初识卷积神经网络
初识卷积神经网络
1️⃣输入
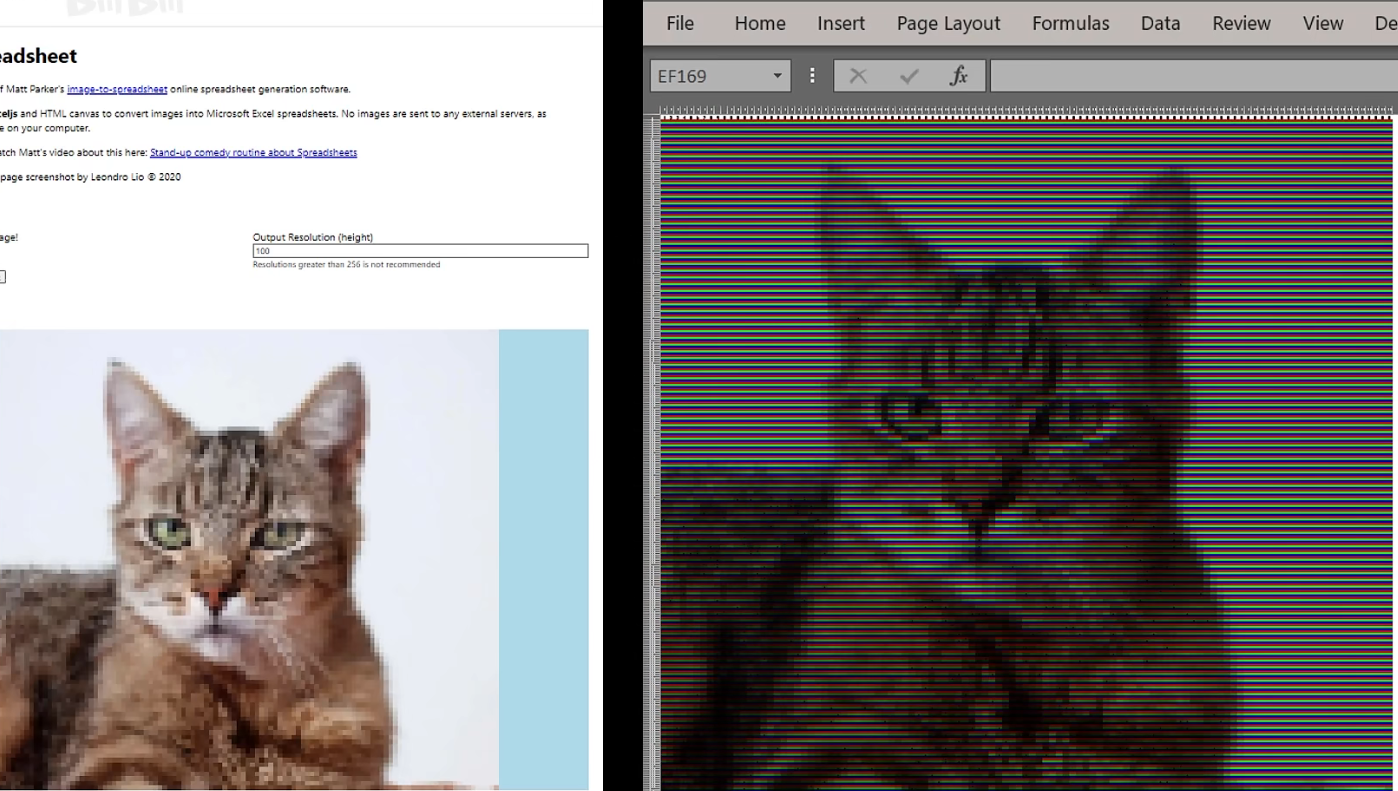

颜色背后的具体像素数值就是我们输入端的基础数据
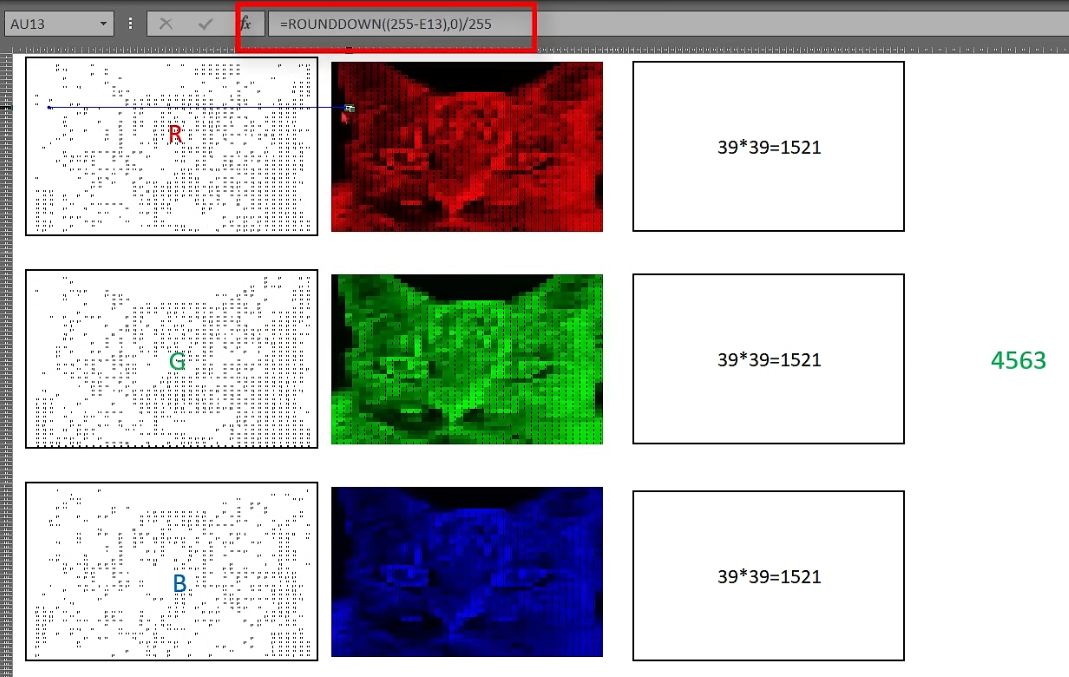
把红绿蓝三色数值抓取出来, 并标准化至[0, 1]的数值区域内
形成3个39*39矩阵
2️⃣特征提取 (卷积核/特征过滤器)
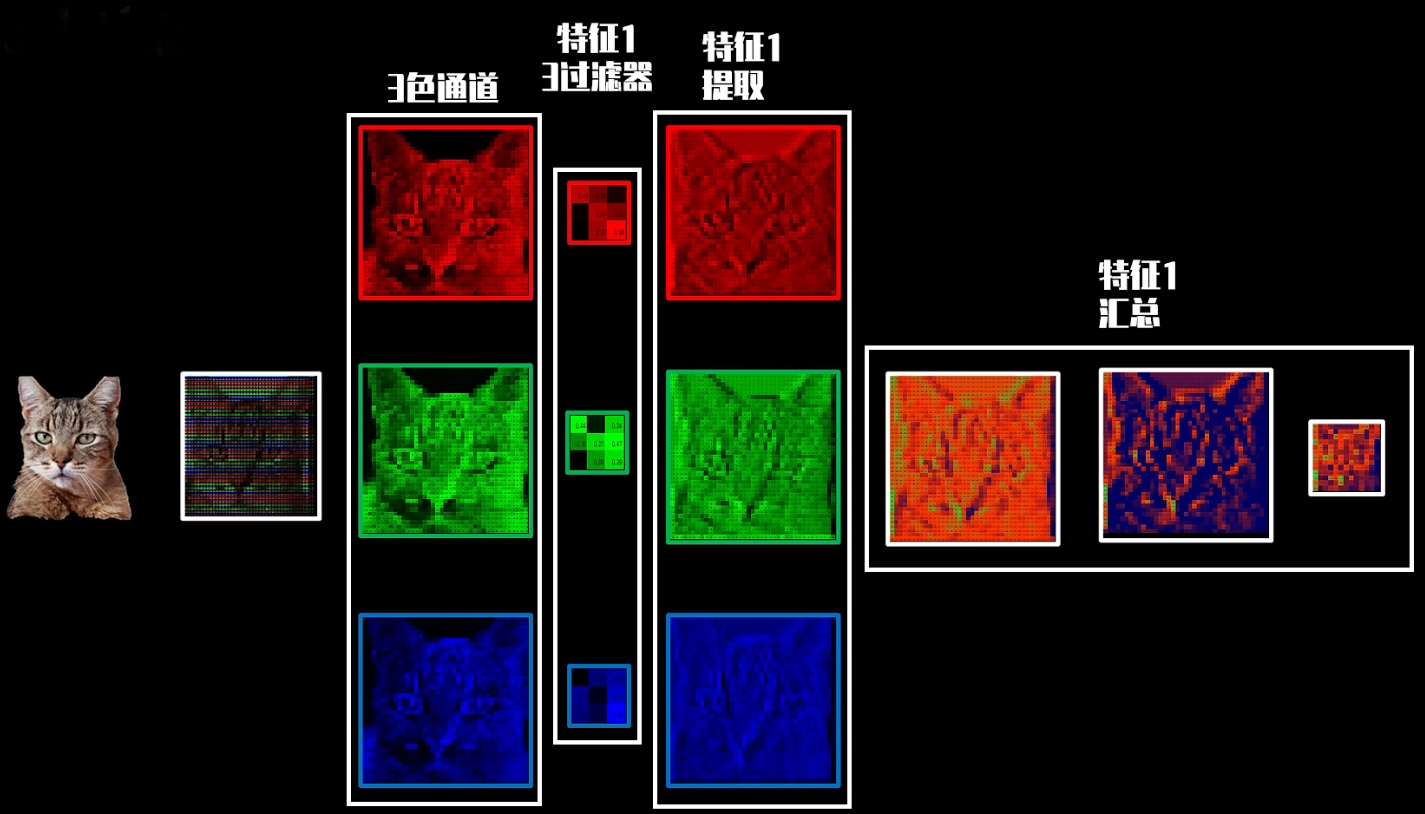
初始特征过滤器中的值以及是预设的, 需要后期训练优化
特征数量也是预设的, 特征为N时, 需要N*3个特征过滤器
特征过滤器维数越大, 特征数量越多, 需要训练的参数越多, 时间成本越大
👉模型设计中可以尝试不同的参数配置, 综合比较训练成本和成果
padding 防止边缘信息被遗漏


3个特征结果矩阵相加, 同时加上一个预设且需要后期训练的bias偏差参数, 得到了融合3个颜色特征信息的特征图
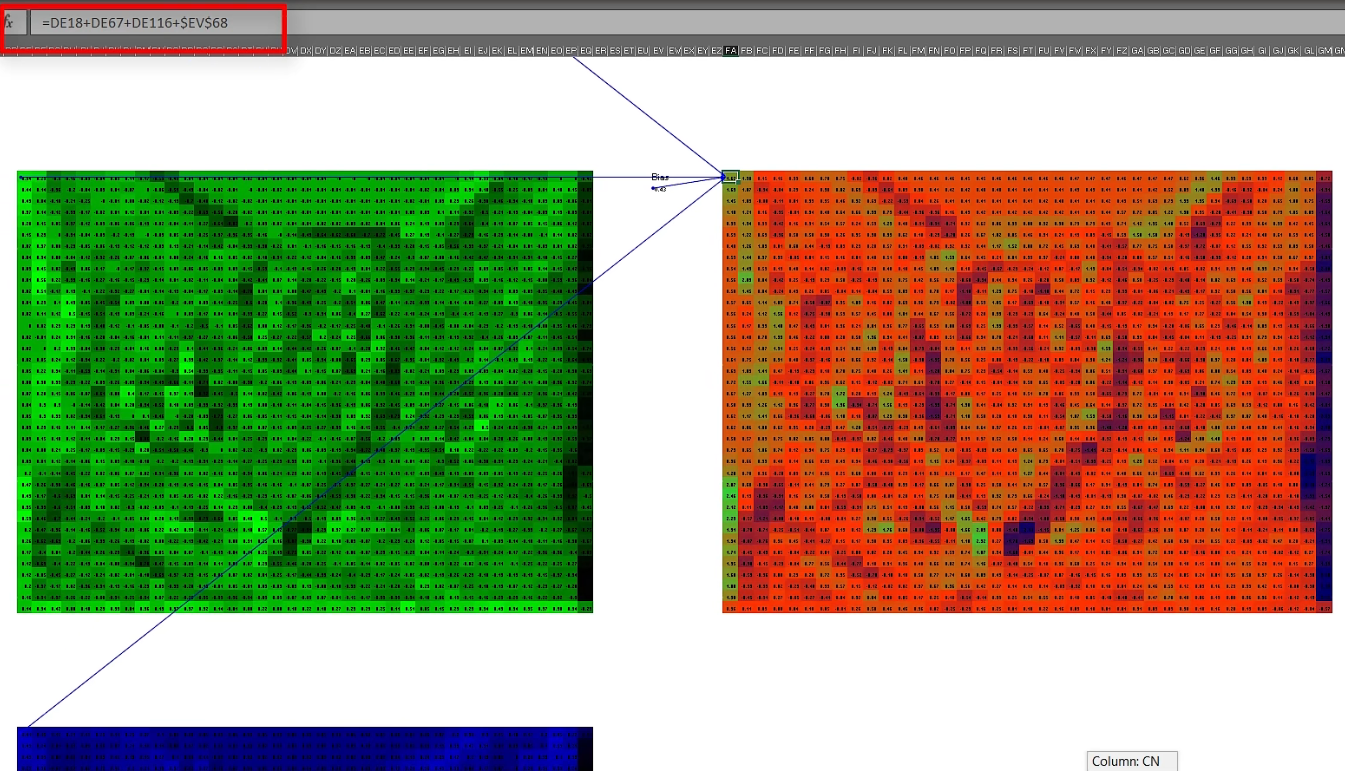
将该特征图经过ReLU激活函数处理
39393 👉 39391
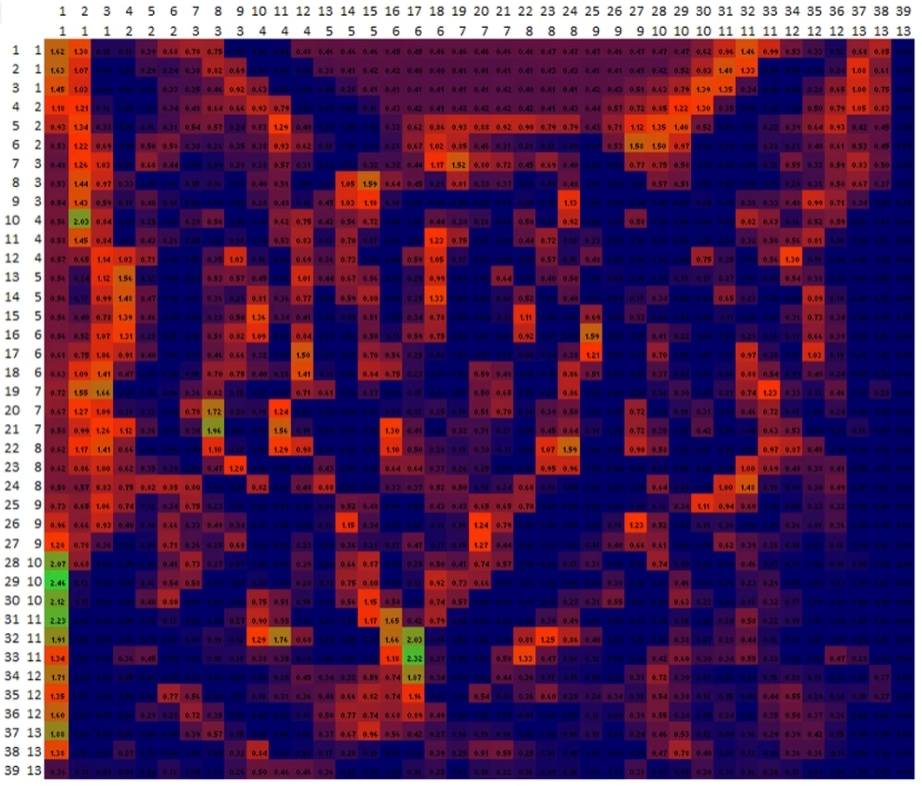
3️⃣最大池化 Max Pooling
提取最突出的特征
将上图分割成13133个3*3区域, 每个区域提取最大值
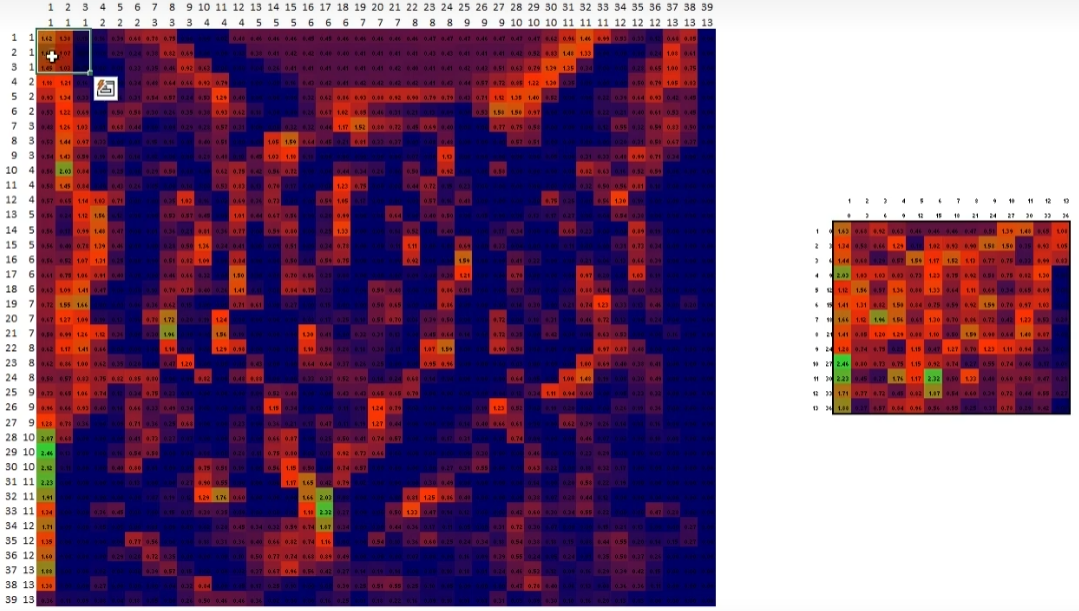
4️⃣扁平化处理
1313矩阵 👉 1691数据条
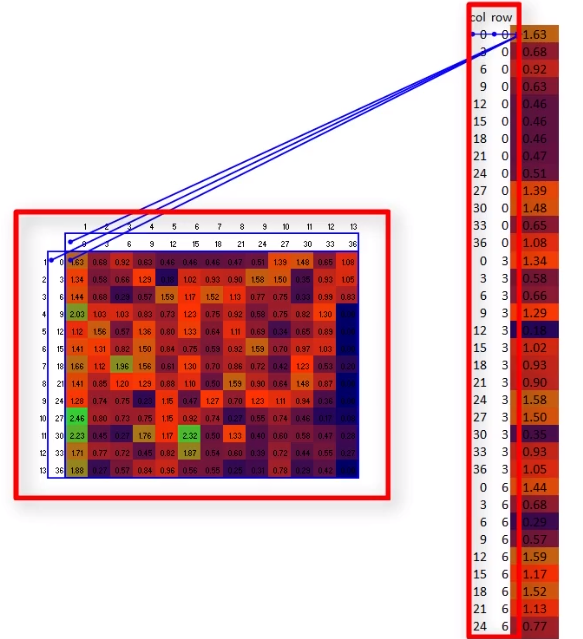
若有新的特征图像需要提取, 则将"数据条"按顺序接入即可
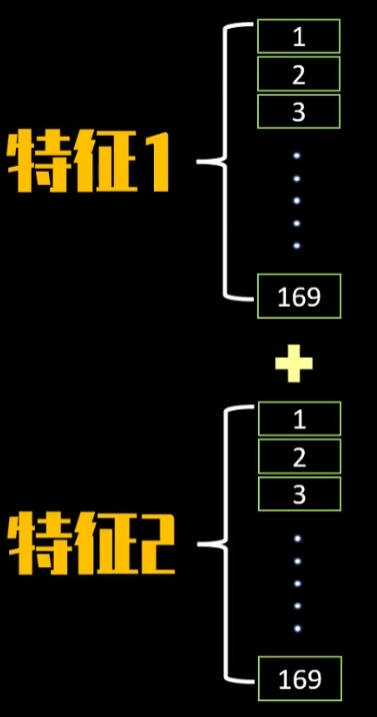
5️⃣全连接神经网络
将169个数据前馈至全连接神经网络中,
每个神经元有对169个权重参数和1个bias偏差参数,
分别与对应神经元的对应权重相乘再相加
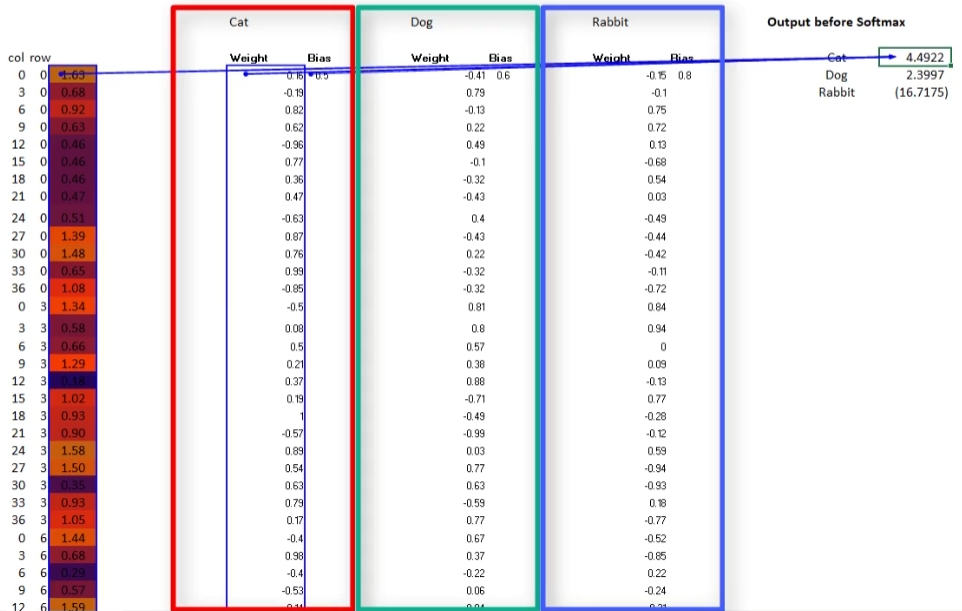
6️⃣输出层
softmax函数, 将绝对数值结果转化为概率结果
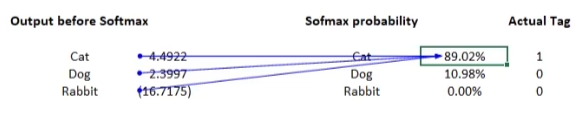
之后训练中, CNN模型根据损失函数逆向推导、调整权重和偏差参数, 不断提升模型准确率
7️⃣损失函数(暂略)
卷积运算的物理意义怎么理解,为什么经过卷积的图像再做最大池化能保留原信息,如果直接对原图像最大池化却不能?
卷积操作实际上对应于信号处理中的滤波,频域的相乘(哈达玛积)对应着时域的卷积,具体在图像中就是过滤出特定的信息,比如轮廓中的竖直线条和水平线条等,这样的信息是稀疏的,占比较少的元素才是关键,而剩下大部分元素都是留白,因此再进行池化虽然会丢失信息,但丢失的信息大部分都是无效的留白部分的信息,关键信息虽然也有部分丢失,但是占比反而会提高,这是我个人的一点理解
模型小的话可以自己试一试手动设计卷积核,在现在的深度学习里卷积核其实是作为参数自动训练出来的,因此其代表的具体意义可能可以解释,也可能无法解释,这也是深度学习现阶段的一个问题,就是不可解释性
本文来自博客园,作者:泥烟,CSDN同名, 转载请注明原文链接:https://www.cnblogs.com/Knight02/articles/16567307.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号