基于 Probe 的实时全局光照(Probe-based Global Illumination)
探针(Probe) 或者说 光照探针(Light Probe),简单理解就是场景中的一个点然后给予这个点去往四面八方收集光照或者说探测光照的能力,并以某种 cache 形式记录下来。在我们对某个 shading point 渲染的时候,就可以利用它附近 probes 所记录的光照信息粗略估计出它所受到的光照。
Cache 形式
cache 的物理存储形式通常有以下:
- Cubemap:往往需要高分辨率的 6 张 texture 拼成 cubemap。
- 存储空间开销极大(取决于分辨率)
- 较好保留高频信息,适合做高质量 specular。


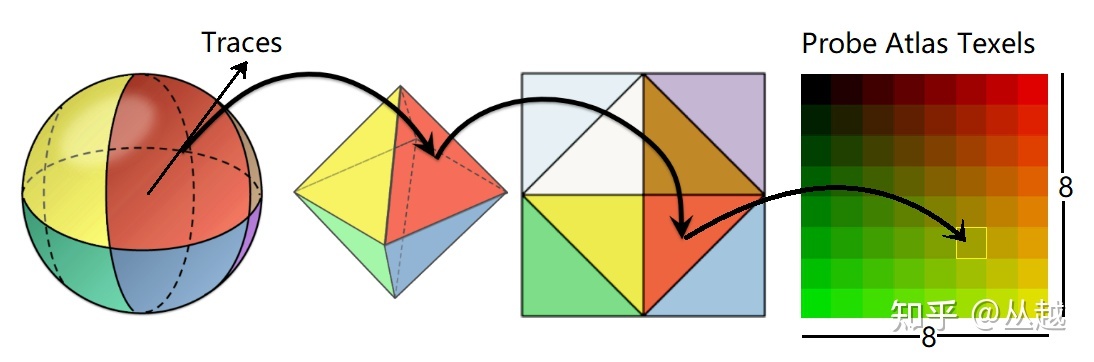
- Octahedral Mapping:使用八面体映射技术。
- 存储空间开稍微大(取决于分辨率)
- 也能保留一定程度的高频信息,适合做 diffuse 和 glossy(低质量 specular)。
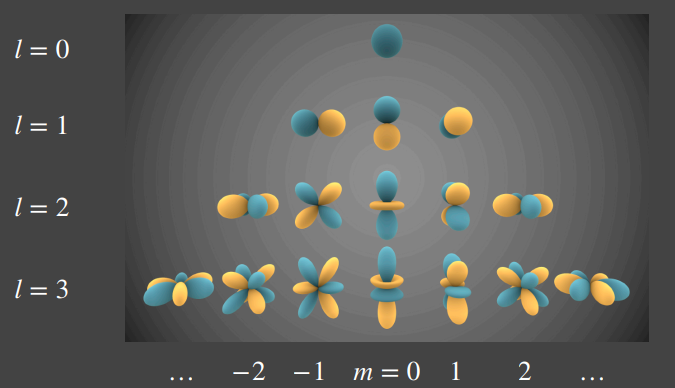
- SH:往往只需要存储十几个或几个 SH 系数。
- 存储空间开销极低(取决于阶数)。
- 由于基本只能表示低频信息,比较适合做 diffuse,不太好做 glossy 和 specular。
而对于 probe-based 方案来说,常见有以下几种 cache 流派:
- Radiance Map:往往使用 cubemap 或者 octahedral mapping 存储各个 texel 立体角方向对应的 radiance 的积分(积分域为这个 texel 对应的立体角面积),信号表示往往比较高频,常用于 specular/glossy GI。
- Irradiance Map:往往使用 SH 或者 octahedral mapping 存储各个 texel 立体角方向对应的 radiance 的 cosine 半球积分。可以理解成立体角方向为法线,然后以 diffuse brdf 搜集到的光照之和,信号表示往往比较低频,常用于 diffuse GI。
所以实际上 radiance map 一个 texel 的值,并不是真正意义上的 radiance,而是 irradiance,只不过该立体角面积比较小(远远小于半球积分),已经可以粗略看成该方向射入的 radiance。
- Radiance Map + Irradiance Map:有些 GI 方案会同时存储两种 map,先通过若干个精确的 ray radiance 来建立 radiance map,再用 mipmap/SH 的方式来给 radiance map 滤波成 irradiance map。这样就能同时提供 specular/glossy/diffuse 三种 GI 效果。当然性能和存储开销更大。
- Material Map:往往使用 cubemap 形式存储各个 texel 立体角方向发出射线所打到的表面点的材质信息。在一些烘焙 GI 方案中,可能有动态光照的需求就无法烘焙 radiance map 或者 irradiance map,最多只能烘焙 material,然后运行时每帧根据 material 实时 shading 从而得到实时的 radiance。
基于烘焙的 Irradiance Probe
PS:其实基于烘焙的 irradiance probe 基本都属于 PRT(Precomputed Radiance Transfer)方案,无非都是来源于原版 PRT 的改进。
在场景里预先放置若干个 probe,为每个 probe 预计算出局部(因为只能处理静态物体和静态光照,无法囊括动态物体和动态光照,所以是局部的)光场信息并存储后,在运行时就可以通过物体周围 probes 的光照信息来插值来得到 shading point 此时受到的局部光照。

基于预计算的 Probe 方案往往意味着需要进行预放置,主流有三类放置方式:Tetrahedral Tessellations,ILC,VLM。并且在收集光照信息的时候,也采取预计算(烘焙)的方式。这意味着只能对静态光照(静态光源、静态物体组建成的静态场景)进行收集。
在离线阶段,每个 probe 会通过比较高质量但耗时的渲染方式(一般可以使用 path tracing 等方式)来收集静态光照,说白话也就是在 probe 上往四面八方去探测光照。同时,探测到的静态光照信息信息将以 SH 的方式(而不是 irradiance map)的形式记录到该 probe 中。
由于场景中有很多个 probe,要是每个 probe 都存储一张 irradiance map 的存储和带宽开销会非常大,因此往往采用 SH lighting 方式(每个 probe 仅需要存储十几个或者几个 SH 系数)会更加可行。
有了预先放置好的 probes ,又有它们各自预先烘焙的光照信息(SH 系数),那么我们就可以在运行时对 shading point 着色:
- 根据 shading point 的世界坐标找到其邻近的 probes
- 对这些 probes 的 SH 系数以距离为权重进行混合,得到 shading point 的 SH 系数(比较粗糙的光照信息)
- 根据 SH 系数就可以重建 shading point 的光照信息
四面体镶嵌(Tetrahedral Tessellations)
在场景中预先放置自定义位置的 probe ,这些 probe 将自动相连成一个个四面体。而为了增加这种 GI 方案的真实感和避免过多的 probe 带来的存储开销,一般应当把 probe 在光照发生明显变化的地方(如明暗交接处)放密集些,而在光照不怎么变化的地方可以稀疏地放置。
ps:将这些 probe 进行三角化(将空间切分成四面体)需要用到 Delaunay Triangulation 完美三角剖分算法。
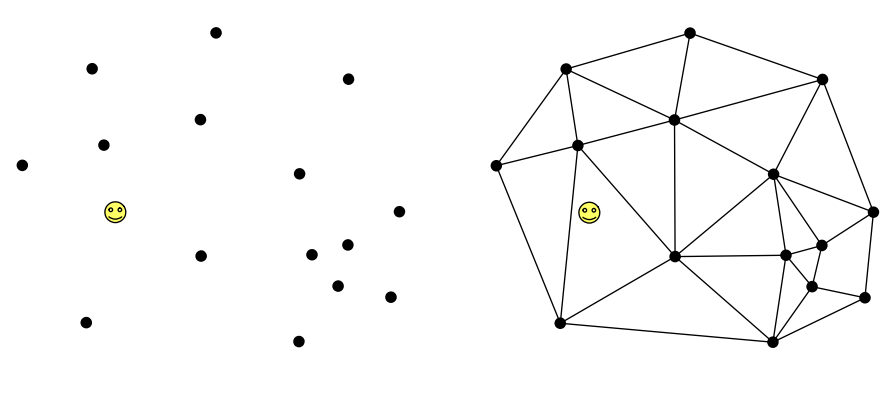
- 手动放置的方式比较费人力
- 运行时,查找 shading point 所处四面体的运算量较高:四面体的分布并不是均匀的,最糟糕没有优化的情况下需要暴力遍历每一个四面体判断 shading point 是否在该四面体里面,无论对 CPU 还是 GPU 运算都不太理想
基于 probe 的方案是需要经常用到这种查询操作:给定一个世界坐标,查询出它周围邻近的 probes

Indirect Light Cache
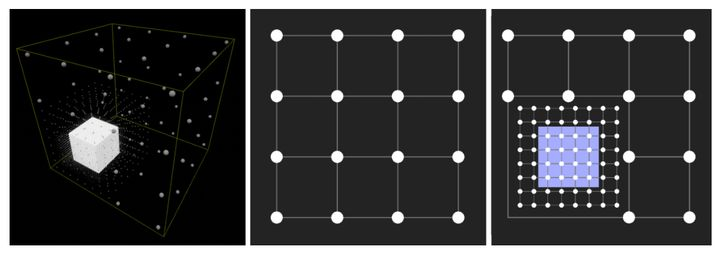
Indirect Light Cache, 即 ILC(间接光缓存),是 UE4 的方案,它基本上是在静态物体表面法线向上自动地均匀放置 probe ,这是基于假设受光照影响最大的地方都是在靠近静态物体的地方。
实际上,ILC 还包含两种 probe 放置方式:通过手动放置 Lightmass Importance Volume(重要光照范围)来限制烘焙光照采样范围,或 Lightmass Character Indirect Detail Volume,来增加一段均匀放置 probe 的区域。
- ILC 通过 CPU 寻找物体周围的 probe:所有的 probe 的数据将保存到八叉树中以方便物体找到周围的 probe

Volumetric Light Map
Volumetric Light Map, 即 VLM(体积光照贴图),也是 UE4 的方案,它使用网格(Grid)采样点保存 probe 数据,而在静态物体表面附近,会对网格进一步细分。
-
VLM 通过 GPU 来寻找物体周围的 probe :所有 probe 的数据将烘焙至贴图中,不同细分层度的网格将使用 level 不同的贴图,这样可以方便地在 GPU 中进行逐像素的三线性插值
-
VLM 比 ILC 的 probe 要多更多,从而 VLM 的 GI 效果更佳,但要存储的数据更多
-
VLM 的存储结构决定了可以通过 GPU 算法来寻找 probe,这比传统的 CPU 算法性能更加可观(即便 VLM probe 数量要多得多)
-
VLM 更适合将 probe 应用到体积雾效果中,这是因为 ILC 往往不在几乎没什么物体的空间放置 probe
UE 4.18 以后使用 VLM 代替了 ILC 方法作为 UE4 默认的 probe 方案。
ILC vs. VLM 效果图:

Local PRT [2023]
知乎上有篇非常有意思的思路,结合了 LPV 和 PRT 而实现的极低性能开销的完整 GI。其仍然采用均匀的 probes 分布,而核心在于:
每个 probe 只计算自身所在大约1m范围的局部空间的 transfer matrix 和 visibility 信息(称为 probeVisSH),然后再给 probe 的局部空间注入光照,从而形成局部空间内的出射 lighting 信息(称为 probeSH)。
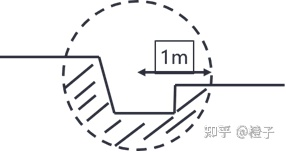
其中 transfer 信息为一次性(无需迭代,利用 neumann law 化简近似)计算出的局部空间 infinite bounce 的 transfer matrix。
首先第一个问题,如何计算每个 probe 的局部空间 infinite bounce transfer matrix:如果场景基本固定,就可以预计算每个 probe 的局部空间 infinite bounce transfer matrix,而 infinite bounce transfer matrix 的计算需要有 n 个局部空间的物体表面点样本参与,n 越多效果越 ground truth。虽然文章中提到也可以实时计算,但是可能会导致粗糙的渲染质量(实际上就是 n 取小些或者干脆放弃 infinite bounce)。
后来原文更新了一种克服局部空间含动态物体的做法:对每个动态物体预计算 infinite bounce transer,然后将这些 object space probes 注入到 world space probes 上(其实就是 object space probe 踩在哪个 world space probe 就给它的 transfer matrix 进行叠加和它的 local visibility SH 进行 triple product)。
在每帧运行时,每个 probe 通过 3D 卷积的形式分帧将 local visibility 信息传播到邻域的 probes。随着帧数累积,各个 probe 可以得到一个逐渐完整的 global visibility,从而可以快速实现 sky lighting ao。
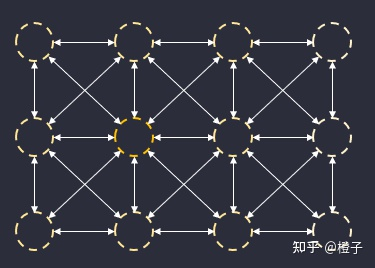
类似地,在每帧运行时,每个 probe 还会通过 3D 卷积的形式分帧将出射 lighting 信息传播到邻域的 probes。随着帧数累积,各个 probe 也能由此间接感知远处别的 probes 的 lighting 信息,也就实现了远距离 GI 传播。当然这个 lighting 的邻域传播需要考虑 local visibility 信息和 local transfer matrix 信息,传播的核心代码可见原文。
原理不多做描述,更具体可见知乎原文 GI from Local Radiance Transfer——适合移动端上的0.5ms 全动态全实时GI - 知乎 (zhihu.com)。
但个人感觉该方法还是有相当缺点:
- 光照突变(例如突然开关灯)会导致画面光照效果产生比 ray tracing 类算法更久的延迟。实际上就是光照信息一帧只能传播到一个 probe 的间距这么远,“光速”变慢后导致的。
- naive 的 probe 卷积可能会导致错误的传播效果(至少原文中的代码不够准确),最好做一定矫正。
- 可能的内存/显存占用过大:虽然 local trasfer matrix 只在物体附近才存储,但是对于 visibility SH 和 lighting SH 仍需要 3D volume(本身 lighting 和 visibility 就是四个 float 表示,如果用二阶SH的四个系数,那就需要四张 RGBA 3D纹理存储),也许会比较占空间(没看过源代码,没测过,不好说)。
个人想到的一些可能的改进:
-
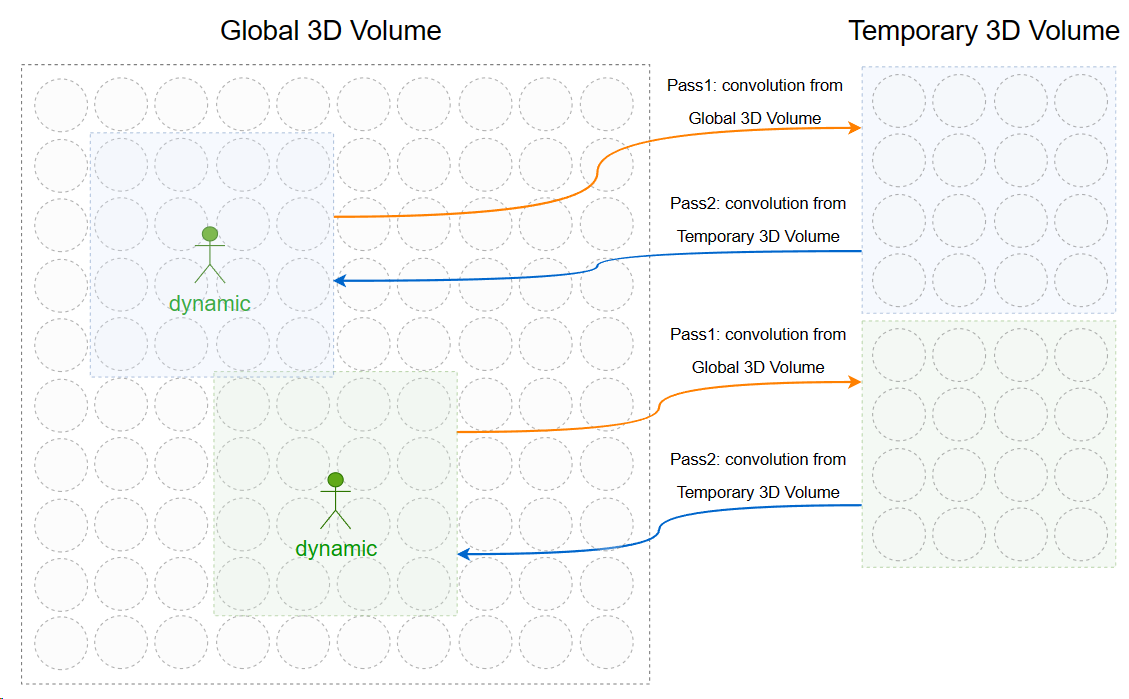
针对光照突变问题,如果光源变化不大(例如昼夜变化),那么感觉延迟似乎还是能够接受的。而针对动态物体变化产生的光照突变,可以先对动态物体内一定范围的 volume 进行额外的两次卷积 pass 以加速其一定范围内的光照传播,并且也不需要两张 global 3d volume texture 的显存占用。另外,当多个动态物体的 temporary volume 有重叠时可能会导致竞争写,因此可能需要在 CPU 对潜在重叠的 volume 进行合并成更大的 volume。
原理如图所示:
DDGI
DDGI(Dynamic Diffuse Global Illumination) 是一种支持动态光照的 probe 方案,在场景中均匀摆放 probes,并采取 ray tracing 的方式去实时探测动态光照信息,并且使用了 八面体映射(octahedral mapping) 技术来缓存收集到的光照信息。

常见的 DDGI probe 数据组成:
- 6×6 irradiance texture:存储每个 texel 方向的 irradiance \(E(\omega)\) 。
- 14×14 moment texture:存储每个 texel 方向的深度 \(r(w)\) 及深度的平方 \(r^2(w)\),以便进行切比雪夫不等式测试。
有关于优化和改进 DDGI 的方案,可以详见于 动态漫反射全局光照Dynamic Diffuse Global Illumination | 知乎 [宇亓],这方面个人觉得宇亓的文章会更加全面。
RTXGI 1.0 [2019]
NVIDIA 的 DDGI 实现版本则一般称之为 RTXGI 技术,并且使用到了 RTX 显卡的硬件光追特性。
RTXGI Volume
一个立方体积区域,里面均匀放置着 probes(类似于 grid 分布),在 volume 内的物体就能被间接光照亮,实现 GI 效果。
- volume 支持动态位置,这与基于烘焙的 irradiancec probe 形成对比。
- 虽然 volume 也需要手动放置,但是粒度更大,比起手动放置 probe 工作量要少得多。
在实践中往往会使用 clipmap 方式,即使用多个覆盖范围不同的 volumes 绑定到 camera 上,这样就可以跟随 camera 移动对视野内的一定范围的物体应用间接光照,并且具有质量上的 LOD 效果(近处采用高精度 volume,远处采用低精度 volume)
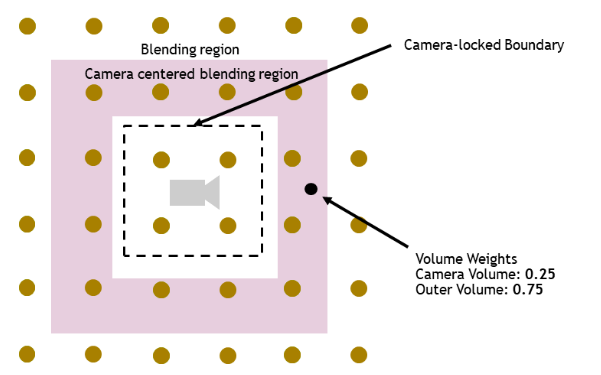
因此还需要在嵌套多层的 volume 之间会做一个线性淡出从而避免明显的边界。
RTXGI Volume 当然也能固定位置,例如为大区域放置一层大 volume,再嵌套地为每个小区域再分别放置一层 volume。
probe scrolling
ray tracing
probe 均匀向球面方向上射出若干个 rays,并计算出每根 ray 的 radiance 和 hitT。这其中需要使用到 RTX 显卡的 ray tracing pipeline 特性,得到 hitT 和 hit point 的 normal,albedo,emissive 信息。
接下来需要计算 ray 的 radiance:\(L(ray) = L_{one} + L_{multi} + Emissive\)
- one-bounce lighting:通过 hit point position,normal,albedo, rayDir 进行 hit point 的直接光照着色
- multi-bounce lighting:通过 position,normal 并利用周围 probes 的上帧 irradiance texture 来重建 hit point 的光照信息,并进行间接光照着色
间接光照着色必须使用 diffuse BRDF,即乘 albedo 除 PI。因为 irradiance 丢失了入射角相关的光照强度信息,无法使用 specular/glossy BRDF。
最后将 hitT 结果和 radiance 结果写入 ray buffer 中。
probe update
使用 ray buffer 中的 radiance 来更新 probe 中的 irradiance texture。
使用 ray buffer 中的 hitT 来更新 probe 中的 moment texture。
这些更新都是以一定历史混合权重(例如0.9)来更新 texture 而非直接覆盖。
probe classification
RTXGI 引入了 probe 状态机(包含 inactive 和 active 两种状态),在更新/ray tracing/重建光照等行为中直接跳过 inactive probes,从而减少所需要更新的 probes 数量。
怎么判定一个 probe 是否 inactive?主要分为两种情形:
- probe 可能会位于远离物体表面的空间位置(例如天空),从而无法被采样,也因此没必要为这部分 probes 生成射线。
- probe 可能会位于物体内部或者其它一些特殊位置,虽然可能会被采样到,但是会引入错误的光照插值结果,因为物体内部的光照信息和物体外部的光照信息不应当混合在一起。
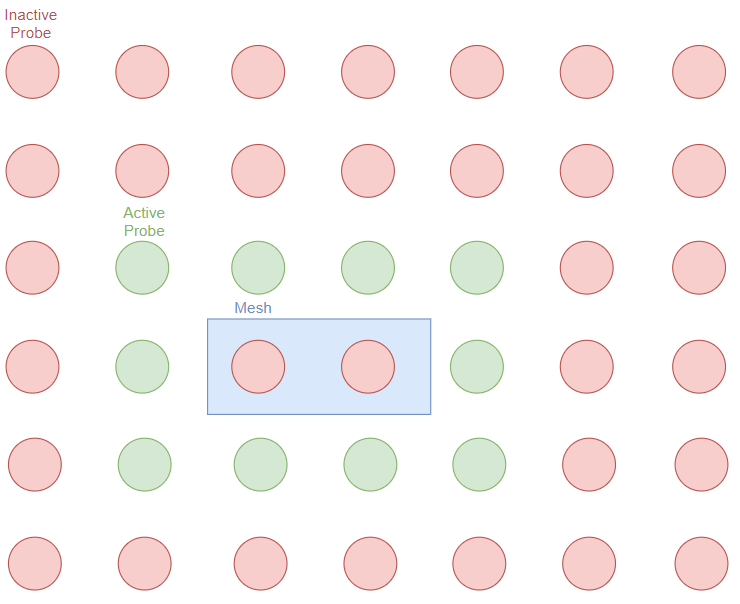
这些情形都可以通过 ray tracing 阶段得到的 hitT 来判断:
- 当该 probe 的所有 ray 的 hitT 均大于 probe 间距时,可以认为该 probe 位于远离物体表面的位置,设为 inactive。
- 当该 probe 有一定比例的 ray 命中的是 triangle backface 时,可以记 hitT 为负数,之后就可以认为该 probe 位于物体内部的位置,设为 inactive。
- 其它情况均为 active。
gathering
在最后我们需要对 shading point 进行着色的时候,就可以通过更新好 irradiance 的 probes 来重建 shading point 的光照信息:
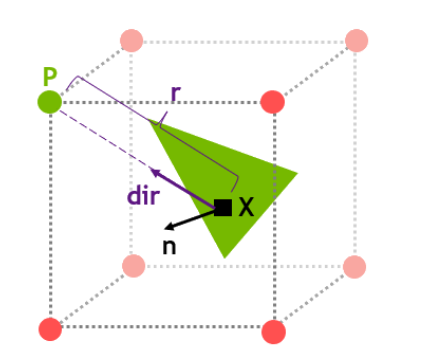
-
根据 shading point 的世界坐标找到其邻近的 8 个 probes
-
对每个相邻的 probe:
-
计算出 shading point 到 probe 的 \(dir\)
-
测试 \(dir\) 是否与 \(n\) 面向同一侧:若 \(dot(dir, n)\le 0\),则跳过该 probe
-
根据 \(dir\) 索引到 texture 中对应的 texel ,得到 \(E(dir)\) , \(r(dir)\) 和 \(r^2(dir)\)
-
计算 shadow 系数:根据 \(r(dir)\) 和 \(r^2(dir)\) 来对 shading point 进行切比雪夫不等式测试
-
该 shading point 受到的光照信息 irradiance 即为 \(E(dir)*shadow\)
-
-
对这些通过测试的 probes 算得的 irradiance,以距离为权重进行混合便能得到 shading point 的光照信息。
重建光照信息实际上在 DDGI 的流程走了两次,一次在计算 ray radiance 那块计算 multi-bounce lighting 用到了,另一次便是在这里需要计算 shading points 的着色。
Mobile DDGI
ray tracing
移动端跑 DDGI 算法,最大的问题在于移动端机器很多(或者说几乎)都不支持 ray tracing pipeline 特性,无法正常走 ray tracing 阶段。当然,可以采用两种方式替换 ray tracing 阶段:
- 软件实现的 ray tracing 技术,如 SDF tracing + material cache,但一般都不如硬件实现的 ray tracing 精确,甚至性能开销也较大。
- 使用光栅化技术收集光照,输出到 cubemap render target 上。然而 1 个 probe 就对应 1 张 cubemap,并且假设场景拥有 m 个 mesh,那么 n 个 probes 就可能需要进行 m*n 次 draw call,这种开销也是无法承担的。
当然,结合 multi-view 硬件特性也可以进一步减少 draw call。
渐进式分帧更新
为此,可以利用分帧方式来更新 probe:每帧判断所有 probes 的重要性(考虑距离、最近更新的帧数等),并由此构建直方图。这样就可以每帧只对少部分 probes 进行更新,减少一帧的开销。当然,代价是带来延迟式的 probe 更新。
预计算材质
前面说到动态收集光照太费了,因此还可以尝试结合预计算。为每个 probe 预先烘焙出 material(而不是 irradiance 或 radiance)cubemap,然后通过每帧需要计算某个 ray 的 radiance 时,可以根据对应 texel 方向 material(例如 normal, albedo, position 等)实时计算出 hit point 的光照从而得到 ray radiance。
但这种方式也只可以支持动态光照,但不能支持动态场景。
Cascade Irradiance Cache [2024]
传统 DDGI probe 的 ray 的 max distance 基本得无限远或者一个比较大的值,这样的 ray tracing 往往开销是比较大的(HW ray tracing 相当于得遍历整个场景BVH):
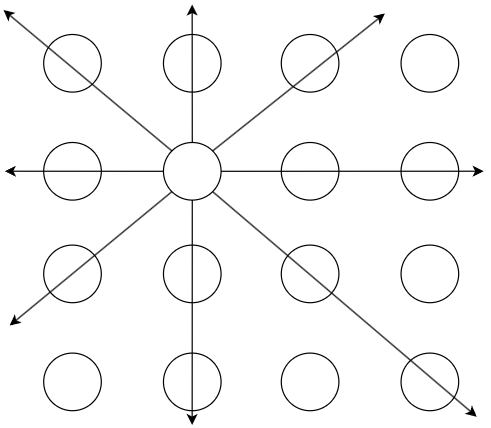
而 cascade irradiance cache 的核心是:让 probe 的 ray max distance 限制在 n 倍的 probe 间距内(原文采用了 2 倍 probe 间距),从而让 long ray 变成了 short ray,减少了 ray tracing 的开销。
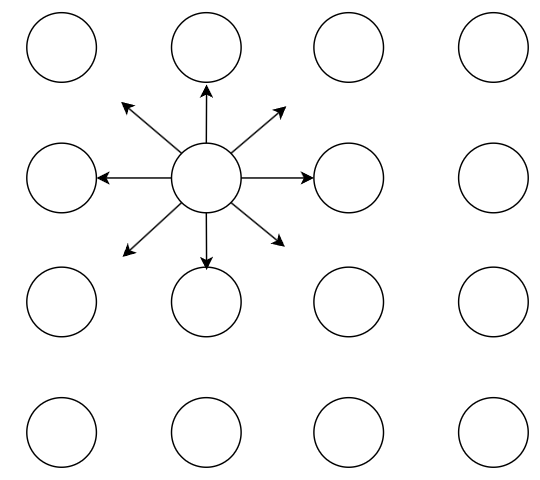
那问题来了,short ray hit 到物体还好,hit miss 的情况下又如何知道该方向的 radiance?
cascade irradiance cache 给出的解决方案是去采更高一层级的 probes 来算得 radiance,因为更高层级的 probes 拥有更大的间距从而能覆盖更远的 irradiance 信息。而至于最高层级 probe 发生 hit miss 时,就会直接去采 skybox。
Reflection Probe
reflection probe 与 irradiance probe 最大的区别在于前者往往存储的是 radiance map,而后者往往存储的是 irradiance map。而 radiance 往往不像 irradiance 那样平滑,因此往往需要非常高精度的存储,常用于 specular/glossy reflection 效果。
此外一提,大部分业界的 reflection probe 仍采用烘焙的形式,而非使用 ray tracing 动态收集光照(当然也有用光栅化方式收集光照的,输出到 cubemap render target 上)。
前面谈到的烘焙 irradiance probe 亦或者 DDGI 都是比较经典的 irradiance probe。当然也有混合存储的 probe 形式,例如 Lumen 的 screen probe 就不仅包含 radiance map 信息还包含 irradiance SH 信息。
Parallax Correction
由于 radiance map 的信息与视角方向相关,并且信号比较高频,因此查询方向稍微偏差一点都可能会导致严重的画面错误(而 shading point 的位置往往和 probe 位置有一定偏差)。为了矫正这种偏差,在使用 reflection probe 时往往需要做 parallax correction(视差矫正)。
Simple Parallax
simple parallax 使用简单的球形/长方体形代表场景,首先算出 hit point 的 ray 与球形/长方体的相交点,连接 probe 与相交点的方向即为矫正后的查询方向:
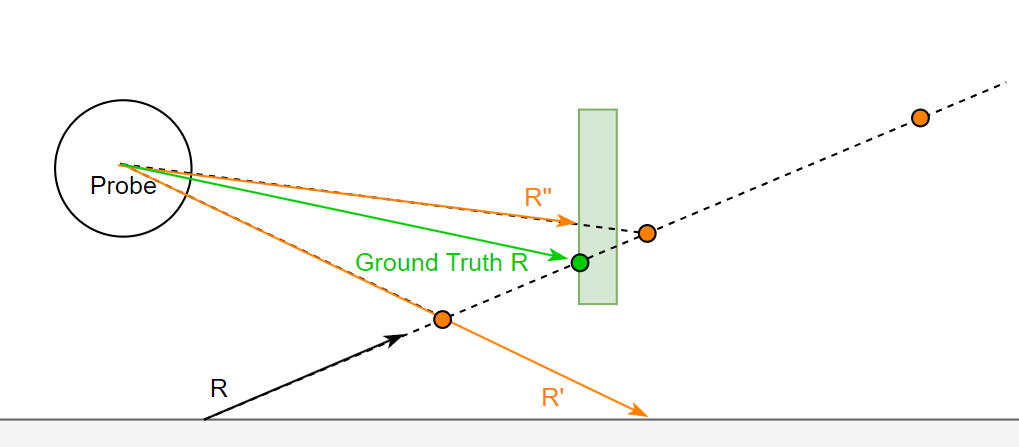
Probe Depth Parallax
从 hit point 往 R 方向,每隔一段位置(对应橙色点)就与 probe 连接得到一段连接向量。该连接向量单位化后可以用于采样 probe 并得到对应方向的深度,该深度将与连接向量的长度进行比较:若连接向量长度更长,那么说明 ray 在该橙色点前的某个位置与场景发生了碰撞,那么可以 hack 一下直接取该单位化后的连接向量作为矫正后的查询方向。
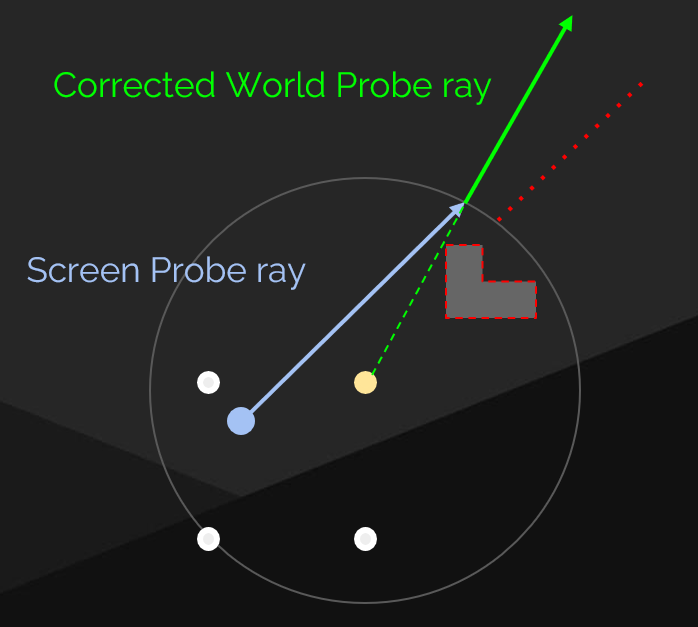
结合 SSRT 和 Ray Query [2023]
来源于 GDC2023《战神:诸神黄昏》的 rendering 演讲。
无论是 simple parallax 还是 probe depth parallax,算得的查询方向仍然与 ground truth 查询方向有一定偏差,也因此仍然存在一定程度的图像视角偏差现象。可以利用 ray tracing 技术来得到 hit point,从而连接 probe 和 hit point 得到更准确的查询方向。
在战神诸神黄昏的做法中,结合使用了低廉代价的 SSRT 和硬件支持的 ray query 特性,给定 shading point 的位置 P 和反射方向 R,那么:
- 首先尝试进行 SSRT:若 SSRT 命中则采样 screen color 作为本次 ray 的 radiance。
- 若 SSRT 未命中,则使用 ray query 得到准确的 hit point,并判断该 hit point 是否在 screen space 中:若在,则采样 screen color 作为本次 ray 的 radiance。
- 若 hit point 不在 screen space 中,则连接 probe 和 hit point 得到了 reflection probe 的查询方向,从而在对应的 radiance map 中查询到对应的 radiance 值。

在更具体实践中,我们不必对场景的原生 mesh 建立 BLAS,而是对场景 mesh 创建出更加简化的代理 mesh 后并以此建立 BLAS,可以大大减少 ray query 的开销(因为查询方向确实也不用太过精确)。
虽然现在硬件光追逐渐普及,但很多平台仍然不能支持 ray tracing pipeline 特性,只支持阉割的 ray query 特性。这种混合了 ray query 和烘焙的方式会比较适合从光栅化过渡到硬件光追的项目使用。
Screen Space Probe
Screen Space Probe:往屏幕若干个 pixels 对应的世界位置(即一些几何物体表面)贴上 probes,并让这些 probe 通过 ray tracing 的方式搜集动态光照。其实本质上相当于降分辨率的 pixel shading,并通过插值方式 upsampling 到原分辨率。得益于可以贴在几何物体表面的特性,screen probe 往往比传统 world probe 会更少一些漏光现象。
Screen Probe in Lumen [2021]
screen probe placement
Lumen 的 screen probe 是每帧全部重新生成的。
- uniform placement:在屏幕上均匀放置 probe(如每隔 16x16 pixels),因此往往用 1 个 tile 对应 1 个 uniform probe;一般使用 2d texture 存放 uniform probes。
- adaptive placement:在 uniform probes 之间,每隔一小段距离尝试进行插值测试,对插值失败的地方额外放置 probe;一般每个 tile 有对应存放 adaptive probes 的列表(通过 offset+count+global array 的数据结构来表示)。
所谓插值测试,一般是指根据 uniform probes 的世界坐标进行插值得出当前屏幕点的插值世界坐标,如果与当前屏幕点的实际世界坐标相差太大,那就意味着该位置出现几何上的突变,从而导致插值失败。

ray tracing
基于 Importance Samping(重要性采样)生成固定数量的 rays:
- 每个 texel 方向分配 1 根 ray,并算出每个 texel 方向对应的 lighting pdf(根据 4 个 history probe 的 radiance map 混合而成)× BRDF pdf。
- 将 pdf 值为 0 的 texel 方向剔除掉,并将原本应该分配给该 texel 方向的 ray 重新分配到 pdf 较高的 texel 方向,从而实现 Importance Samping。
screen probe 的 BRDF 以 SH 形式表示,并来源于附近 screen pixels 的 BRDF SH 混合结果。并且由于 screen pixels 的特性,screen probe 的 brdf 分布经常会出现另一半球的 BRDF 值为 0 的情况(毕竟很少有 normal 朝背面的 pixels)。

- 对生成的 rays 进行 tracing,并记录下对应的 radiance 结果(这里如何做 ray casting 就不多介绍了)。
- 根据各个 rays 的 radiance,转化成本帧的 radiance map。
由于 screen probe 往某个 texel 方向分配的射线数量有限(最多细分为 4 根),也因此在包含远距离光照的 texel 方向上比较难收敛。当然,后文会提到增加了一个 screen probe 层级的 filtering 后效果会好很多(主要是 temporal filtering 立功),然而在快速移动镜头时由于丢失历史信息,仍然会很容易出现不稳定的光斑现象,这就需要下面介绍的 world probe 解决光照稳定性问题。
图左的光斑现象便是丢失历史信息(无 temporal filtering)的效果。

利用 world probe
Lumen 中除了 screen probes,还有 world probes(被 Lumen 命名为 radiance cache)。只不过 world probes 不是基于屏幕生成,而是类似于 DDGI 那样在世界空间上均匀分布。world probe 的作用主要是为 screen probe 的 rays 提供一个更稳定的 radiance 结果。
在实践中,world probe 提供的稳定性效果非常重要。尤其是相机快速移动旋转时,屏幕边缘的 screen probe 丢失了 temporal 信息,会很容易产生光斑,这时候靠 world probe 可以抑制大部分的屏幕边缘光斑现象。
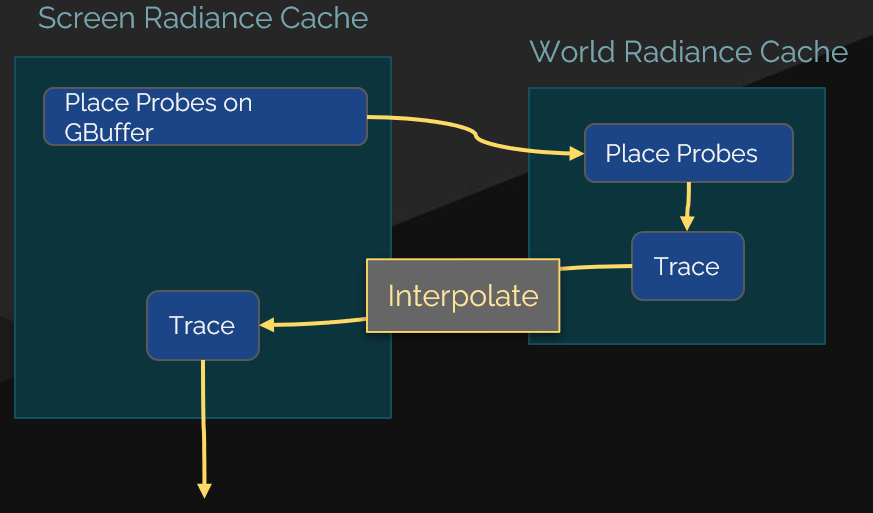
radiance cache 的主要特性:
- 比 screen probe 更稀疏的分布,但 world probe 的 radiance map 更高分辨率(更精确)。
- 和 screen probe 一样,也需要发出 rays 来搜集光照信息。
- 仅保留能影响到 screen probe 的 world probes(相当于剔除掉屏幕空间以外的 world probe)。

因此,引入了 radiance cache 机制后,screen probe 的 ray tracing 流程就变成了判断自己 ray casting 的距离是否达到足够远的阈值:
- 如果是,则停止 ray casting,转而去查找附近的 8 个 world probes,并根据射线方向来分别在这个 8 个 world probes 中矫正(用上面说的 simple parallax)成对应的查询方向,并以该方向映射到 world probe 中对应的立体角 texel,并由此在 world probe 的 radiance map 采样出对应的 radiance 值。
- 如果不是,则继续 ray casting,和原 ray tracing 流程一样(即直到 hit 到某个点进行采样,从而算出该 ray 的 radiance)。
screen probe filtering
一般对 probe 的 radiance map 各个 texel 进行 filtering。
- spatial filtering:由于 screen probe 是贴在屏幕上的,因此可以充分利用屏幕信息(G-Buffer)来作为 probe 层级 spatial filtering 的指导。
- temporal filtering:投影到上一帧某个位置并根据对应位置附近的 4 个历史 screen probe 来进行复用。
AMD GI-1.0: Two-Level Radiance Caching Scheme [2023]
与 Lumen 相比,AMD 的方案重点在于减少所需要更新的 screen probe 数量,即进一步优化性能。
screen probe reprojection
和 Lumen 类似,基本每个 tile 需要对应生成一个 screen probe,然而 AMD 方案会利用 reprojection 避免大部分 screen probe 的重新生成。
具体来说,tile 内每个 pixel 会通过 motion vector 来投影到历史帧,并评估其与最近 history probe 的几何差异度。接着,从 tile 中挑选出一个差异度最低的 pixel 作为 probe 的位置,并直接把 history probe 的内容填充到当前 probe 的内容,就避免了重新生成当前 probe 的计算开销。
会存在 reprojection 失败的情形,即每个 pixel 投影到历史帧位置都找不到比较相似的 probe 或者越出屏幕边界。
当然,不移动屏幕,一直使用 history probe 的信息也是不合理的(不会更新光照),因此 AMD 方案每帧强制重新生成 1/4 的 probes(Lumen 则是重新生成全部 probes)。
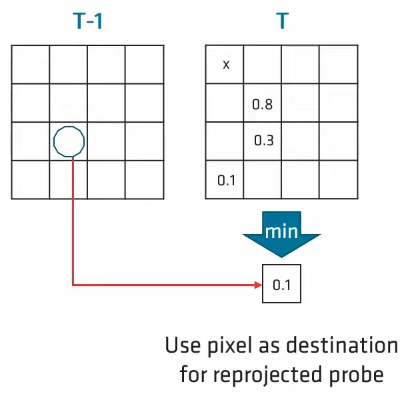
为此,使用了三种 tile 队列来决定最终应当为哪些 tiles 重新生成 probe:
- empty tiles 队列:reprojection 失败的 tiles,可以理解为丢失历史 probe 信息的无效 tile。
- spawn tiles 队列:将要生成 probe 的 tile id 队列,其元素数量为 1/4 的 probes 数量。初始包含元素:处于 1/4 checkerboard pattern 的 tiles。
- override tiles 队列:reprojection 成功(即为已经有历史 probe 信息的有效 tile)且同时处于 1/4 checkerboard pattern 的 tiles。
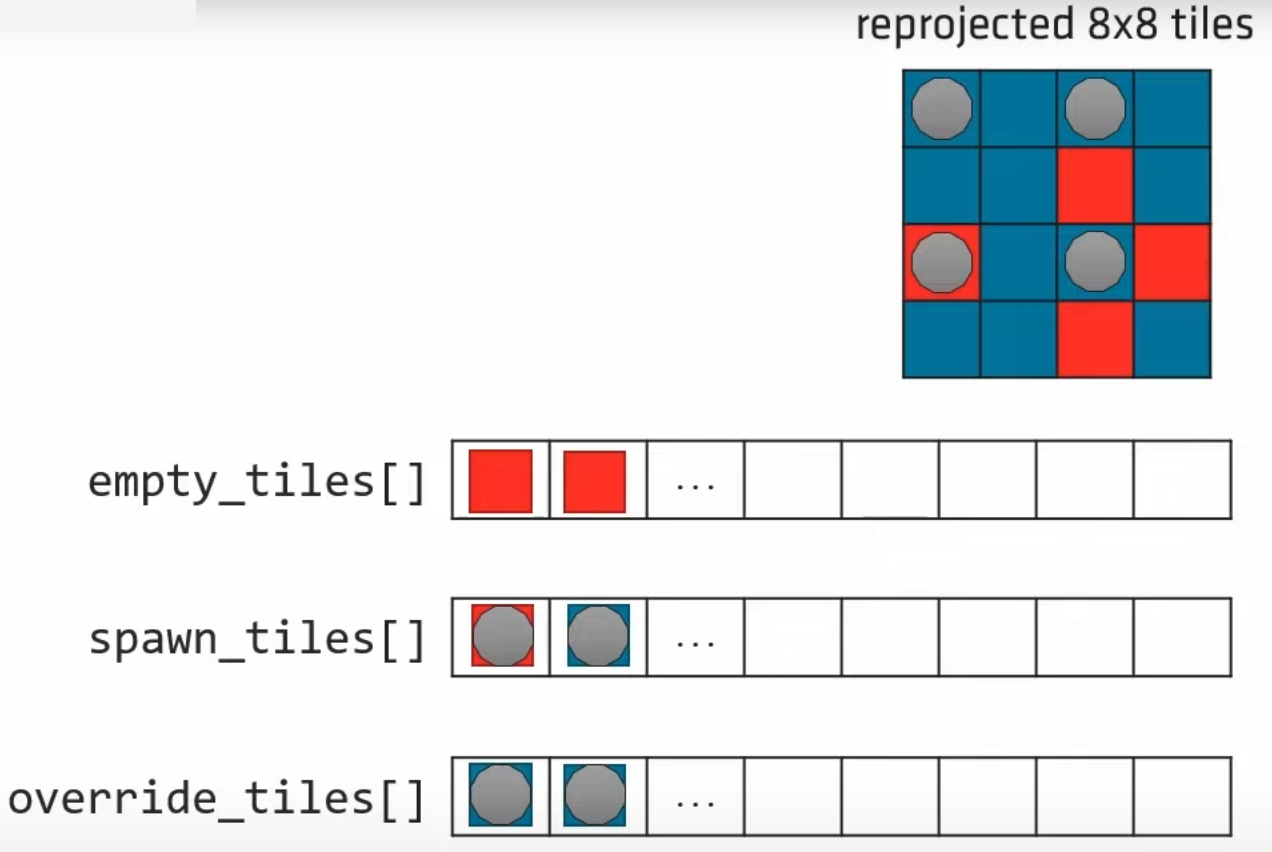
我们倾向于为 reprojection 失败的 tiles 用于重新生成 probe,为此会随机抽一些 override tiles:对每个被抽到的 override tile,需要将自己对应的 spawn tiles 与 empty tiles 交换,从而实现原本给自己 spwan probe 的机会让给 empty tiles。
但是原文并不推荐把所有 override tiles 都将 spawn 的机会让给 empty tiles,因此采用了随机抽一些的方式,但这也意味着在本帧仍然可能会有 empty tiles 不会生成 probe。
empty_tile = empty_tiles[tid];
override_tile = override_tiles[random_index];
InterlockedExchange(spawn_tiles[override_tile], empty_tile);
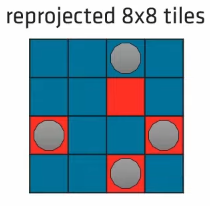
screen probe caching
在第一帧,tile 在某个 pixel 上生成了 probe1;而在下一帧如果该 tile 将生成新的 probe,那么将在另一个 pixel 上重新生成 probe2。
那么这时候问题来了:可能这两个 pixel 是完全不同的几何,从而导致 probe2 和 probe1 的光照信息相差过大,可能会产生光照闪烁现象(其实就是采样率过低导致的)。
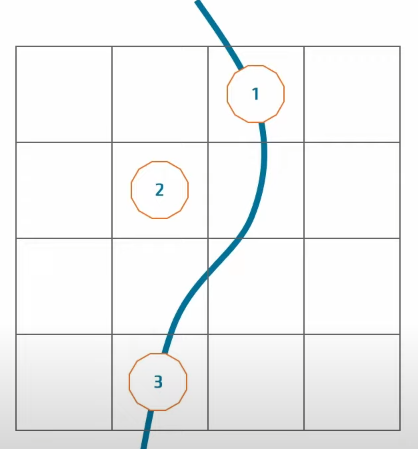
AMD 方案采用了 LRU Cache 方案,为每个 tile 存储固定若干份 probe 信息,并根据 LRU 规则来换入换出 probe 信息。当然缺点就是若干倍的 probe 存储空间开销。
ray tracing
基于 Importance Samping(重要性采样)生成固定数量的 rays。不过,在计算 lighting pdf 的时候并不是像 Lumen 那样简单的基于距离去混合 2x2 个 history probe 的 radiance map 信息,而是采用了基于 parallax correction 的混合方式(并且混合的是 3x3 个 history probes 而非 2x2 个)。
具体怎么 parallax correction 呢?history probe 包含了每个 texel 的深度信息,因此可以重建出大致的 hit point position,然后连接 new probe 和 hit point 便是视差矫正后的方向。
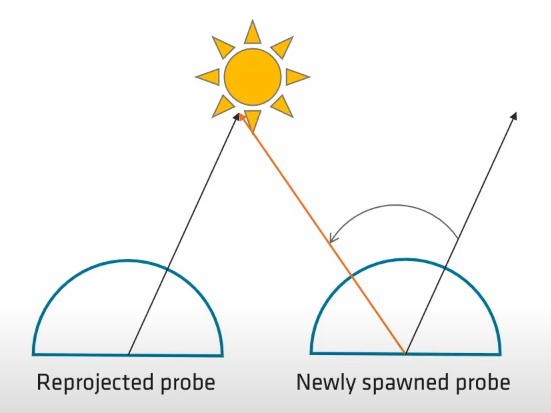
这种 parallax correction 方式也决定了必须得从 history probe scatter 到多个 new probes,而不能用 new probe 访问多个 history probes:
- Lumen:对于每个 radiance map texel,访问 2x2 个 history probe texels 来进行混合后得到本 texel 的 lighting pdf。
- AMD:对于每个 history radiance map texel,根据自身的 radiance 值来对周围 3x3 的 new probes 对应的 texel 进行 4 次
InterloackedAdd(4 个 float 对应 radiance rgb 和权重 w)。在之后每个 texel 将自己得到的 rgb sum 除于 w sum 便可以得到本 texel 的 lighting pdf。
scatter 后,可能有些 new probe texels 一直都没被 InterloackedAdd 过,从而 lighting pdf 为 0,会造成能量丢失。为此,AMD 方案很 hack 直接使用了当前 probe 所有 texels 的平均 radiance 作为空洞 texel 的 lighting pdf。
当然也可以强制让每个 texel 至少 1 根 ray,但是会导致 ray 数量过多,开销过多。
在上面的操作做完后,终于有完整的 lighting pdf 了,就可以用离散逆变换采样方式生成 rays,并且 ray tracing 后得到新的 radiance 后,可以和原有的 lighting pdf(其实相当于 history radiance)进行混合(实际上就是 screen probe 的时序滤波)。
screen probe filtering
虽然前面的 screen probe reprojection 通过三队列机制大大减少无效 probes,但是仍可能存在一定数量的无效 probes(尤其是镜头快速移动时)。为此,在进行 screen probe filtering 的时候需要跳过这些无效 probes。
为此,引入了 probe mask mipmap:mip n 的每个 texel 代表了对应 \(2^n\) 个 probes 是否有效,若无效则值为0,若有效则存储这些 probes 中第一个有效的 probe 的 index。

这样在进行 filtering 的时候,如果发现采样到了无效 probe,那么就去更高级的 probe mask mip 继续采,直到采到一个有效 probe index 时再访问对应的 probe 信息。
AMD 采用了 7x7 样本数的 screen probe 空间滤波,并且使用了 separable blur 的方式(即横向 blur 和纵向 blur 共两个 pass)。而 screen probe 的时序滤波是内含在 ray tracing 阶段中的计算 lighting pdf 过程中....不过u1s1,AMD 的方案也挺杂的,本文篇幅有限,就不全面介绍了。
Probe 的 Light Leaking 问题
不过 probe 经常会遇到错误的 Light Leaking (漏光)问题:受到几何上不应该存在光照关系的 probe 影响,常见于墙壁遮挡的内外侧。
例如,下面的一个 probe 生成在室内,我们预期室外的墙体是亮黄色的,室内的墙体是暗灰色的:
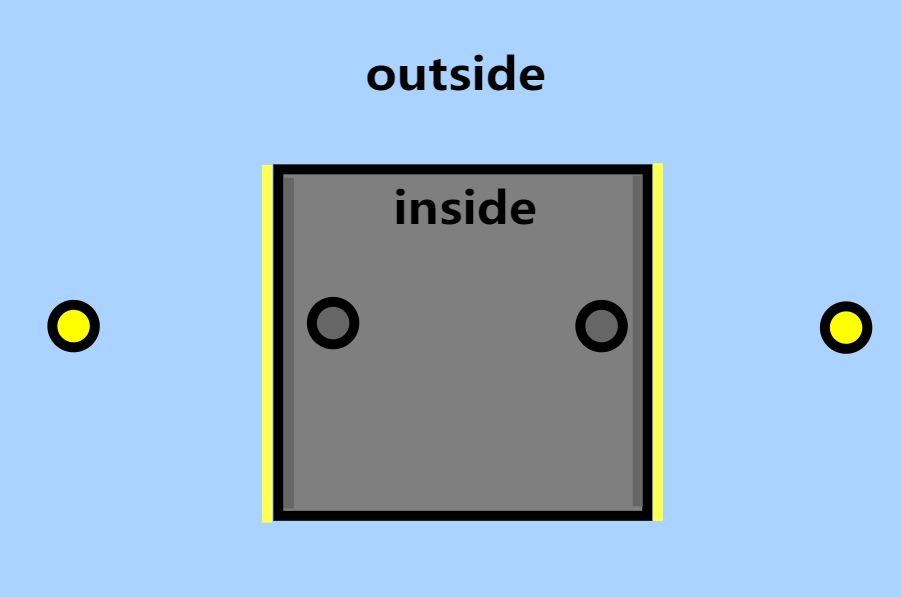
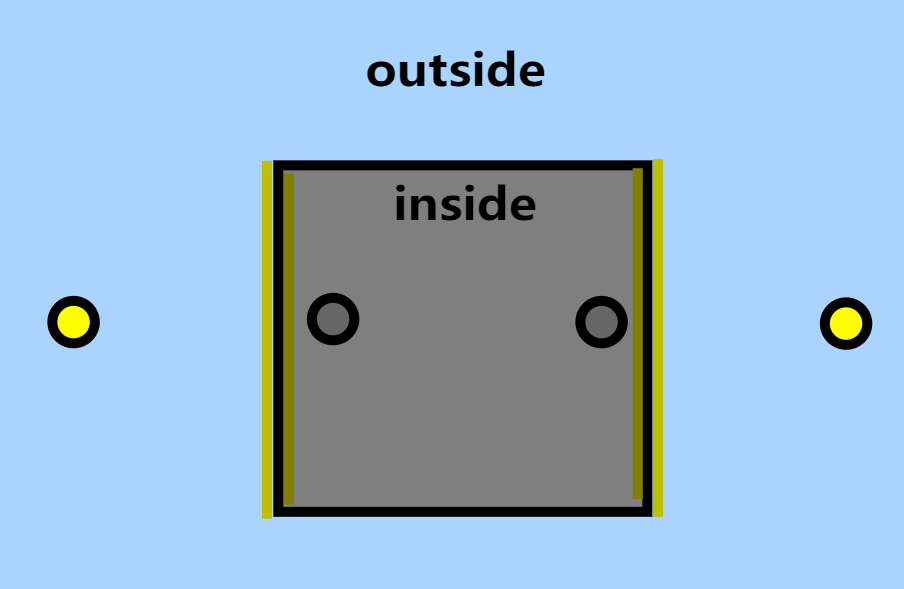
结果由于 probe 方法没有考虑遮挡,而是直接且错误地进行了对相邻的 probe 插值,从而室外本该明亮的一侧变暗,室内本该黑暗的一侧发生 light leaking:
标记法
这个方法很直观,就是预先给 probe 额外一个标记属性:属于哪个区域(例如1为在室内,0为在室外);这样我们要拿 shading point 周围的 probes 来插值时,根据 shading point 在哪个区域的情况来选择用哪种标记属性的 probes 来进行计算。
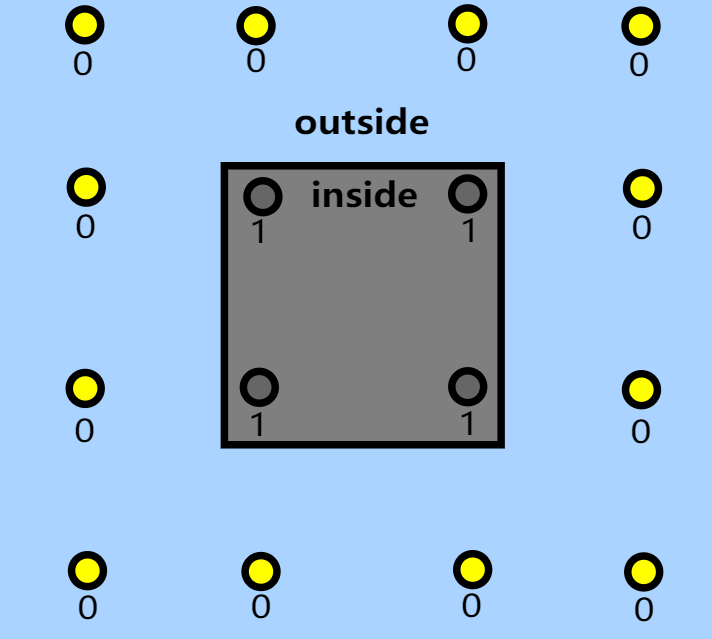
虽然粗暴直接,但是开销低廉,实际效果很 work,很多游戏工业界都会采用的方法(例如原神)。在一些方案中,这些标记也可以由自动化生成,而无需人工生成。
这种往往和基于烘焙的方案相互搭配,毕竟生成标记本身就是基于预计算的。
切比雪夫不等式测试
一些 probe 将半球方向上每个 texel 方向的深度存入到基于八面体映射的 depth texture 上。
那么在重建 shading point 光照信息时,我们就可以使用类似 shadow map 的思想来检测 shading point 到该 probe 的光路会不会被遮挡,从而计算出该 probe 对 shading point 的贡献:
\(x_{probe}\) 为 probe 的位置,\(x\) 为 shading point 的位置。
上述方式可能会造成一些硬边缘,为此进一步可使用类似 variance shadow map 的思想,让 depth texture 存储深度(R通道)和深度平方(G通道),并基于切比雪夫不等式(Chebyshev’s Inequality) 去做光滑的遮挡测试(避免硬边缘) :
当然实际上存储深度和深度平方一般称为 moment texture 了。
Probe Offset
如果让 probe 直接按均匀网格方式分布,很容易导致一些 probes 嵌在物体表面亦或者离表面非常近,从而导致切比雪夫不等式测试的误差更大,更容易导致漏光。
可以为每一个 probe 引入一个 offset 属性。在计算 probe 的位置时需要叠加上 offset,这可以让一些 probes 偏移至稍微远离物体表面的地方,甚至将一些原本嵌在物体内部的 probes 推出到物体表面以外(从而提供有效光照)。具体赋予 offset 的方式可以有如下:
- 预计算每个 probe 的 offset + 允许艺术家自定义每个 probe 的 offset。
- [RTXGI 1.0, 2019] 让 probe 自身根据光照探测情况(根据 ray hitT)动态改变 offset。
- [SDFDDGI, 2020] 让 probe 根据自身位置所在的 SDF 及其导数来决定 offset。
Bias Vector
正如 shadowmap 中的 bias 技巧,在利用 probe 重建 shading point 光照信息时也可以给 shading point 本身的位置施加 bias vector,从而更进一步减少漏光。
下面是一个比较经验的 bias vector 公式:
TunableShadowBias 默认为 0.3。\(n\) 为 shading point 的法线,\(w_o\) 为出射方向(其实一般就是 ray 的反方向)。
参考
- [1] Light probe interpolation using tetrahedral tessellations | GDC2012
- [2] Radiance Caching for Real-Time Global Illumination | SIGGRAPH 2021 Advances in Real-Time Rendering in Games course
- [3] RTXGI: SCALABLE RAY TRACED GLOBAL ILLUMINATION IN REAL TIME | 2020
- [4] Dynamic Diffuse Global Illumination with Ray-Traced Irradiance Fields | 2019
- [5] 虚幻引擎学习之路:渲染模块之全局光照明
- [6] 动态漫反射全局光照Dynamic Diffuse Global Illumination | 知乎 [宇亓]
- [7] UE5 Lumen 源码解析(六)Importance Sampling 篇 | 知乎 从越
- [8] Probe-Based Global Illumination | 知乎 MaxwellGeng
- [9] 游戏中的全局光照(四) 漫反射GI | 知乎 TC130
- [10] 三十、DDGI(一)- 概述 | 知乎 雾归流
- [11] GI-1.0: A Fast Scalable Two-Level Radiance Caching Scheme for Real-Time Global Illumination
- [12] GDC 2023 - Rendering 'God of War Ragnarok'
- [13] GI from Local Radiance Transfer——适合移动端上的0.5ms 全动态全实时GI - 知乎 (zhihu.com)
- [14] Signed Distance Fields Dynamic Diffuse Global Illumination | 2020
- [15] GDC 2024 | Advanced Graphics Summit: Raytracing in Snowdrop: An Optimized Lighting Pipeline for Consoles
作者:KillerAery
出处:http://www.cnblogs.com/KillerAery/
本文版权归作者和博客园共有,未经作者同意不可擅自转载,否则保留追究法律责任的权利。
