
【复健】树状数组2
 明天下午准时踹我补完
明天下午准时踹我补完
树状数组复健2
注:因为习惯和省事问题,下文的
为什么重写

↑您不觉得我这玩意写得逻辑不通吗而且抽象
关于树状数组
是什么
并不是一种树形结构。
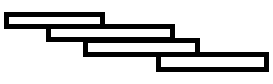
↑按照我的理解这玩意差不多长成这个样,类似砖头
通过一些分散的小区间来储存数据,每个数据可能会同时出现在多个区间内。包含同一个数据的相邻两个区间之间间隔
为什么
快(这不废话吗
对于一个普通数组,单点修改的复杂度是
其中
树状数组单点修改和区间查询的复杂度都是
另外一点是,如果实在没时间打线段树,树状数组的码量会小一点。
关于 lowbit 运算
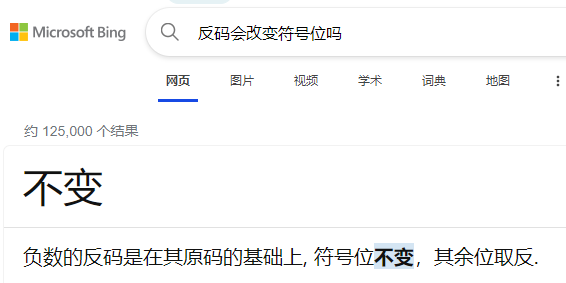
所以可得
因为正数的补码和原码相同,负数的补码和对应的正数相比,除了最后一位
偶数比如
代码实现
因为是砖头(?)式排列 法,可以参考在砖墙上涂鸦(?
修改一种砖头的纹路需要把所有包含这种纹路的砖头都修改,查询类比前缀和。
其实不看成砖头理解起来也没有任何麻烦(
注:默认原始数组为
单点修改
因为区间间隔是
void update1(int i, int x) {
for(int pos = i; pos <= n; pos += lowbit(pos)) bit[i] += x;
}
区间修改
只需要把单点修改丢进
void update2(int l, int r, int x) {
for(int i = l; i <= r; ++i) update1(i, x);
}
求前 n 项和
第一个区间不一定包含第
但是反过来,先查询第
为什么?
再看看这行代码:for(int pos = i; pos <= n; pos += lowbit(pos)),在初始化时我们必然使用 update1 操作来初始化每个编号为
int query1(int i) {
int ans = 0;
for(int pos = i; pos; pos -= lowbit(x)) ans += bit[pos];
return ans;
}
区间查询
类比前缀和。
int query2(int l, int r) {
return query1(r) - query1(l - 1);
}
如果想要单点查询, 直接 query(i, i) 即可。
例题们
咕咕咕
本文作者:Kiichi
本文链接:https://www.cnblogs.com/Kiichi/p/17956597/BITfujian2
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步