
理解JS闭包的几个小实验
学了JavaScript有一段时间了,但是对闭包还是不太理解,于是怀着心中的疑问做了几个小实验,终于有点明白了。
首先看一下MDN上的定义:闭包是函数和声明该函数的词法环境的组合。
简单来说,闭包是一种现象。
我在搞清楚了2个概念后,理解了闭包。
首先是关于函数以及函数调用的概念:
我们来做一个简单的实验:
1 function foo () { 2 var a = 1; 3 function bar () { 4 console.log(a) 5 } 6 return bar; 7 } 8 9 var first = foo(); 10 console.log(first); 11 12 // 显示结果: 13 // ƒ bar () { 14 // console.log(a) 15 // }
作为一个初学者,有一些小细节很容易干扰我的判断。
首先要理解的是function f () {}是在声明一个函数,要执行这个函数必须用f()进行调用。
f()调用函数后,js引擎会执行函数中的代码,如果函数最后有写return ...函数执行完毕才有返回值。
1 var first = foo();
表示把函数foo执行完毕后的返回值赋值给first,函数foo执行的操作是声明了一个变量a,以及一个函数bar,然后把函数bar作为返回值返回。注意:不是把bar的执行结果返回,而是把这个函数本身返回。所以first就指向了函数bar。
其次是关于执行环境与作用域的概念
作用域的定义:作用域是一套规则,用于确定在何处以及如何查找标识符。
我对作用域的理解是:代码起作用的范围。
执行环境的定义:执行环境定义了变量或函数有权访问的其他数据。每个执行环境都有三个重要的属性,变量对象(Variable object,VO)、作用域链(Scope chain)和 this。环境中定义的所有变量和函数都保存在变量对象中
我对执行环境的理解:存储一块代码中定义的所有的变量和函数的值。
因为全局作用域范围最广,所以函数内部也可以访问到全局变量。
函数内部代码执行的时候,发现某个变量的值在自己的执行环境中没有,就需要去上级执行环境中找。函数执行完毕后,当前函数的执行环境就被销毁,所以上级函数没有办法访问内部函数中声明的变量。
第二个小实验:
1 function foo () { 2 var a = 1; 3 function bar () { 4 console.log(a) 5 } 6 return bar; 7 } 8 9 var first = foo(); 10 console.dir(first);
显示结果如图所示:
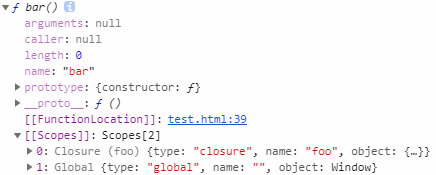
first就是函数bar,它能访问自己的作用域,上级foo的作用域,以及全局作用域。
当js执行first的时候,first能访问自己的作用域,上级foo的作用域,以及全局作用域。这种现象就是闭包。
闭包最大用处有两个:一个是前面提到的可以读取函数内部的变量,另一个就是让这些变量的值始终保持在内存中。所以我们就可以利用闭包来创建模块机制:
1 function count() { 2 var number = 0; 3 return{ 4 add : function(x){ 5 if(x==undefined) { 6 number += 1; 7 }else{ 8 number +=x; 9 } 10 }, 11 reduce: function(x) { 12 if(x==undefined) { 13 number -= 1; 14 }else{ 15 number -=x; 16 } 17 }, 18 times: function() { 19 return number; 20 } 21 } 22 }
我们可以创建复数个加法器,而互不影响。
我关于闭包的理解就到这里了,如果你还不明白,就自己动手写代码试验吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号