
利用sklearn进行tfidf计算
转自:http://blog.csdn.net/liuxuejiang158blog/article/details/31360765?utm_source=tuicool
在文本处理中,TF-IDF可以说是一个简单粗暴的东西。它可以用作特征抽取,关键词筛选等。

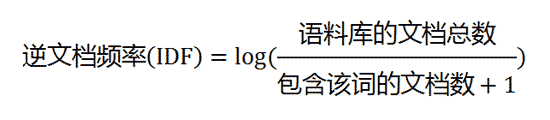
以网页搜索“核能的应用”为例,关键字分成“核能”、“的”、“应用”。根据直觉,我们知道,包含这三个词较多的网页比包含它们较少的网页相关性强。但是仅仅这样,就会有漏洞,那就是文本长的比文本短的关键词数量要多,所以相关性会偏向长文本的网页。所以我们需要归一化,即用比例代替数量。用关键词数除以总的词数,得到我们的“单文本词频(Term Frequency)”最后的TF为各个关键词的TF相加。这样还不够,还是有漏洞。像“的”、“和”等这样的常用字,对衡量相关性没什么作用,但是几乎所有的网页都含有这样的字,所以我们要忽略它们。于是就有了IDF(Inverse Document Frequency)
原理非常简单,结合单词的词频和包含该单词的文档数,统计一下,计算TF和IDF的乘积即可。但是自己的写的代码,在运算速度上,一般不尽人意,在自己写了一段代码之后,为了方便检验结果是否正确、效率如何,在网上寻找了一些开源代码。这里用到了sklearn里面的TF-IDF。主要用到了两个函数:CountVectorizer()和TfidfTransformer()。CountVectorizer是通过fit_transform函数将文本中的词语转换为词频矩阵,矩阵元素weight[i][j] 表示j词在第i个文本下的词频,即各个词语出现的次数;通过get_feature_names()可看到所有文本的关键字,通过toarray()可看到词频矩阵的结果。TfidfTransformer也有个fit_transform函数,它的作用是计算tf-idf值。
贴代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-\
import string
import sys
reload(sys)
sys.setdefaultencoding('utf8')
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
if __name__ == "__main__":
corpus = []
tfidfdict = {}
f_res = open('sk_tfidf.txt', 'w')
for line in open('seg.txt', 'r').readlines(): #读取一行语料作为一个文档
corpus.append(line.strip())
vectorizer=CountVectorizer()#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer=TfidfTransformer()#该类会统计每个词语的tf-idf权值
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))#第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
word=vectorizer.get_feature_names()#获取词袋模型中的所有词语
weight=tfidf.toarray()#将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
for i in range(len(weight)):#打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
for j in range(len(word)):
getword = word[j]
getvalue = weight[i][j]
if getvalue != 0: #去掉值为0的项
if tfidfdict.has_key(getword): #更新全局TFIDF值
tfidfdict[getword] += string.atof(getvalue)
else:
tfidfdict.update({getword:getvalue})
sorted_tfidf = sorted(tfidfdict.iteritems(),
key=lambda d:d[1], reverse = True )
for i in sorted_tfidf: #写入文件
f_res.write(i[0] + '\t' + str(i[1]) + '\n')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号