网页学习(三) css各种选择器
根据https://developer.mozilla.org/zh-CN/docs/Learn/CSS/Building_blocks/Selectors学习
选择器:它是元素和其他部分组合起来告诉浏览器哪个HTML元素应当是被选为应用规则中的CSS属性值的方式 选择器列表: 其实是组合定义的方式 h1, .special { color: blue; } 当你使用选择器列表时,如果任何一个选择器无效 (存在语法错误),那么整条规则都会被忽略。 1.类型、类和ID选择器 h1 { }
类选择器以一个句点(.)开头,会选择文档中应用了这个类的所有物件。点前面加类型,可以特化这个类只用于这个类型。还能多个点,代表多对一。 .box { }
ID选择器开头为#而非句点,不过基本上和类选择器是同种用法。可是在一篇文档中,一个ID只会用到一次。它能选中设定了id的元素,你能把ID放在类型选择器之前,只指向元素和ID都匹配的类 #unique { } 2.标签属性选择器 这组选择器根据一个元素上的某个标签的属性的存在以选择元素的不同方式: a[title] { } 或者根据一个有特定值的标签属性是否存在来选择: a[href="https://example.com"] { } 3.伪类与伪元素 这组选择器包含了伪类,用来样式化一个元素的特定状态。例如:hover伪类会在鼠标指针悬浮到一个元素上的时候选择这个元素: a:hover { } 它还可以包含了伪元素,选择一个元素的某个部分而不是元素自己。例如,::first-line是会选择一个元素(下面的情况中是<p>)中的第一行,类似<span>包在了第一个被格式化的行外面,然后选择这个<span>。 p::first-line { } 4.运算符 最后一组选择器可以将其他选择器组合起来,更复杂的选择元素。下面的示例用运算符(>)选择了<article>元素的初代子元素。 article > p { } 5.全局选择器 全局选择器,是由一个星号(*)代指的,它选中了文档中的所有内容
存否和值选择器
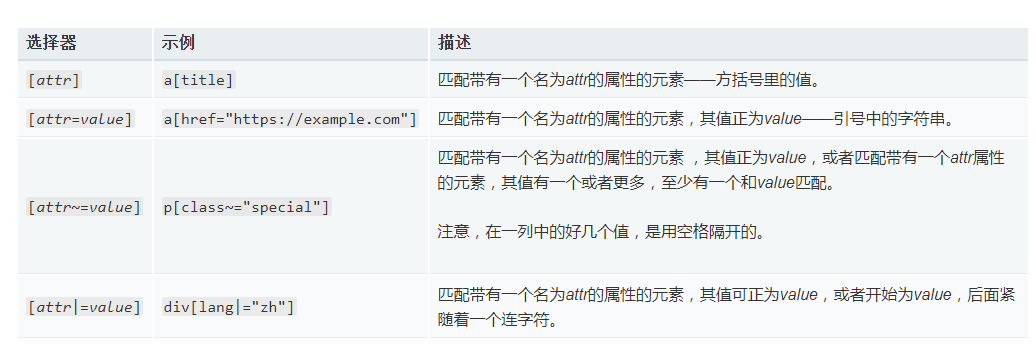
子字符串匹配选择器

i可以让选择器不敏感
li[class^="a"] {
background-color: yellow;
}
li[class^="a" i] {
color: red;
}

