游戏架构设计:高性能并行编程
这次的主题主要是利用线程级并行减少 CPU-bound,从多线程的角度出发
CPU-bound 与 memory-bound
float 类型的计算类耗时:
- 1次float乘法 ≈ 1次float减法 ≈ 1次float加法≈ 4次float加法(SIMD优化成功)≈ 32次float加法(CPU有8核心且SIMD优化成功)
- 1次float除法 ≥ 2次float加法
float 类型的内存访问耗时:
- 1次float读写 ≈ 8次float加法
我们知道,得益于CPU的流水线,CPU可以一边计算一边访问下一次即将要用到的内存。那么就区分清楚 瓶颈到底是计算量还是内存读写,因为这意味着CPU的时间到底是哪个部分在等待另一个部分的完成
- 计算瓶颈(CPU-bound):当计算量(如float的加减乘除)耗时大于内存读写的耗时,那么就称遇到了CPU-bound
- 内存瓶颈(memory-bound):当内存读写的耗时大于计算量(如float的加减乘除)耗时,那么就称遇到了memory-bound
切记,并行只能加速计算的部分,不能加速内存读写的部分,因此并行能减轻 CPU-bound,但不减轻 memory-bound
// cpu-bound
// 利用并行计算会有较好的加速效果,因为瓶颈在于计算量
for(int i = 0; i<1024; i++){
a[i] = std::sin(i);
}
// memory-bound
// 利用并行计算的加速效果并不明显,因为瓶颈在于内存访问
for(int i = 0; i<1024; i++){
a[i] = 1;
}
对于 a[i] = func(a[i]),1次读1次写,那么 func 里应当包含 16 次加法,才能和内存的延迟相抵消;如果有 8 个核心,则需要 16*8=128 次加法,才能避免 memory-bound ,否则加速比会达不到 8
为什么有时候使用 SIMD、多线程的并行计算会没什么效果甚至性能更差?很大可能是因为代码遇到 memory-bound 了,而不是 CPU-bound。也就是CPU计算耗时少于内存访问耗时,导致 CPU 大部分时间浪费在等内存延迟,这时候计算得再快也没有用。此外多线程调度也有一定额外开销。
利用 CPU 多核
物理核心、逻辑核心
现代 PC 端 CPU 都是标榜着例如 “4核8线程”,其中的 “8线程” 并不是 OS 概念中的线程,而是逻辑核心。这其中涉及到了 CPU 的一种技术,即 SMT(同时多线程)技术。在这种技术下,就需要分清楚物理核心和逻辑核心的概念,以便后面知道该利用 CPU 的多少核心
物理核心:实打实的物理 CPU,多个物理核心可以真正并行(而非并发)执行任务,因此理想状态的程序中,应该开启与物理核心数量一致的线程,这样理论上就能把 CPU 的所有核心都充分利用上
逻辑核心:在物理核心的前端上增加一小部分资源,对上层伪装成多个核心
为什么要提供多个逻辑核心,而不是从 OS 层面开多几个线程?因为一个线程占用一个物理核心时,实际上该物理核心很大概率仍然有相当资源没有利用到(例如一些寄存器、ALU部件),而多个逻辑核心可以尽量让物理核心的所有资源更进一步利用。
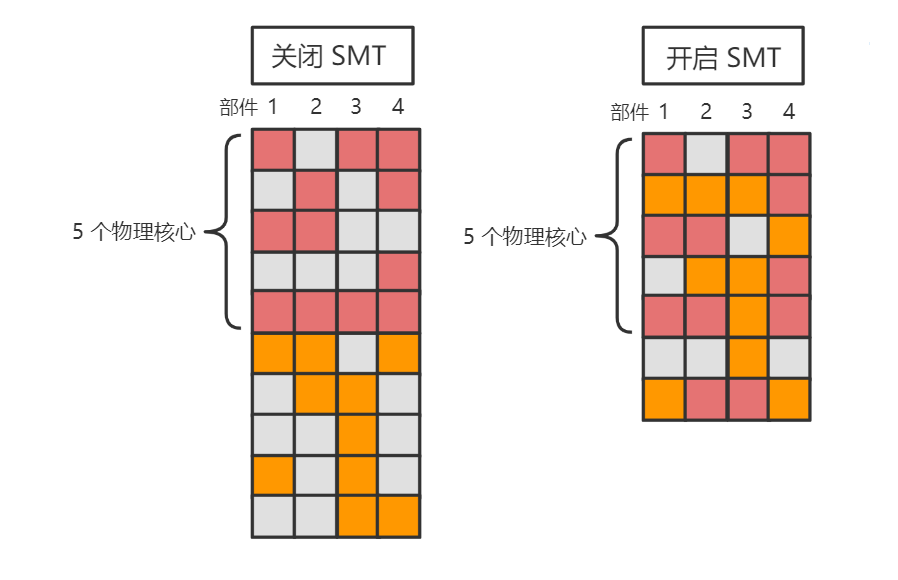
SMT 技术的好处和代价:
-
SMT 技术因为仅仅只是利用物理核心的空闲部件,因此很难像增加物理核心数量那样做到性能成倍的增加,一般是增加 15~30% 的多线程性能
-
SMT 技术也会引入一定额外代价,例如多线程维护开销、资源冲突、线程安全问题、功耗增加等
-
对于优化较好的 SIMD 程序,物理核心的计算资源往往是跑满的,因此不必要使用 SMT 技术(使用了还会性能倒退)
也就是说,
- 如果程序是做了相当好的 SIMD 优化(计算密集型),那么至少需要开启与物理核心数相同的线程才能充分利用多核性能
- 如果程序的计算是比较稀疏的,那么需要开启与逻辑核心数相同的线程并且 CPU 开启 SMT 支持才能充分利用多核性能
- 通常 CPU 有 N 个逻辑核心就开 N-1 或更少个线程,因为需要为操作系统或其他专有程序保留一些核心;而开启过多的线程会导致频繁的上下文切换,导致性能下降
TBB 并行编程库
尽管我们知道要充分利用 CPU 多核就得开够足够的线程来做计算,但是面向线程的代码是非常不直观的,因此我们往往需要封装好底层的线程,调用面向任务(Task)或者作业(Job)的接口可以更加清晰地使用并行编程。当然我们也可以选择使用现有的并行编程库来进行并行编程,而不需要自己造一波诸如线程池等轮子。
其中最常见的便是 TBB 并行编程库 ,它是 Intel 用标准 C++ 写的一个开源的并行计算库,主要功能:
- 并行算法
- 任务调度
- 并形容其
- 同步原语
- 内存分配器

实际上,更多人知道的是 OpenMP 而非 TBB 库,因为 OpenMP 的使用比较方便嵌入,而且集成到编译器中,只需要编译器打开
-fopenmp选项便可使用。但是相比于 OpenMP,TBB 库支持更多方便于并行编程的 API,例如提供了并行容器;又可以为并行程序培养出更好的并行编程风格和更高的抽象层,从而更容易维护并行编程代码。
任务调度
正如前面说到,我们可以只关心并行任务,而不关心线程的管理。
TBB 就提供了一个用于任务调度的 API,即 任务组 tbb::task_group:
- 通过
run(const Function & f)添加并执行一个并行任务 - 通过
wait()来等待该任务组的所有并行任务的完成
tbb::task_group tg;
// 一边下载东西,一边播放音乐,一边也接受交互
tg.run([&](){download("hello.zip");});
tg.run([&](){playSound("waiting.mp3");});
tg.run([&](){interact();});
// 阻塞等待至该任务组的所有任务都完成
tg.wait();
也可以绕过任务组 API ,直接简单的异步执行一个或多个任务 tbb::parallel_invoke(const Function & f,...):
tbb::parallel_invoke(
[&](){download("hello.zip");},
[&](){playSound("waiting.mp3");},
[&](){interact();},
);
C++11 也有类似的API
std::asycn(cosnt Func& f),含义为异步执行一个任务,不过它没有任务分组的概念。更多关于 C++11 多线程语法的可以看看我 以前总结的笔记
并行循环
在大部分的循环代码中,其实是可以用多线程来进行并行循环的(例如理想情况下,可以让4个线程分别进行1/4的循环次数,从而让循环加速4倍)
for (i = 0; i < 1024; i++) a[i] = std::sin(i);
// 期望利用利用多线程变成类似如下行为:
// 线程1:for (i = 0; i < 256; i++) a[i] = std::sin(i);
// 线程2:for (i = 256; i < 512; i++) a[i] = std::sin(i);
// 线程3:for (i = 512; i < 768; i++) a[i] = std::sin(i);
// 线程4:for (i = 768; i < 1024; i++) a[i] = std::sin(i);
OpenMP 并行循环 :
我们可以直接打开编译器的 -fopenmp 选项,并且在循环语句前加上#pragma omp parallel for 来方便地进行并行循环
#pragma omp parallel for num_threads(N):指定使用 N 个线程来进行并行循环
#pragma omp parallel for
for (i = 0; i < 1024; i++)
{
a[i] = std::sin(i);
}
TBB 并行循环:
-
void parallel_for(Index first, Index last, const Function & f) -
void parallel_for_each(Iterator first, Iterator last, const Body& body) -
void parallel_for(const Range& range, const Body & body)
// 面向初学者的最简单的 parallel for
tbb::parallel_for((size_t)0, (size_t)n, [&](size_t i){
a[i] = std::sin(i);
});
// 基于迭代器区间的 parallel for
std::vector<float> a(1024);
tbb::parallel_for_each(a.begin(), a.end(), [&](float& f){
f = 233.f;
});
// 一维区间的 parallel for
tbb::parallel_for(tbb::blocked_range<size_t>(0,n),
[&](tbb::blocked_range<size_t> r){
for(size_t i = r.begin(); u < r.end(); i++){
a[i] = std::sin(i);
}
});
// 二维区间的 parallel for
tbb::parallel_for(tbb::blocked_range2d<size_t>(0, n, 0, n),
[&](tbb::blocked_range2d<size_t> r){
for(size_t i = r.cols().begin(); i < r.cols().end(); i++)
for(size_t j = r.rows().begin(); j < r.rows().end(); j++)
{
a[i*n+j] = std::sin(i) * std::sin(j);
}
});
// 三维区间的 parallel for
tbb::parallel_for(tbb::blocked_range3d<size_t>(0, n, 0, n, 0, n),
[&](tbb::blocked_range3d<size_t> r){
for(size_t i = r.pages().begin(); i < r.pages().end(); i++)
for(size_t j = r.cols().begin(); j < r.cols().end(); j++)
for(size_t k = r.rows().begin(); k < r.rows().end(); k++)
{
a[(i*n+j)*n+k] = std::sin(i) * std::sin(j) * std::sin(k);
}
});
但是不是所有的循环都是可以直接进行并行化,在遇到数据依赖的情况下,我们还需要做一些额外处理来避免访问冲突
常见基本并行算法
Map(映射)
将每个元素通过计算映射成某个值
- 串行映射:时间复杂度 ,工作复杂度
- 并行映射:时间复杂度 ,工作复杂度
注: 为线程数
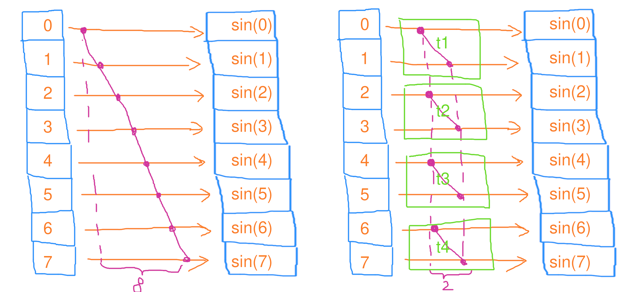
void mapping(std::vector<float>& a)
{
for(size_t i = 0; i < n; i++)
a[i] = std::sin(i);
}
void mapping(std::vector<float>& a)
{
tbb::task_group tg;
for (size_t t = 0; t < c; t++)
{
size_t begin = t * n / c;
size_t end = std::min(n, (t+1) * n / c);
tg.run([&, begin, end](){
for(size_t i = begin; i < end; i++)
a[i] = std::sin(i);
});
}
tg.wait();
}
Reduce(缩并)
对每个元素的映射结果以某种算法结合起来(例如,求总和)
- 串行缩并:时间复杂度 ,工作复杂度
- 并行缩并:时间复杂度 ,工作复杂度
- 将所有元素均分成 份,分别让 个线程去做缩并;等所有线程完成后,再把串行地这 个结果缩并起来
其实,TBB 已经提供了封装好的 API:
Value parallel_reduce(const Range& range, const Value& identity, const RealBody& real_body, const Reduction& reduction)
- GPU 并行缩并:时间复杂度 ,工作复杂度
由于 GPU 的线程数往往成千上万,因此 GPU 的算法可以视为拥有无限多个线程的并行算法;此外,GPU 并行缩并算法并不适合 CPU 多核,因为 CPU 核心数有限,过多的线程反而会导致频繁的上下文切换开销,造成性能下降
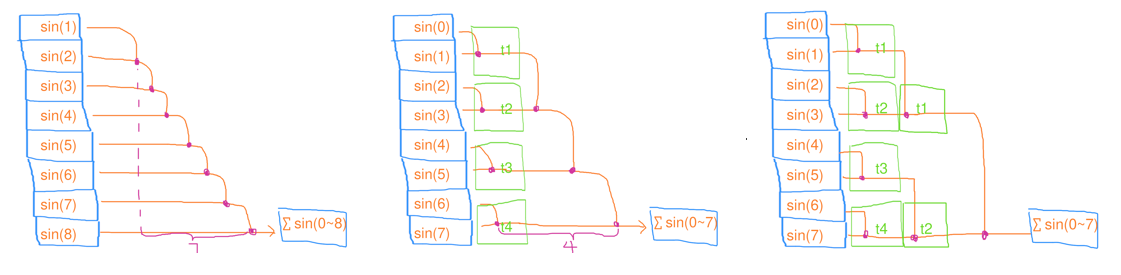
// 串行缩并
float reduce()
{
float res = 0;
for(size_t i = 0; i < n; i++)
res += std::sin(i);
return res;
}
// 并行缩并
float reduce()
{
float res = 0;
tbb::task_group tg;
std::vector<float> tmp_res(c);
for(size t = 0; t < c; t++)
{
size_t begin = t * n / c;
size_t end = std::min(n, (t+1) * n / c);
tg.run([&, t, begin, end](){
float local_res = 0;
for(size_t i = begin; i < end; i++)
local_res += std::sin(i);
tmp_res[t] = local_res;
});
}
tg.wait();
for(size_t t = 0; t < c; t++)
{
res += tmp_res[t];
}
return res;
}
Scan(扫描)
在缩并的基础上,还把中间结果也存到数组里(例如,前缀和数组)
- 串行扫描:时间复杂度 ,工作复杂度
- 并行扫描:时间复杂度 ,工作复杂度
- PART1:将所有元素均分成 份,分别让 个线程去做扫描
- PART2:等所有线程完成后,再把串行地这 个结果去做扫描
- PART3:将 的元素均分成 份,分别让 个线程去做扫描
其实,TBB 已经提供了封装好的 API:
Value parallel_scan(const Range& range, const Value& identity, const Scan& scan, const ReverseJoin &reverse_join)
- GPU 并行扫描:时间复杂度 ,工作复杂度
在一些算法中,改成并行算法可能带来时间复杂度的降低,但是也可能会导致工作复杂度的提升(工作额外干的事情变多了,耗电量也变得更多)
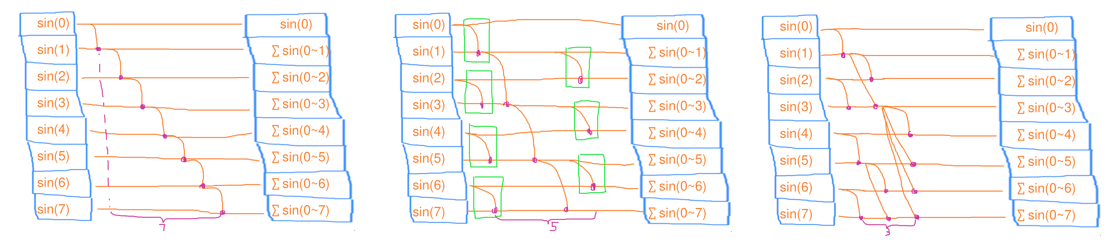
// 串行扫描
void scan(std::vector<float>& a)
{
float res = 0;
for(size_t i = 0; i < n; i++)
{
res += std::sin(i);
a[i] = res;
}
}
// 并行扫描
void scan(std::vector<float>& a)
{
float res = 0;
// PART 1
tbb::task_group tg1;
std::vector<float> tmp_res(c);
for (size_t t = 0; t < c; t++)
{
size_t begin = t * n / c;
size_t end = std::min(n, (t+1) * n / c);
tg1.run([&, t, begin, end](){
float local_res = 0;
for(size_t i = begin; i < end; i++)
local_res += std::sin(i);
tmp_res[t] = local_res;
})
}
tg1.wait();
// PART 2
for (size_t t = 0; t< c; t++)
{
tmp_res[t] += res;
res = tmp_res[t];
}
// PART 3
tbb::task_group tg2;
for (size_t t= 1; t < c; t++)
{
size_t begin = t * n / c - 1;
size_t end = std::min(n, (t+1) * n / c) - 1;
tg2.run([&, t, begin, end](){
float local_res = tmp_res[t];
for(size_t i = begin; i < end; i++)
{
local_res += std::sin(i);
a[i] = local_res;
}
})
}
tg2.wait();
}
Filter(筛选)
将集合中的一部分元素筛选出来形成新的集合
- 串行筛选:依次将筛选结果推入到集合中
- 并行筛选(使用中间结果集合):先将筛选结果推入到 线程局部(thread-local)的中间结果集合,最后再将中间结果集合的数据推入到最终结果集合里
- GPU 并行筛选:算出每个元素需要往 vector 推送的数据数量(本例只能是0或1);再对算出的结果进行并行扫描,得出每个 i 要写入的索引;最后对每个元素进行并行循环,根据索引来写入数据
如果每个线程直接将筛选结果推入到集合中时还需要进行互斥操作(例如上锁、解锁),会导致大量时间浪费在等待互斥上
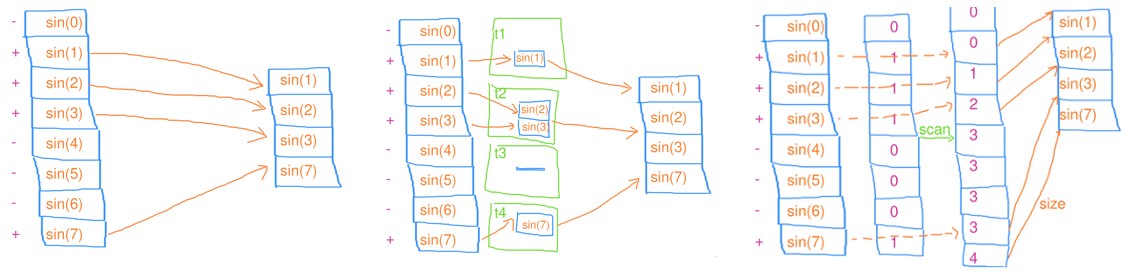
// 串行筛选
void filter(std::vector<float>& a)
{
for(size_t i = 0; i < n; i++)
{
float val = std::sin(i);
if(val > 0) a.push_back(val);
}
}
// 并行筛选
void filter(std::vector<float>& a)
{
tbb::parallel_for(
tbb::blocked_range<size_t>(0, n),
[&](tbb::blocked_range<size_t> r)
{
std::vector<float> local_a;
local_a.reserve(r.size());
for(size_t i = r.begin(); i < r.end(); i++)
{
float val = std::sin(i);
if(val > 0) local_a.push_back(val);
}
std::lock_guard lck(mtx);
std::copy(local_a.begin(), local_a.end(), std::back_inserter(a));
}
);
}
并行分治
很多分治算法是可以通过并行计算去加速的,举一个并行快排的例子
并行快速排序
其实,TBB 已经提供了封装好的 API:
void parallel_sort(Iterator first, Iterator last)
- 为了避免细分的并行任务过多,需要在数据足够小时,改用串行排序
- 选取枢纽元时不选择第一个元素,而是随机选择一个元素,避免基本有序情况
- 采用并行分治
void quick_sort(int* data, size_t size)
{
if(size <= 0)
return;
// 数据足够小时,改用串行排序
if(size < (1<<16))
{
std::sort(data+left, data+right);
return;
}
// 随机选取一个枢纽元,避免基本有序情况
size_t mid = std::hash<size_t>{}(size);
mid ^= std::hash(void*){}(static_cast<void*>(data));
mid %= size;
std::swap(data[0], data[mid]);
int pivot = data[0];
// 划分
size_t left = 0
while (left < right)
{
while (left < right && !(data[right] < pivot))
right--;
if (left < right)
data[left++] = data[right];
while (left < right && data[left] < pivot)
left++;
if (left < right)
data[right--] = data[left];
}
data[left] = pivot;
// 并行分治
tbb::parallel_invoke(
[&](){quick_sort(data, left);},
[&](){quick_sort(data + left + 1, size - left - 1);}
);
}
并发容器
TBB 提供了如下用于并行编程的并发容器,对标于 C++ STL,它可以保证这些并发容器操作的多线程安全性:
tbb::concurrent_vectortbb::concurrent_unordered_maptbb::concurrent_unordered_settbb::concurrent_maptbb::concurrent_settbb::concurrent_queuetbb::concurrent_priority_queue- ...
tbb::concurrent_vector
举个并发容器的例子
拥有以下特点:
-
内存不连续,但指针和迭代器不失效:
std::vector<int>扩容时需要重新 malloc 一段更大的内存然后把每个元素移动过去,并释放掉旧内存。这就导致了数组种每个元素的地址改变了,从而之前保存的指针和迭代器便失效了(这就意味着某个线程在push_back的时候,其它线程都不可以读取该数组的元素)tbb::concurrent_vector不保证所有元素在内存中时连续的,但是换来的好处是:每次扩容时,新 malloc 出的内存只会存放新增的元素,而不会动旧内存上的元素,从而让之前保存的指针和迭代器不会失效
-
可以被多个线程同时
push_back而不出错;在某个线程在push_back的时候,其它线程都可以读取该数组的元素而不出错 -
建议按迭代器顺序访问,而不建议通过索引随机访问(由于内存不连续,随机访问效率会低些)
应用
线程池
线程池简单来说,就是提前创建若干个 Worker Thread,让它们各自跑一个包含了无限循环的 work 函数
当然这个循环并不是真正意义上的无限循环,而是用一个 running 标记作为循环条件,如果需要停止线程池工作,只需要将该标记置 false 即可
而这个 work 函数做的事情,便是重复循环地从任务队列中取出任务并执行之;如果任务队列没有任务时,则当前线程需要等待直到任务列表被提交了新的任务
void ThreadPool::work()
{
while (_is_running)
{
// 从 Task Queue 中取出一个 task
Task task = takeOneTask();
if(task) task(); // do the task
}
}
工作窃取法(Work Stealing)
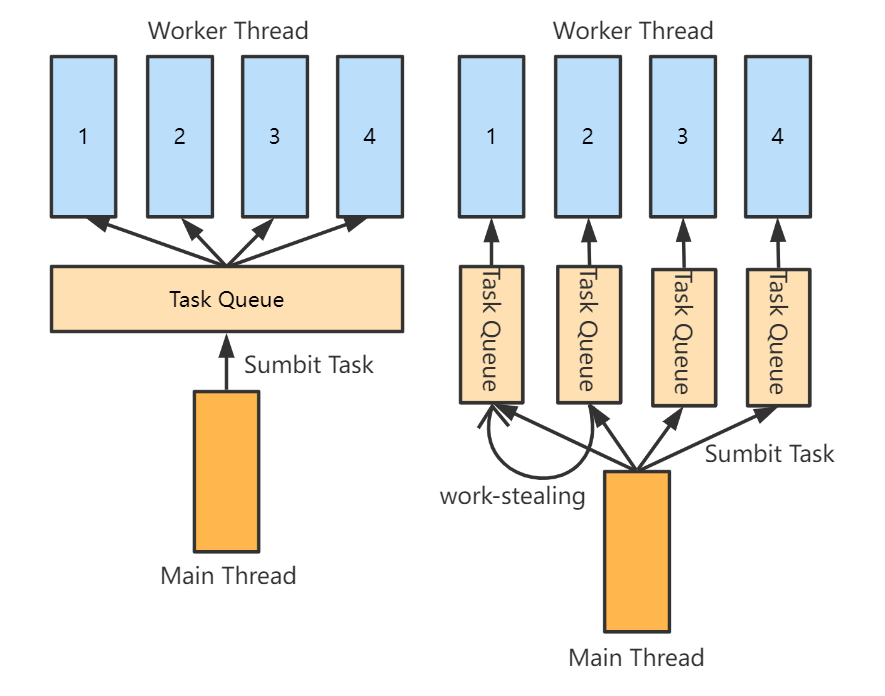
通常的线程池做法:
- Main Thread 向任务队列提交任务
- Worker Thread 从任务队列中取出任务时需要对任务队列进行上锁、解锁;但是一旦线程数多了频繁的上锁解锁会导致很多的空转等待时间
// 从 Task Queue 中取出队首的 task
Task ThreadPool::takeOneTask()
{
Task task = nullptr;
// 出队操作有可能访问冲突,需要对队列上锁
std::unique_lock<std::mutex> lk(_mtx);
// 队列为非空时,取出一个队首 task
if (!_tasks.empty())
{
task = _tasks.front();
_tasks.pop();
}
// 队列为空时,等待 Main Thread 推送新的 task 后通知
else if (_is_running)
{
_cond.wait(lk);
}
return task;
}
work-stealing(工作窃取法)的做法是:
- 为每个 Worker Thread 提供独立的任务队列,而 Main Thread 需要向各个任务队列均衡地提交任务
- 为了避免某些 Worker Thread 提前做完任务队列的任务而陷入等待,需要采用 work-stealing(工作窃取法),即窃取掉别的任务队列里的任务
这样,即使窃取别人的任务队列里的任务也需要一定的上锁解锁开销,但相对于原方案也已经大大减少这种开销
无锁队列
线程池需要经常对任务队列进行上锁、解锁,我们可以设计一种基于 CAS(原子操作)的无锁队列方案,从而减少这些锁的开销
一个想法是:利用循环数组实现无锁队列
-
提交任务的主线程只有一个,也就是 tail 可以使用
unsigned int,而不需要 CAS -
取任务的 Worker Thread 可能有多个,那么 head 应通过原子变量
std::atomic<unsigned int>去表示 -
队列还需要额外引入 len 来表示当前队列的元素有多少个来判断是否可以出队或入队,需要使用原子变量
std::atomic<int>去表示len 存在减为负数的情况,因此使用
std::atomic<int>而非std::atomic<unsigned int> -
队列最大长度 MAX_QUEUE_SIZE 必须满足 2 的幂次方
这是因为原子变量不断使用CAS操作
fetch_add(1)后,有可能最后累计成 0xFFFFFFFF ,此时再 fetch_add 一下就会变成 0x00000000,而 0xFFFFFFFF 只有%(2的幂次方) 才能和 0x00000000 相差一个队列位置。
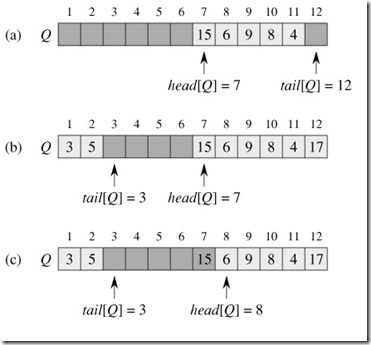
// 出队
Task LockFree_Queue::pop()
{
int len_old = len.fetch_sub(1);
// 非空时,取出一个队首 task
if (len_old > 0)
return arr[head.fetch_add(1) % MAX_QUEUE_SIZE];
// 为空时,恢复原长度
len.fetch_add(1);
return nullptr;
}
那么线程池的 takeOneTask 函数还得改成:
// 从 Task Queue 中取出队首的 task
Task ThreadPool::takeOneTask()
{
auto task = _tasks.pop();
if (task)
{
return task;
}
// 队列为空时,等待 Main Thread 推送新的 task 后通知
if (_is_running)
{
std::unique_lock<std::mutex> lk(_mtx);
_cond.wait(lk);
}
return nullptr;
}
Job System
Job System 和线程池的概念有点相似,用户仅需要关注提交 Job 到 Job Queue 中,然后让各个线程来从 Job Queue 取 Job 来执行。
不过 Joby System 额外的特点是,可以处理具有依赖关系的 Job,即某些 Job 可能需要依赖另一些 Job 的完成。
因此我们可以提交 Job 到 Job System 先,然后在 Job System 层面处理依赖关系后,再由 Job System 将可执行的 Job 提交给线程池执行
依赖性
Job System 首先要考虑的是 Job 之间的依赖关系。
例如下图,Job 4 依赖于 Job1,Job 6 依赖于 Job 1,2,3 ... 这将是一个多对多的结构
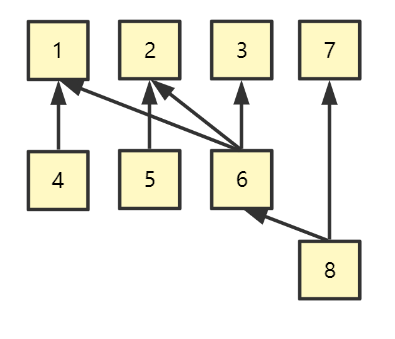
那么一种可能的设计方式,将 Job 定义为以下结构:
struct Job{
int id; // Job ID
std::function<void()> task; // 任务
std::list<int> childrenID; // 所有的 子Job ID
std::atomic<int> dependece; // 依赖的 父Job 数量
};
-
一开始只将 dependece 为 0 (意味着无依赖)的 Jobs 提交线程池执行
-
每次做完一个 Job 后,需要对它所有 children 的 dependece 减去一(由于可能多个线程都同时对同一个 children 减去一,因此需要引入原子操作)
- 如果对某个 child 的 dependece 减去一后变成 0 (意味着依赖的 Job 都执行完了),那么将该 Child Job 提交线程池执行
参考
- [1] Intel | oneAPI Threading Building Blocks
- [2] 高性能并行编程课程 Parallel101 by 小彭老师
- [3] (CS149) 并行计算结构与编程
- [4] Modernizing a DirectX real-time renderer - Multi-threading the VQEngine
- [5] GDC2015 | Destiny's Multithreaded Rendering Architecture
- [6] Unity at GDC - Job System & Entity Component System
- [7] 面向DirectX 12的多线程渲染架构 | 知乎 MaxwellGeng
作者:KillerAery
出处:http://www.cnblogs.com/KillerAery/
本文版权归作者和博客园共有,未经作者同意不可擅自转载,否则保留追究法律责任的权利。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
· spring官宣接入deepseek,真的太香了~