软工作业3: 词频统计
词频统计
一、编译环境
(1)IDE:PyCharm 2018
(2)python版本:python3.6.3(Anaconda3-5.1.0 )
二、程序分析
(1)读文件到缓冲区(process_file(dst))
def process_file(dst): # 读文件到缓冲区 try: # 打开文件 file = open(dst, 'r') # dst为文本的目录路径 except IOError as s: print(s) return None try: # 读文件到缓冲区 bvffer = file.read() except: print("Read File Error!") return None file.close() return bvffer
(2)处理缓冲区,返回存放每个单词频率的字典word_freq(process_buffer(bvffer))
def process_buffer(bvffer): # 处理缓冲区,返回存放每个单词频率的字典word_freq if bvffer: # 下面添加处理缓冲区bvffer代码,统计每个单词的频率,存放在字典word_freq word_freq = {} # 将文本内容都改为小写且去除文本中的中英文标点符号 for ch in '“‘!;,.?”': bvffer = bvffer.lower().replace(ch, " ") # strip()删除空白符(包括'/n', '/r','/t');split()以空格分割字符串 words = bvffer.strip().split() for word in words: word_freq[word] = word_freq.get(word, 0) + 1 return word_freq
(3)按照单词的频数排序,输出前十的单词(output_result(word_freq))
def output_result(word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 print("单词:%s 频数:%d " % (item[0], item[1]))
(4)主程序输出前十结果
if __name__ == "__main__": dst = "src/A_Tale_of_Two_Cities.txt" # 《A_Tale_of_Two_Cities》的路径,另一组测试更改为《Gone_with_the_wind》的路径 bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq)
三、 代码风格说明
(1)python3与python2在print函数的使用上的区别:python3中,print函数要加上(),如上第一段代码的第五行。
print(s)
(2)不要使用 tab 缩进;使用任何编辑器写 Python,请把一个 tab 展开为 4 个空格;绝对不要混用 tab 和空格,否则容易出现 IndentationError。
(3)使用有意义的,英文单词或词组,绝对不要使用汉语拼音命名;变量名不要用单个字符。(除非变量名含义可从上下文很容易看出来)
for word in words: word_freq[word] = word_freq.get(word, 0) + 1
四、程序运行命令、运行结果截图
(1)编写完成 word_freq.py,在DOS窗口执行
①《Gone_with_the_wind》
运行命令:python C:/Users/asus/Desktop/software_engineering/SE16_WordCount/word_freq.py
运行截图:

②《A_Tale_of_Two_Cities》
运行命令:python C:/Users/asus/Desktop/software_engineering/SE16_WordCount/word_freq.py
运行截图:

(2)在PyCharm2018中直接运行
①《Gone_with_the_wind》
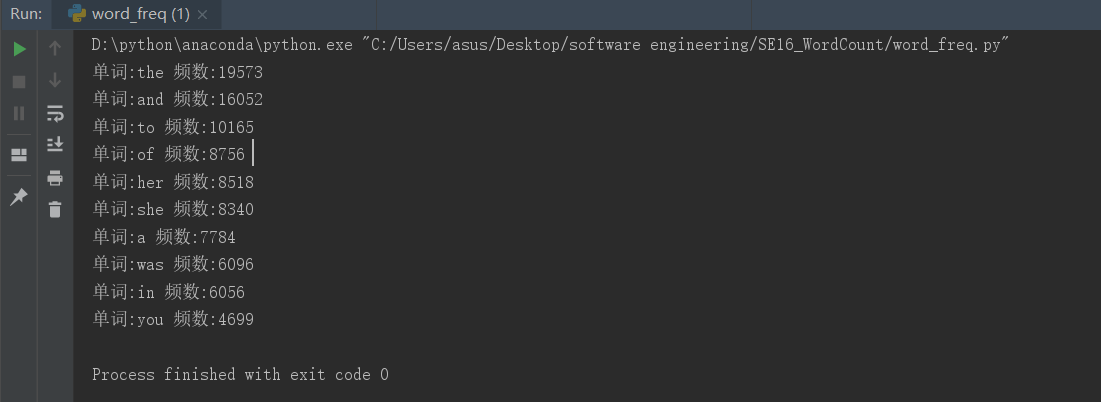
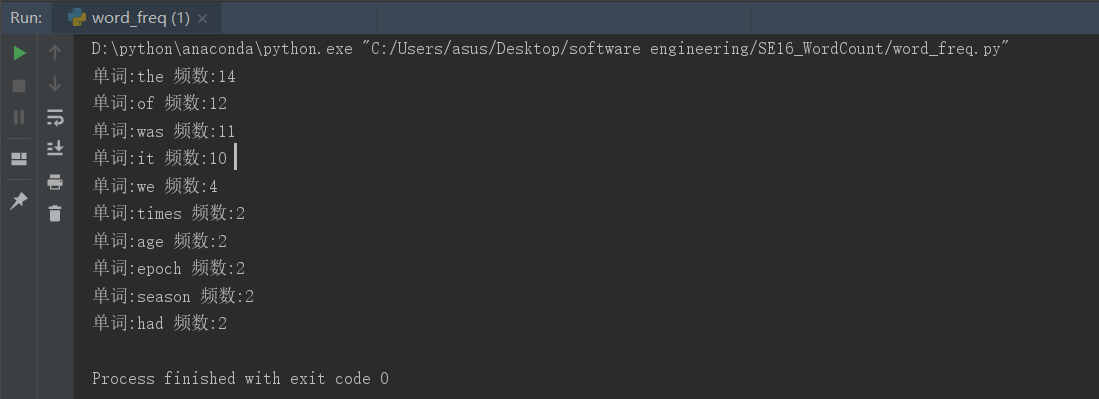
②《A_Tale_of_Two_Cities》
五、性能分析结果及改进
(1)寻找执行时间、次数最多的部分代码【参考博客 https://blog.csdn.net/asukasmallriver/article/details/74356771 】
①性能分析的代码:为了方便调用,把原本主函数的词频运行代码封装在main()函数中,性能分析代码放在主函数中。
def main(): # main函数封装词频运行 dst = "C:/Users/asus/Desktop/software_engineering/SE16_WordCount/src/Gone_with_the_wind.txt" #《Gone_with_the_wind》的路径 bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq) if __name__ == "__main__": import cProfile import pstats cProfile.run("main()", filename="word_freq.out") # 创建Stats对象 p = pstats.Stats('word_freq.out') # 输出调用此处排前十的函数 # sort_stats(): 排序 # print_stats(): 打印分析结果,指定打印前几行 p.sort_stats('calls').print_stats(10) # 输出按照运行时间排名前十的函数 # strip_dirs(): 去掉无关的路径信息 p.strip_dirs().sort_stats("cumulative", "name").print_stats(10) # 根据上面的运行结果发现函数process_buffer()最耗时间 # 查看process_buffer()函数中调用了哪些函数 p.print_callees("process_buffer")
②执行时间最长的代码
# 将文本内容都改为小写且去除文本中的中英文标点符号 for ch in '“‘!;,.?”': bvffer = bvffer.lower().replace(ch, " ")
附:ncalls:表示函数调用的次数; tottime:表示指定函数的总的运行时间,除掉函数中调用子函数的运行时间;
percall:(第一个percall)等于 tottime/ncalls; cumtime:表示该函数及其所有子函数的调用运行的时间;
percall:(第二个percall)即函数运行一次的平均时间,等于 cumtime/ncalls;
filename:lineno(function):每个函数调用的具体信息;
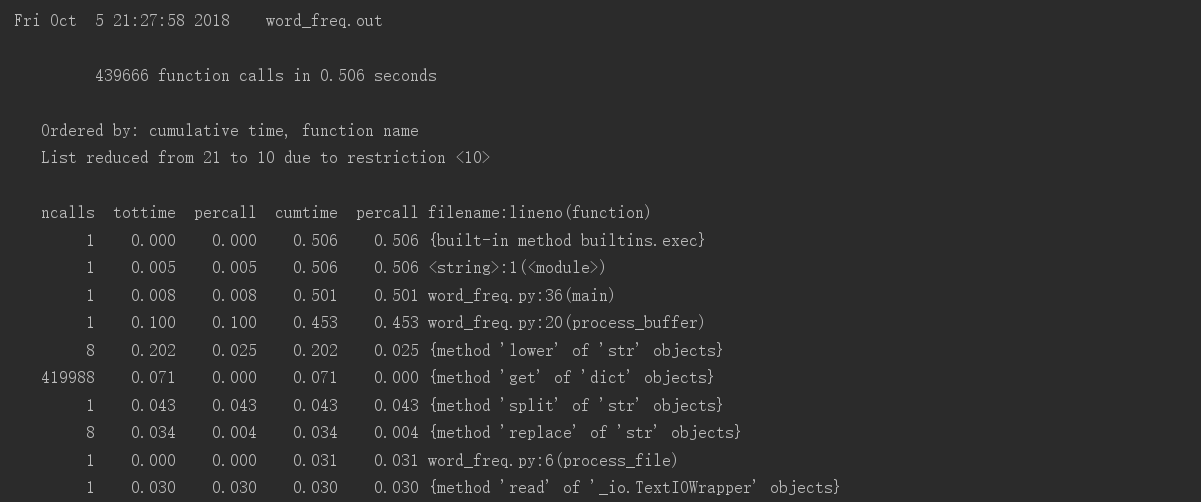
③执行次数最多的代码
for word in words: word_freq[word] = word_freq.get(word, 0) + 1

(2)使用可视化工具分析【参考博客 https://blog.csdn.net/asukasmallriver/article/details/74356771 】
①工具:graphviz、Gprof2Dot
②对main()函数执行产生的word_freq.out进行可视化

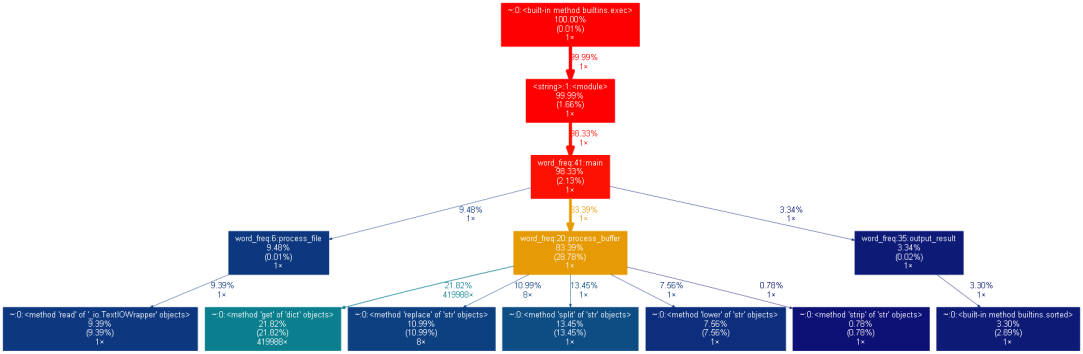
③根据执行时间性能分析或根据执行次数性能分析可视化


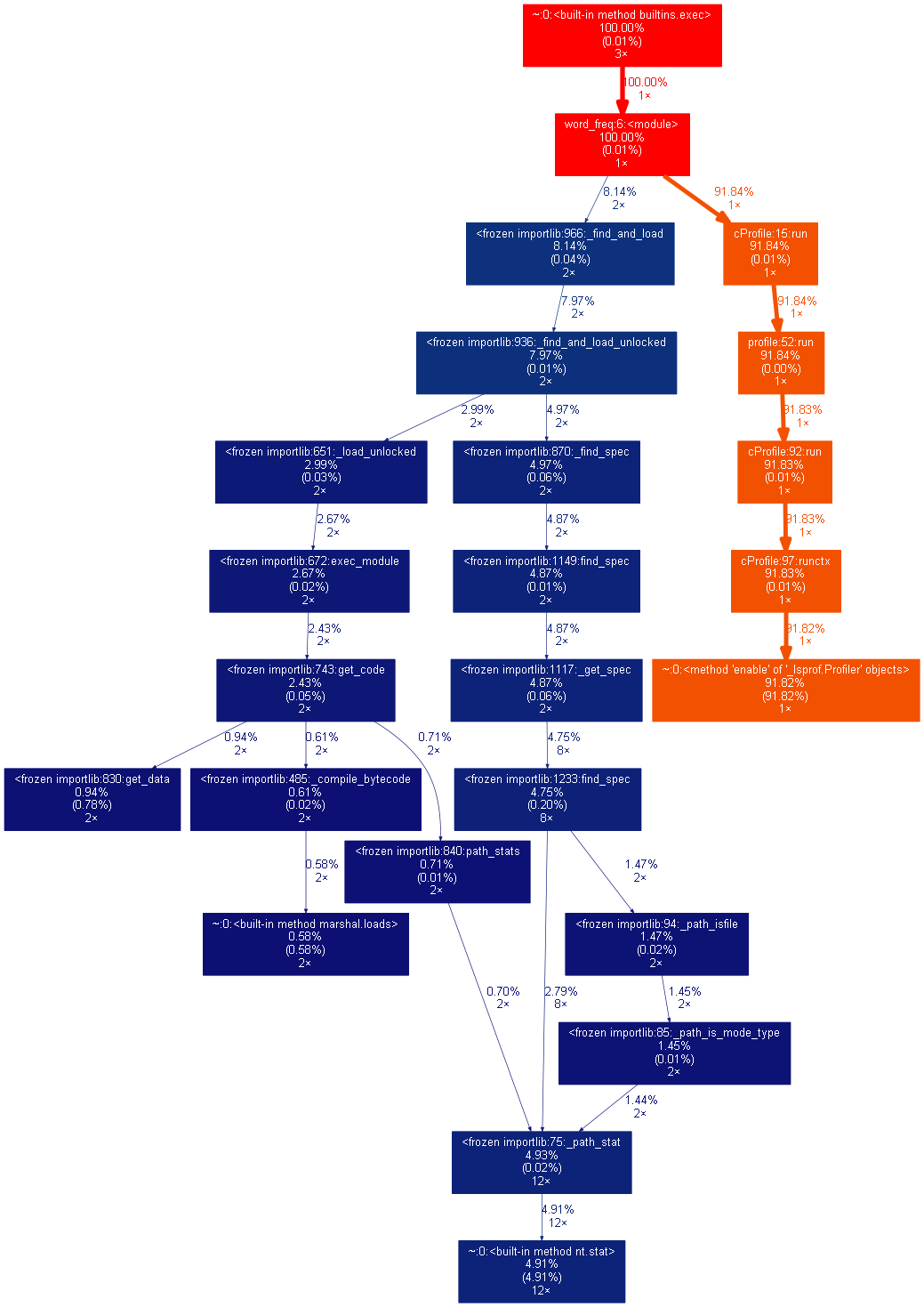
(3)尝试改进程序代码
①分析:减少运行时间可以从两个方面减少:1)减少调用次数 ,2)减少每次调用的耗时,所以减少最多次调用的代码的耗时是实现改进最有效的方式;但是调用次数最多的代码是遍历字典对同一个词求出现次数,这个涉及到遍历算法的优化,不好修改;所以减少耗时最长的代码的运行时间
②实现:把bvffer.lower()放到for循环外
原来的代码:
# 将文本内容都改为小写且去除文本中的中英文标点符号 for ch in '“‘!;,.?”': bvffer = bvffer.lower().replace(ch, " ")
修改后代码:
# 将文本内容都改为小写 bvffer = bvffer.lower() #去除文本中的中英文标点符号 for ch in '“‘!;,.?”': bvffer = bvffer.replace(ch, " ")
③结果对比
原来的运行结果:
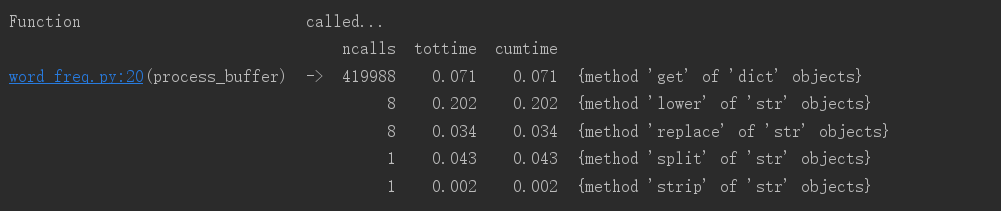
修改后运行结果:
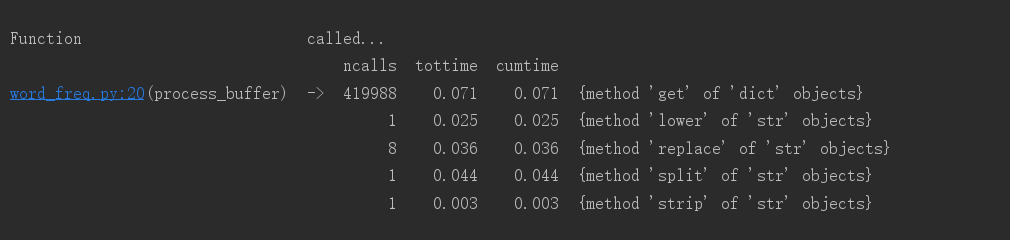
结论:修改后比修改前快了0.177s

 浙公网安备 33010602011771号
浙公网安备 33010602011771号