblogs.com/Knight02/p/14736477.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号