ElasticSearch-logstash数据同步
logstash中间件实现全量,增量同步
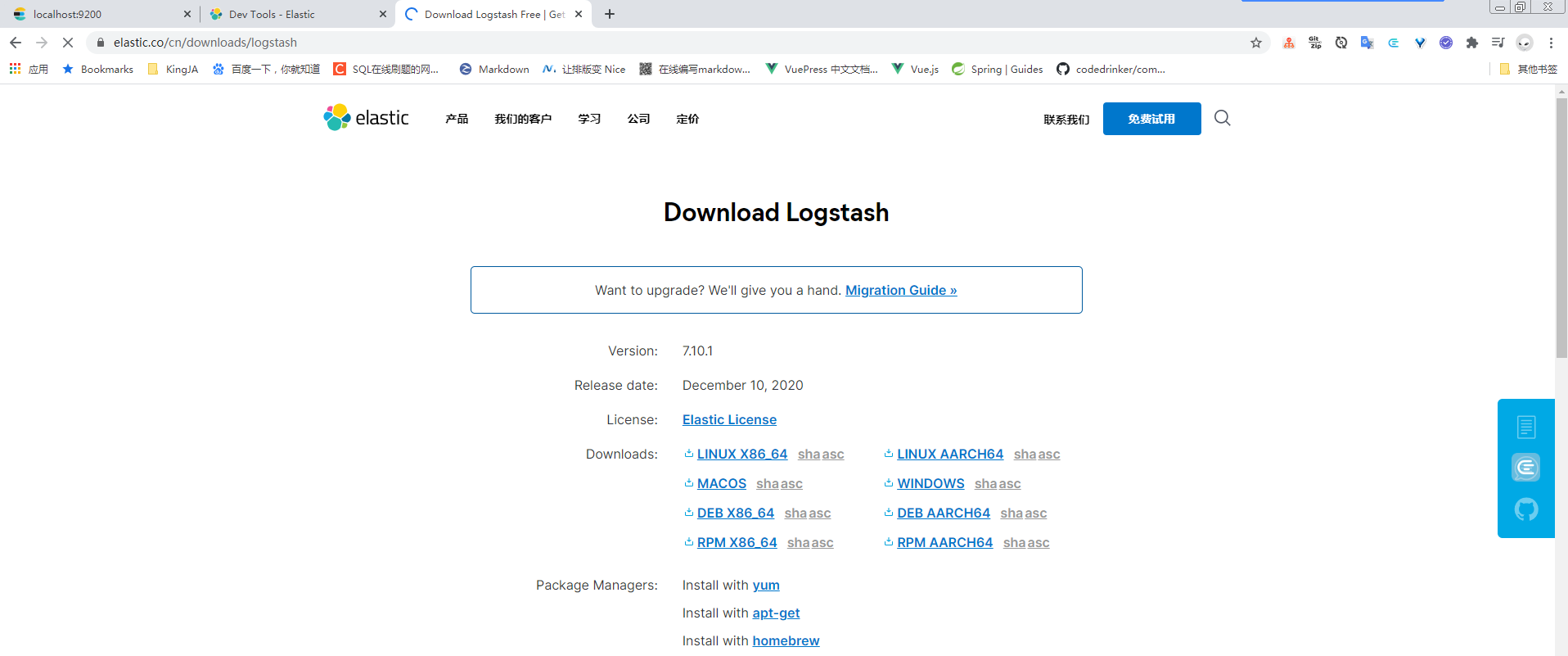
1、下载安装
选择和ElasticSearch匹配的版本下载
2.操作
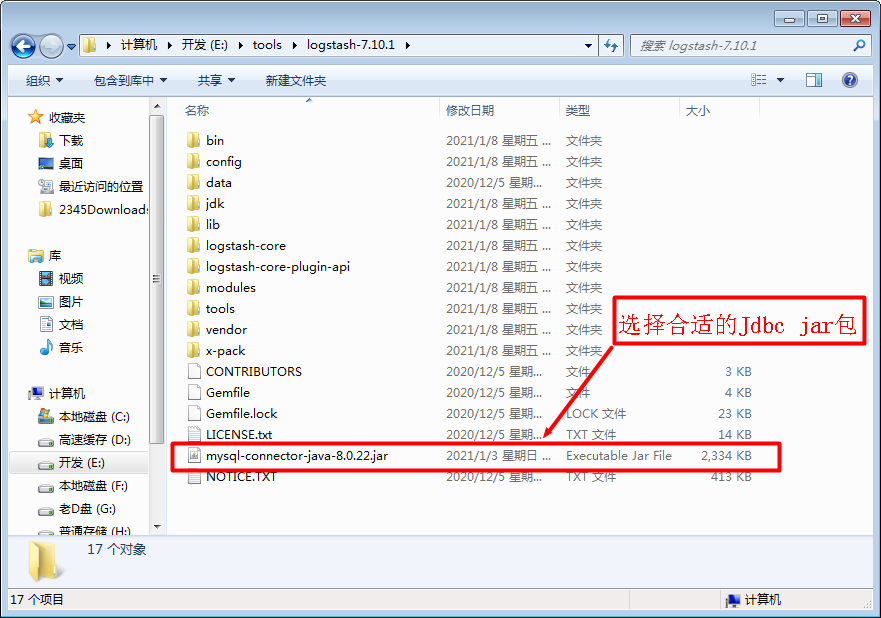
2.1下载合适jdbc jar包
这里选择mysql测试
2.2创建数据库
CREATE DATABASE blog;
USE blog;
CREATE TABLE `t_blog` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`title` varchar(60) DEFAULT NULL COMMENT '博客标题',
`author` varchar(60) DEFAULT NULL COMMENT '博客作者',
`content` mediumtext COMMENT '博客内容',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb4
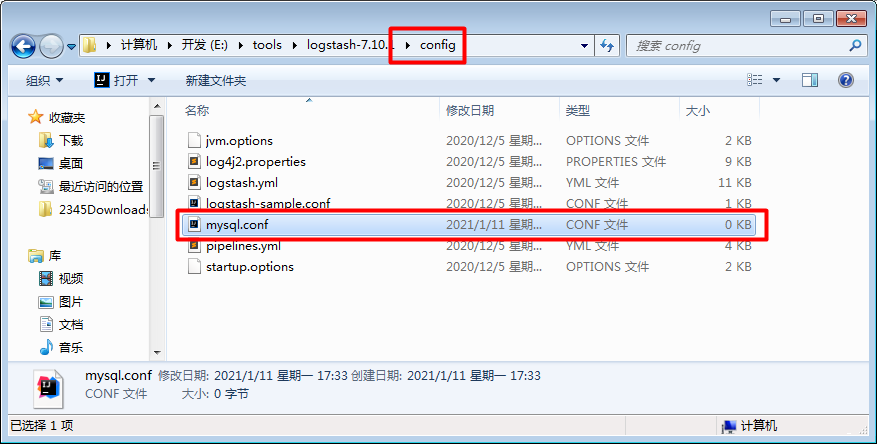
2.3创建配置文件
config下创建mysql.conf配置文件
input{
jdbc{
# jdbc驱动包位置
jdbc_driver_library => "E:\\tools\\logstash-7.10.1\\mysql-connector-java-8.0.22.jar"
# 要使用的驱动包类
jdbc_driver_class => "com.mysql.jdbc.Driver"
# mysql数据库的连接信息
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/blog"
# mysql用户
jdbc_user => "root"
# mysql密码
jdbc_password => "root"
# 定时任务,多久执行一次查询,默认一分钟,如果想要没有延迟,可以使用 schedule => "* * * * * *"
schedule => "* * * * *"
# 清空上传的sql_last_value记录
clean_run => true
# 你要执行的语句
statement => "select * FROM t_blog WHERE update_time > :sql_last_value AND update_time < NOW() ORDER BY update_time desc"
}
}
output {
elasticsearch{
# es host : port
hosts => ["127.0.0.1:9200"]
# 索引
index => "blog"
# _id
document_id => "%{id}"
}
}
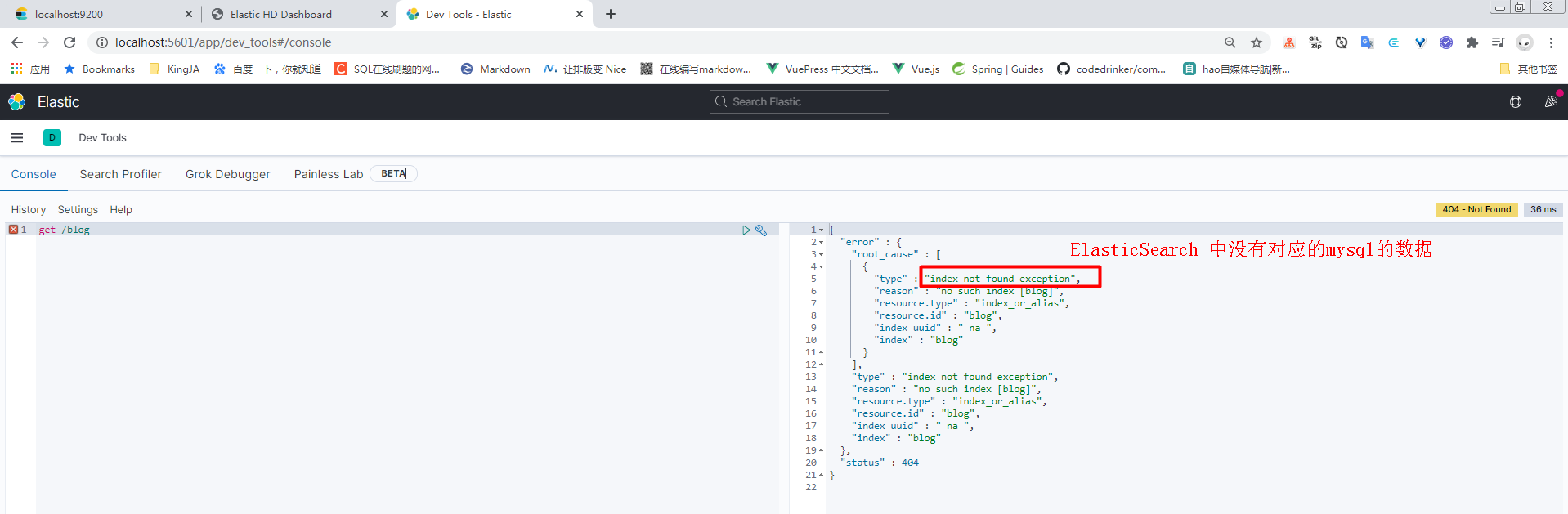
2.4执行同步
首先确定ElasticSearch中没有同步的数据
bin目录下执行
logstash -f ../config/mysql.conf
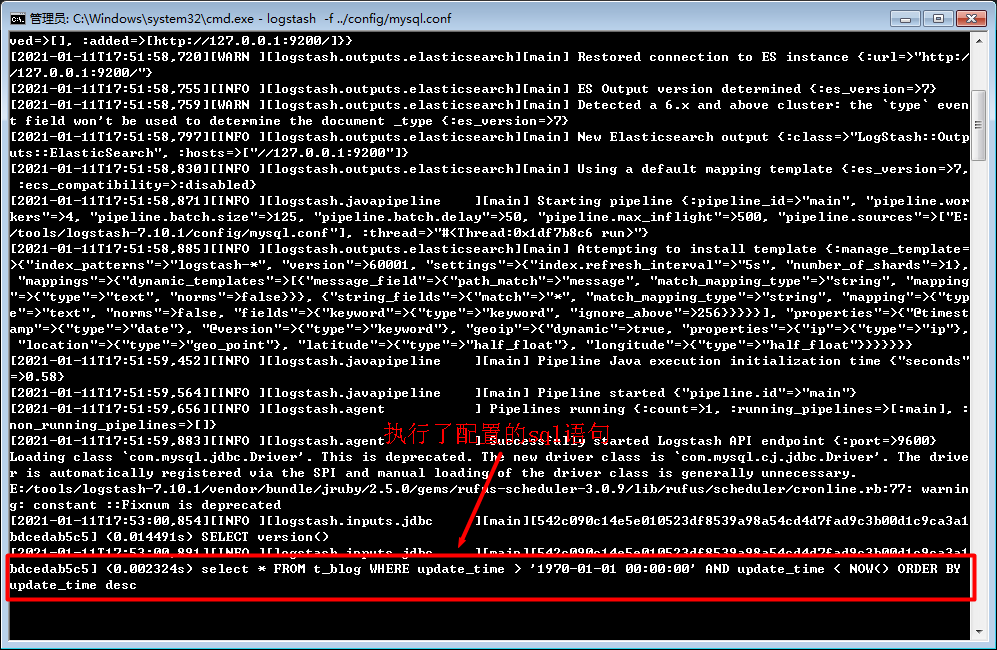
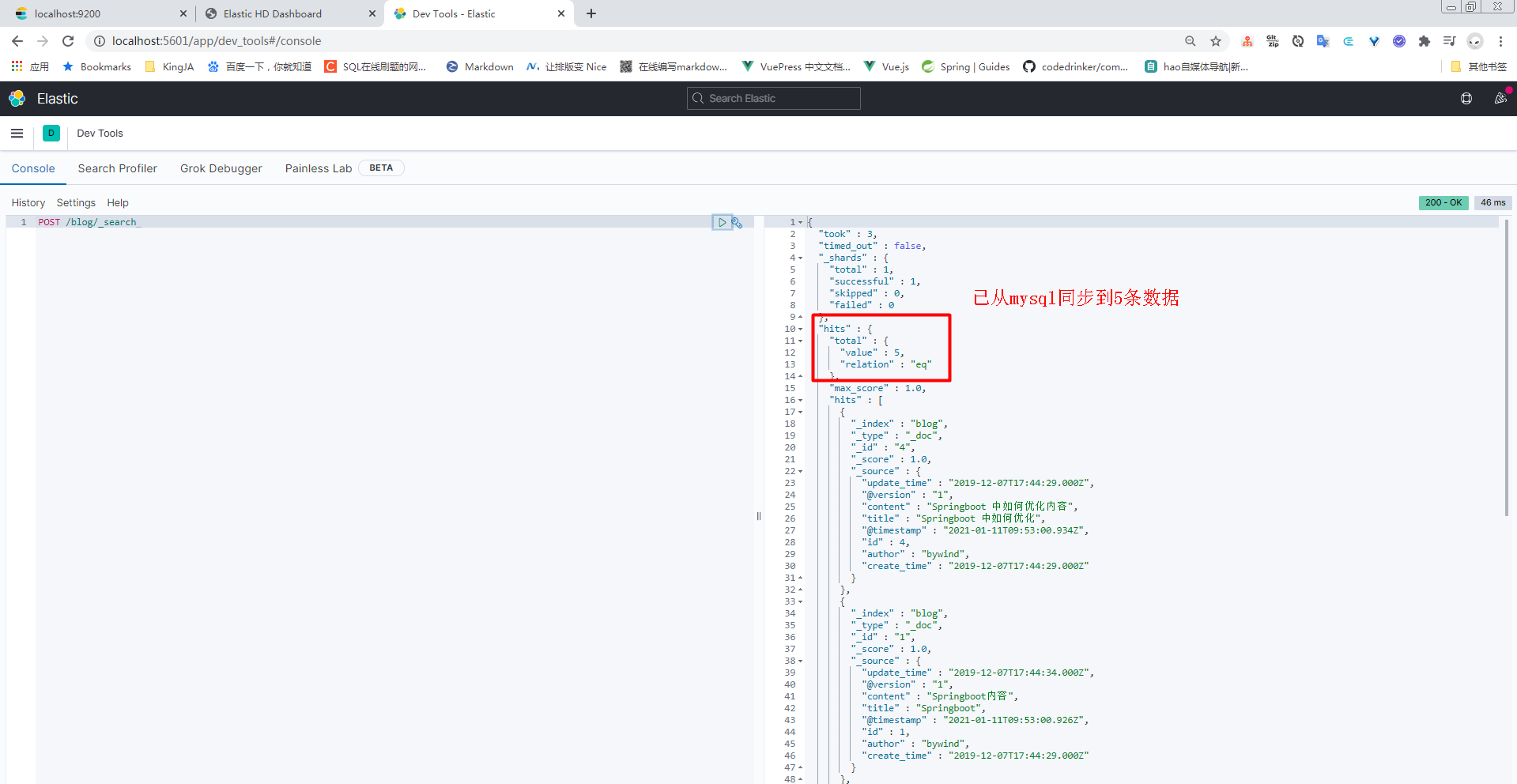
配置是1分钟执行一次
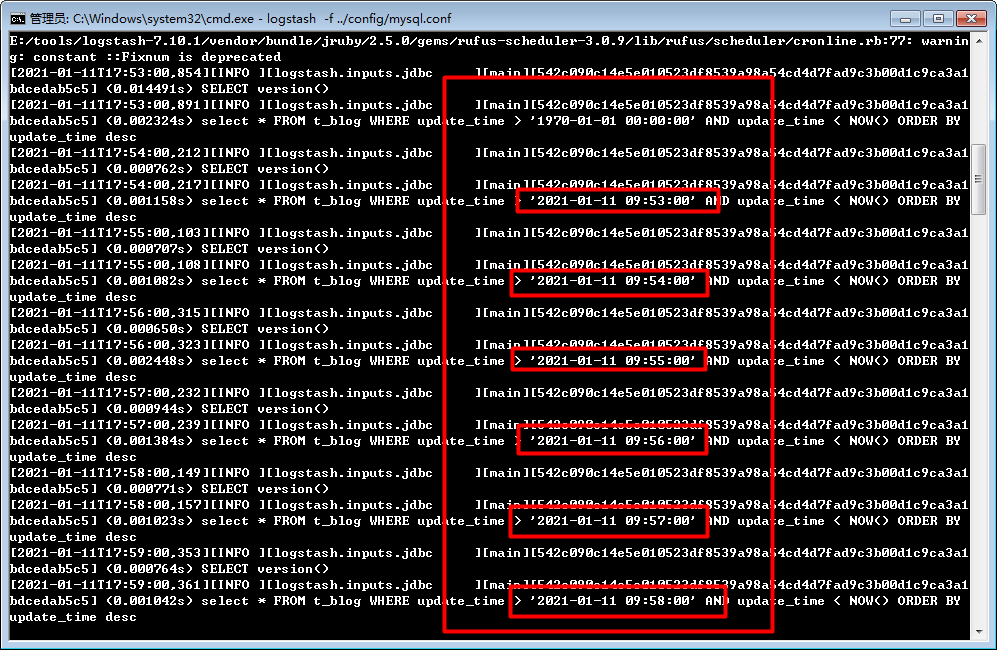
可以看出logstash确实在按我们配置的1分钟同步一次,没毛病。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号