渲染路径:Forward & Deferred Rendering & Decals
前向渲染管线族
Forward Rendering
Forward Rendering(前向渲染):最传统的渲染路径,即每个三角形都会被光栅化成若干个 fragments 后便在 PS(pixel shader) 里进行 fragment 的材质计算和光照计算。
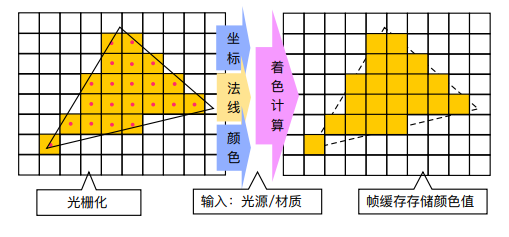
其流程如下:
- base pass:绘制场景中所有的物体(opaque+masked+translucent),fragment shading 里包含材质及光照计算。
优缺点:
-
[ √ ] forward shading 可以很方便支持硬件 MSAA。
-
[ x ] 场景复杂度与光源数量耦合:三角形光栅化后的每个 fragment 要经过与光源数量相等次数的着色计算,也就是说假设有 n 个三角形,m 个光源,则渲染复杂度为 ;在大量光源的情况下,这种耗费是巨大的。
-
[ × ] 不会产生 G-buffer,而很多后处理算法都需要利用 G-buffer 信息。
-
[ × ] 导致大量的 overdraw :由于很多 fragments 无法事先知道自己是否会被最终留在屏幕上,fragments 仍可能在着色后被其它 fragments 所覆盖(即便有 early-z 优化),从而浪费了性能。
理想情形下,我们会给所有物体按近到远排好序,并按该顺序绘制物体,并利用 early-z 优化就可以避免大量的 overdraw。
而在移动端平台时,还要考虑以下点:
- [ √ ] 不必担心 overdraw 的开销:这是因为现在的移动端硬件基本都有内置某种绘制顺序无关的避免 overdraw 算法,例如 HSR(Apple)、LRZ(高通)、Forward Pixel Killing(Mail)。
Forward+ Rendering
所谓 forward+ rendering,其实就是将 z-prepass 和 light culling 加到 forward rendering 的流程中,来优化传统 forward rendering 的一些缺点。
其流程如下:
-
Z-prepass:绘制场景中所有 opaque 物体及 masked 物体,仅将其深度绘制在 depth buffer 上。
-
light culling CS passes:通过一些 CS pass 来构建 tile-based light culling 结构,以便在后续着色时剔除无关光源。
-
base pass:绘制场景中所有的物体(opaque+masked+translucent) ,PS 里的光照计算就可以根据该 fragment 所在 tile 的光源列表来累加计算着色。
相比于传统的 forward rendering 流程,其主要是改进了下面两点。
- [ √ ] 解决多光源开销大:通过 tile-based light culling 可以过滤掉相当多不必要计算的光源。
- [ √ ] 避免 overdraw:由于增加了 Z-prepass,可以过滤掉所有不必要计算着色的 fragment。
而且 light culling CS pass 往往是可以和 shadow pass 并行跑的;并且往往前者计算负载高,后者带宽负载高,就更容易提高 GPU 的利用效率了。
在一些 PC 平台的性能实验中,forward+ 凭借过滤了相当的光源及 fragment 计算量和低带宽开销,forward+ 性能 > deferred rendering 性能(甚至是 > 带宽需求最小的 light pre-pass 方法):
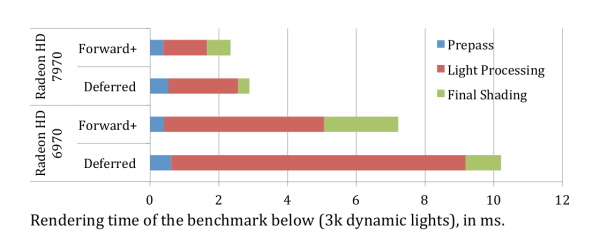
而在移动端平台时,还要考虑以下点:
- [ × ] Z-prepass 在移动端平台是负优化:前面提到现代移动端硬件已经有避免 overdraw 的内置算法,因此多一个 z-prepass 基本只是徒增 draw call。但因为 tile-based light culling 需要依赖于深度图,也就是依赖于 z-prepass,因此 z-prepass 是不可以砍掉的。
Forward+ & Cluster-based Lighting Culling
移动端 Forward+ 的一种改进的方式是,将 tile-based light culling 换成 cluster-based light culling 算法, cluster-based light culling 的优点如下:
- 依赖深度图的 tile-based light culling 换成不依赖深度图的 cluster-based light culling 算法,从而可以砍掉 z-prepass。
- 适合处理更大量的光源数量。
Mini G-Buffer
前面还说到 Forward 类渲染管线缺少 G-Buffer ,因此无法实现部分后处理算法(例如 SSR、SSAO)等。如果想支持这类依赖 G-Buffer 的后处理算法,一种解决方案是:提供一个更轻量级的 mini G-Buffer,让 shading pass 将一些后处理依赖的材质属性写入到 mini G-Buffer 中。
延迟渲染管线族
Deferred Rendering
Deferred Rendering(延迟渲染):相比于 forward rendering,主要想法是将 shading pass 中 fragment 的材质计算和光照计算分离开来,并将光照计算延迟到之后的某个阶段,这样就可以仅对最终留在屏幕上的 fragments 进行光照着色计算而不是对每个三角形的 fragments 都进行光照着色计算。
个人更愿意称最终留在屏幕上的 fragments 为 pixels 。
也就是说, deferred rendering 最终需要光照计算的 fragments 仅与屏幕像素数有关,与场景有多少个三角形无关。
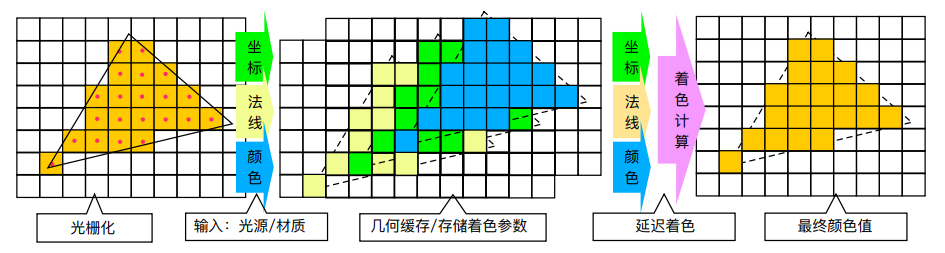
deferred rendering 为了在光栅化结束后不丢失 fragment 的材质属性等信息,需要将这些信息写入到一个名为 G-buffer 的 frame buffer;延迟后的着色计算阶段就能读取出 pixel 对应在 G-buffer 的几何属性信息来作为参数并进行着色计算。
G-buffer 其实就是一个庞大的 frame buffer object(FBO),往往由多张屏幕分辨率的 texture 构成,这样就能通过 pixel 的 uv 坐标访问出多个几何属性。下图是一个 G-buffer 单个元素的布局例子:
G-buffer 部分属性可视化:

不过,此过程需要在 fragment shader 中输出多个颜色值,因此要用到图形处理器接口中的 MRT(Multi Render Targets) 特性。
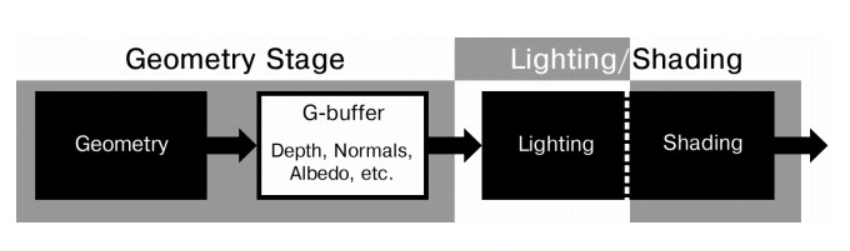
其流程如下:
-
Z-prepass:绘制场景中所有 opaque 物体及 masked 物体,仅将其深度绘制在 depth buffer 上。
-
base pass:绘制场景中所有 opaque 物体及 masked 物体,将每个 fragment 对应的 normal,albedo,specular 等材质属性写入到屏幕分辨率的 G-buffer 中。
-
shading pass:可以用一个 full-screen CS/PS pass 来对屏幕中每个 pixel 进行着色。在对屏幕每个 pixel 着色时,先访问对应的 G-buffer 元素(作为后续 lighting 计算的参数输入),然后进行 lighting 计算(遍历所有光源并计算这些光源对 pixel 的光照贡献)。大体公式如下:
其中, 为光源数量, 和 代表表面的 diffuse 反射率和 specular 反射率;m 为高光扩展系数; 为光源向量, 为表面法线, 为视角方向。
优缺点:
- [ √ ] z-prepass 避免了 overdraw 问题 :z-prepass 执行后,后续的 base pass 和 shading pass 只对屏幕中最终可见的 fragments 进行计算。
- [ √ ] 渲染性能不再与场景的复杂度像耦合(支持数量巨大的光源) :渲染复杂度变为 ,从而保证稳定的帧率,在大量光源的场景优势非常明显。
- [ √ ] G-buffer 可以支持很多后处理算法。
- [ x ] G-buffer 的读写需要占用大量带宽:通常 G-Buffer 中每个 pixel 可以占用多达 128bits 甚至更多的显存占用,对 G-Buffer 读写时会产生大量的带宽开销(尤其是移动端对带宽性能比较敏感)。
- [ x ] 不适合启用硬件 MSAA:首先 MRT MSAA 是非常费的;其次不应该在 base pass 启用 MSAA,因为对材质属性进行 MSAA 混合通常是不正确的;最后,shading pass 所访问的 G-Buffer 属性已经是丢失了 MSAA 覆盖信息的材质属性。
- [ x ] 材质灵活性降低:由于 shading pass 是全屏 pixels 共用一个着色代码,有多少种着色方法(在 UE 里称为 shading model)就得编写多少个 if 语句;当 shading model 种类比较多时,会让 shading pass 性能下降,因此材质系统不宜引入过多的 shading model 种类。
- [ . ] 不支持半透明物体:毕竟 G-Buffer 是存储最表面的几何信息;不过半透明物体可以另外再走一次 forward rendering 流程,问题不大。
而在移动端平台时,还要考虑以下点:
-
[ √ ] 移动端可以相当程度上降低 G-buffer 所占用的读写带宽:现代的移动端设备很多都支持将 G-Buffer MRT 放在 on-chip memory 上让 subpasses 来进行 load/store 操作;而且对于不需要 resolve 出来的 G-Buffer RT 可以采用 memory less 模式,能更进一步降低写回主存的带宽。
-
[ . ] Z-prepass 在移动端平台的改造:应当只绘制 masked object。和 Forward+ 不同,deferred 的 z-prepass 不是必须项,因此我们可以只对需要 alpha test 的 masked 物体进行绘制 z-prepass。
masked object 因为需要在 PS 里采样纹理来决定本 fragment 是否需要 discard(也就相当于可能会在 PS 中修改深度),会破坏 ealry-z、HSR 等硬件优化手段,也就是说可能会造成硬件管线 stall 住了。因此业界管线往往会用 masked object z-prepass 画一遍深度(PS 里带 discard 操作);然后 base pass 再正常绘制 masked object 时的 PS 代码就可以不用包含 discard 操作,从而尽量保持管线状态一致,避免 stall。
总结一下,也就是在移动端推荐以下渲染顺序:masked z-prepass => opaque => masked => translucent/
不过,masked object z-prepass 虽然能避免后续的 PS overdraw 问题,但也会导致更重的 VS 压力(相当于多了一遍的 masked object draw calls);如果项目的性能瓶颈不是 PS 而是 VS,则 Z-prepass 别说只绘制 masked object,而是应当连整个 Z-prepass 都去掉。
-
[ . ] 需硬件支持 MRT:因为 base pass 需要三个及更多的 render target。不过现在的移动端设备基本都支持了。
Deferred Lighting(延迟光照)
Deferred Lighting(又叫 Light Pre-pass),是 deferred rendering 的一种变种流程。它的核心目标是,减少 G-buffer 的 RT 数量,从而使得显存读写带宽大大减轻压力的 deferred rendering 流程。
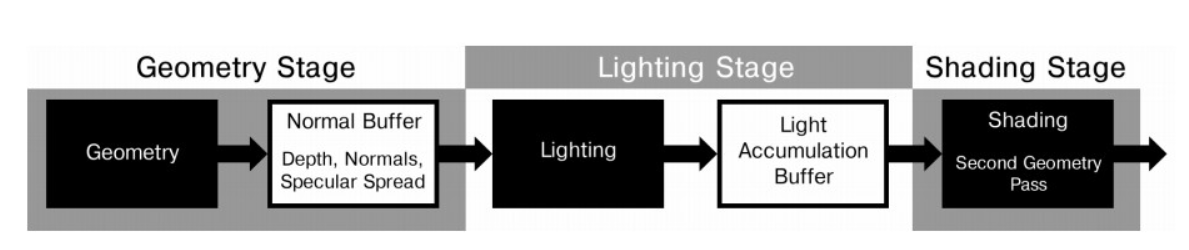
其思路是,第一个阶段绘制所有不透明几何体,并仅写入 G-buffer 的部分属性(称之为 n/m-buffer);第二个阶段则根据已有的部分属性计算出光照着色的中间结果;最后阶段再次绘制所有不透明几何体,恢复出缺失的 G-buffer 属性,从而得到完整的光照参数,并计算出光照着色的最终结果。
注:deferred rendering 是在2004年的 GDC 上被提出的,而 light pre-pass 则是在2008年被提出。
其流程如下:
-
base pass:绘制所有不透明几何体,相比于 deferred rendering,它仅将法线向量 和高光扩展系数(specular spread factor) 写入到 n/m-buffer(类似于 G-Buffer 的缓冲区,但包含的信息更少,更轻量)。
法线向量占据3个通道,高光扩展系数占据1个通道,所以它们可以被合进⼀个4通道的 RT。
-
lighting pass(draw light volume):绘制每个光源体积,并对该体积所覆盖的每个屏幕 pixel 计算 diffuse 和 specular 着色方程(相比于 deferred rendering,这个计算缺少了 和 的参与),并将结果分别写入 diffuse accumulated buffer 和 specular accumulated buffer:
光源体积不是真实存在的场景几何体,而是拟合光源影响范围而产生的 mesh,下图是一些光源范围几何体网格示例:

关于绘制光源体积,更详细的可以看这里 多光源渲染方案 - Light Culling & Light Volume - KillerAery - 博客园 的 light volume 章节。
- shading pass:再次绘制所有不透明几何体,计算出 权重和 权重,但是此时并不需要对表面进行 lighting 计算,而仅需要 lighting pass 产生的两个 accumulated buffer 中读取值并以加权组合起来,就能得到最终的着色结果:
此外一提,也有一些老方法尝试去压缩 accumulated buffer 以更进一步减少带宽:
- CryEngine 3 引擎使用⼀个 R16G16B16A16 的 RT texture 来同时记录 diffuse irradiance 和 specular irradiance;其中前 3 个通道表⽰漫反射值 diffuse,第 4 个通道表示高光的强度 strength,所以高光颜色值可以由 diffuse * strength 计算得出。这种方式仅保留了高光的亮度丢弃了色度(chrominance),但人眼对亮度的感应比色度更为明显,因此这种效果虽然不物理但仍能接受。

YCoCg 压缩帧缓存方法将 RGB 空间换成 YCoCg 空间,然后对 Y 占用 1 个通道,Co、Cg 各占半个通道。这样就能用一个 4 通道的 RT texture 来压缩存储 diffuse color 和 specular color,效果也尚可接受。

与传统的 deferred rendering 相比,light pre-pass 优点缺点如下:
- [ √ ] 减少 G-buffer RT 的数量,降低了显存带宽的开销。
- [ √ ] shading pass 可以启用 MSAA。
- [ × ] 需要绘制两遍所有不透明几何体,即产生两倍的 draw calls,这个开销往往是难以接受的。
总的来说,light pre-pass 其实并不是那么实用,但是其 lighting pass 采用了和传统 deferred rendering 完全不同的光照计算策略(即采用了 draw light volume),这种光照计算策略也被沿用于现代的 deferred rendering 中,详见 多光源渲染方案 - Light Culling & Light Volume - KillerAery - 博客园 。
贴花渲染
贴花是游戏中常见的渲染效果,为了填充文章的字数,就额外加一下 decal 的章节了:)

Decal Mesh
最原始的方法就是,把 decal 当成正常的 translucent mesh 去绘制,即只对 scene color RT 进行 alpha blend。此外注意要关闭深度写入,因为贴花不应该影响原有物体的几何形状。
这种 mesh 例如可以是:
- 只能贴在平面上的 quad mesh。
- 找到与 decal 相交的 triangles 并将这些 triangles 合成一个 decal mesh,但基本这种 decal mesh 只能预计算生成了(生成 index buffer 比较费)。
- 找到与 decal 相交的 meshes 并把这些 meshes 当 decal meshes 并重新绘制,但会增加相当多的 draw call 以及后续 fragment over draw 的浪费(大部分 fragment 采样 decal texture 得到的 alpha 将会是 0)。
这些方法的潜在问题:
- 增加一定数量的 draw call,尤其是后两个方法的 draw call 成本比较高。
- 存在 z-fighting 的 artifact 问题。
因此直接绘制 decal mesh 局限性还是比较大的。
Deferred Decal(延迟贴花)
Deferred Decal 类方法把 decal 的影响范围当成一个 volume,先通过一轮绘制 decal volume mesh 来初步确认有哪些 pixels 是被 decal 影响的,并再第二轮绘制中将 decal 的材质属性混合到 G-Buffer/D-Buffer 中,后续着色时可以通过访问 G-Buffer/D-Buffer 来计算 decal 效果并混入到 scene color 中。
与前面的 decal mesh 方法相比,该方法:
- 主要是让 decal 的效果依托于表面的 opaque pixels 上,而避免成为重叠的 mesh(会导致 z-fighting 问题)。
- deferred decal 的 draw call 数量和相交物体数无关,而仅和 decals 数量相关。
G-Buffer Decals
- base pass:deferred rendering 的正常流程,即绘制 G-Buffer。
- 先绘制一遍 decal volume mesh,将深度测试打开(但不写入深度),模板写入打开,PS 不做任何事情。
- 第二遍绘制 decal volume mesh,将深度测试(但不写入深度)和模板测试(但不写入模板)都打开,然后就可以在 PS 里将 decal 材质属性混合到 G-Buffer 上。
- shading pass:根据 G-Buffer 进行着色,自然而然就带上了 decal 的效果了。
这种方式的优点缺点如下:
-
[ √ ] 算是性能开销比较低的一种 decal 方法:将 decal 材质混合到 G-Buffer 中,不需要额外的 RT。
-
[ × ] 不能支持 forward 管线,因为需要 G-Buffer。
-
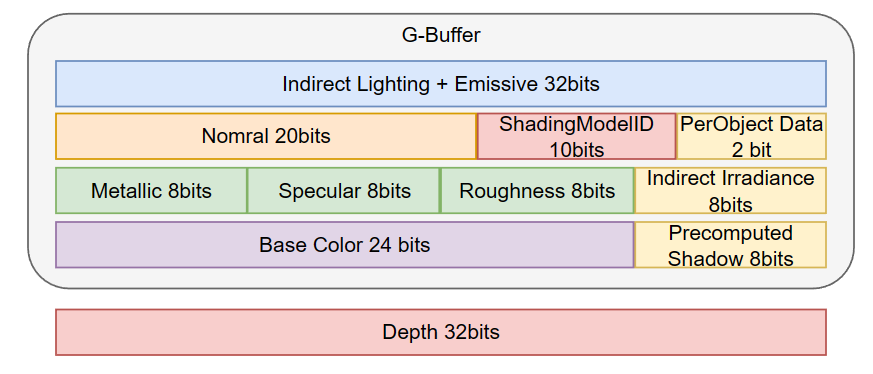
[ × ] G-Buffer 很多时候是不方便于直接混合的:如果强行混合 normal/roughness/base color/..,可能会破坏同一张 texture 中其它的通道属性(例如 Indirect Irradiance/precomputed shadow)或者混合因数会占用 alpha 通道,从而引起烘焙光照的错误。
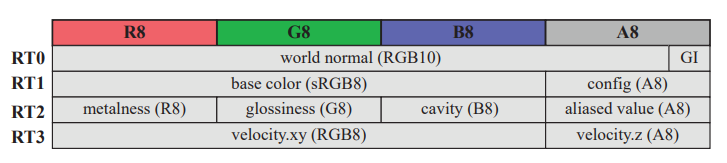
例如下图 UE5 GBuffer 的布局:
D-Buffer Decals
为了避免 G-Buffer 的问题,可以专门另外开一个 D-Buffer 用来存储 decals 材质属性的 buffer(一般 1~2 张 texture),从而与 G-Buffer 隔离开。
- 先绘制一遍 decal volume mesh,将深度测试打开(但不写入深度),模板写入打开,PS 不做任何事情。
- 第二遍绘制 decal volume mesh,将深度测试(但不写入深度)和模板测试(但不写入模板)都打开,然后将 decal 材质属性写到 D-Buffer 上。
- base pass:
- forward 管线:PS 需要采样 D-Buffer 来获得 decal 材质属性并直接算出 decal 效果。
- deferred 管线:PS 需要采样 D-Buffer 来获得 decal 材质属性并混入到 G-Buffer 中。
这种方式的优点缺点如下:
- [ √ ] 无论 deferred 管线还是 forward 管线都可以采用。
- [ √ ] deferred 管线不用担心直接混合 G-Buffer 而导致的错误混合问题。
- [ × ] 引入了额外的 RT(即 D-Buffer),带宽和显存占用都会有一定额外开销。
Decal Projector
Decal Volume 类方法的 draw call 的数量虽然没 Decal Mesh 类方法这么多,但还是有一定程度的增加;而 Decal Projector 类方法旨在不新增任何 draw call,而是在绘制通常的 opaque 物体时,在 pixel shader 里遍历 decals 数组,来计算出可能造成影响的 decals。
Forward Decals
- 在 CPU 计算 mesh 与哪些 decals 相交,并给 uniform buffer 塞入若干个对应的 ClipToDecal 矩阵(ClipToDecal = ClipToWorld × WorldToDecal)和对应的 decal texture index。
- base pass:PS 需要去遍历 uniform buffer 中的每个矩阵来进行投影检测(即让 clip 坐标乘上矩阵后检测一下 decal space uv 是否超出 0~1),投影检测通过的话就可以访问对应的 decal texture 并计算该 decal。
绑定多个 decal textures 往往是用合成后的 atlas 或者 texture array 来实现。
这种方法麻烦的点在于,每个 mesh 可能都有不同的 decals 列表,这会导致:
- [ × ] 破坏合批/instancing:因为需要更新 per object uniform buffer;倘若强行合批/instancing,那么 uniform buffer 可能就得上传超多矩阵,然后 pixel shader 会遍历过多的矩阵导致巨大的性能开销。
- [ × ] 增加一定程度的 CPU 开销:CPU 需要计算 mesh 与哪些 decals 相交。
- [ × ] 一定的 shader 额外性能开销:
- 虽然循环是 uniform loop,但是循环体里面引入了 dynamic branch 来判断是否采 decal texture。
- draw call/mesh 级别的 decals 剔除:大部分 pixels 可能根本没有与任何 decal 相交,但因为其 mesh 相交了就不得不遍历 decals 列表。
Forward Clusterd Decals [2024]
前面提到的 decal volume 其实和 light volume 的思路方法其实是非常相似的。那么 clustered light culling 的思路是不是也可以用到 decals 上?因此就有了 forward clusterd decals。
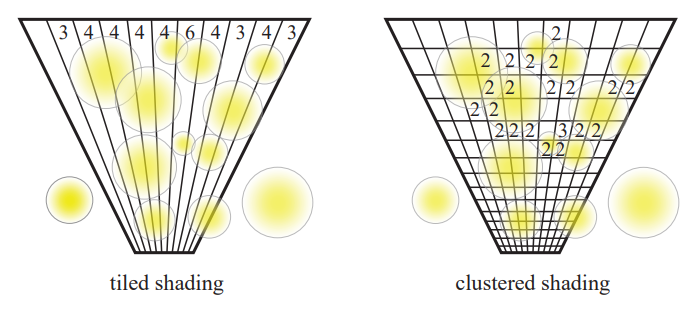
- 先进行一个 decal culling CS pass,来计算每个 cluster 所覆盖的 decals,并记录成 decals 列表。注:这个 pass 是不依赖 depth buffer 的,因此可以很适合放在前面和 shadow pass 并行跑。
- base pass:PS 需要获取 pixel 所在 cluster 对应的 decals 列表,并对列表里每个 decal 进行投影检测,投影检测通过的话就可以计算 decal 了。
这种方式就不会破坏合批/instance,当然它的缺点也有:
- [ × ] 一定的 shader 额外性能开销:
- 循环是 dynamic loop,循环体里面也有 dynamic branch。
- cluster 级别的 decals 剔除:虽然大部分情况下会比 draw call/mesh 级别的剔除要好,但是还是仍有一定的 pixels 浪费了。
因此在一个 decals 比较多的场景中,就可以考虑使用 Forward Clusterd Decals。就好比如海量光源场景才会启用 light culling 方法一样。
此外,还可以扩展成 grid-based light culling,不仅可以在计算 decals 直接光照时用到,还可以在硬件光线追踪计算 decals 时得到性能加速。
Decals 合并 [TODO]
每个 decal 有自己的朝向和位置,我们可以用一个 uint8 来表示朝向和一个 uint8 来表示沿朝向的深度。
然后可以对相同朝向值和深度值的 decals 进行合并,合成一个新的 virtual decal。
参考
- [1] 《Real-time Rendering 4th》
- [2] 《全局光照技术》
- [3] forward框架的逆袭:解析forward渲染 | KlayGE
- [4] 《GPU Pro 7》
- [5] Decal Materials in Unreal Engine | Unreal Engine 5.5 Documentation | Epic Developer Community
- [6] 游戏中的Decal(贴花) - 知乎
- [7]《GPU Zen 3》
作者:KillerAery
出处:http://www.cnblogs.com/KillerAery/
本文版权归作者和博客园共有,未经作者同意不可擅自转载,否则保留追究法律责任的权利。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
2019-03-03 Unity C#笔记 协程