MySQL中distinct的使用方法【转】
一、基本使用
distinct一般是用来去除查询结果中的重复记录的,而且这个语句在select、insert、delete和update中只可以在select中使用,具体的语法如下:
select distinct expression[,expression...] from tables [where conditions];
这里的expressions可以是多个字段。本文的所有操作都是针对如下示例表的:
CREATE TABLE `person` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`name` varchar(30) NULL DEFAULT NULL ,
`country` varchar(50) NULL DEFAULT NULL ,
`province` varchar(30) NULL DEFAULT NULL ,
`city` varchar(30) NULL DEFAULT NULL ,
PRIMARY KEY (`id`)
)ENGINE=InnoDB;
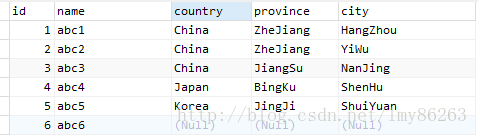
1.1 只对一列操作
这种操作是最常见和简单的,如下:
select distinct country from person
结果如下:
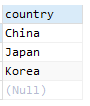
1.2 对多列进行操作
select distinct country, province from person
结果如下:

从上例中可以发现,当distinct应用到多个字段的时候,其应用的范围是其后面的所有字段,而不只是紧挨着它的一个字段,而且distinct只能放到所有字段的前面,如下语句是错误的:
SELECT country, distinct province from person; // 该语句是错误的
抛出错误如下:
[Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘DISTINCT province from person’ at line 1
1.3 针对NULL的处理
从1.1和1.2中都可以看出,distinct对NULL是不进行过滤的,即返回的结果中是包含NULL值的。
1.4 与ALL不能同时使用
默认情况下,查询时返回所有的结果,此时使用的就是all语句,这是与distinct相对应的,如下:
select all country, province from person
结果如下:

1.5 与distinctrow同义
select distinctrow expression[,expression...] from tables [where conditions];
这个语句与distinct的作用是相同的。
1.6 对*的处理
*代表整列,使用distinct对*操作
select DISTINCT * from person
相当于
select DISTINCT id, `name`, country, province, city from person;
文章转自:https://blog.csdn.net/lmy86263/article/details/73612020

 浙公网安备 33010602011771号
浙公网安备 33010602011771号