hadoop2.6.5安装(二)
hadoop2.6.5安装(一)应该算安装前期的踩坑记录,该文是针对完全分布式的基本安装配置。
系统:CentOS 7.2
软件:
jdk 8 (链接:http://www.oracle.com/technetwork/cn/java/javase/downloads/jdk8-downloads-2133151-zhs.html)
hadoop 2.6.5 (链接:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.6.5/)
前期理论:
Hadoop的核心模块就是HDFS (hadoop分布式文件系统,能提供高吞吐量的数据访问,适用于超大数据集的应用) 以及MapReduce(支持java语言的一套从海量数据中提取分析元素返回结果集的编程模型);hadoop旗下的子项目例如:HBase、Hive 等都是基于前面两者发展实现的。
一、准备工作
1.至少3台机器,分别部署1个主节点和2个从节点(三个节点最好都是 同一网段的内网地址,因为我使用的是不同网段的外网地址,后续踩坑无数)
HDmaster 118.25.50.236 HDslave1 118.25.8.59 HDslave2 111.231.92.235
2.首先在3台机器的/etc/hosts 分别配置好以下信息
[root@HDmaster ~]# vim /etc/hosts #添加好如下域名,方便后续解析 118.25.50.236 HDmaster 118.25.8.59 HDslave1 111.231.92.235 HDslave2 #然后可以选择scp到另外的机器或者直接复制粘贴也ok
设置好之后测试一下,域名解析是否ok,排除防火墙、网关的网络影响


1 [root@HDmaster ~]# ping HDmaster -c2 2 PING HDmaster (118.25.50.236) 56(84) bytes of data. 3 64 bytes from HDmaster (118.25.50.236): icmp_seq=1 ttl=63 time=0.336 ms 4 64 bytes from HDmaster (118.25.50.236): icmp_seq=2 ttl=63 time=0.360 ms 5 --- HDmaster ping statistics --- 6 2 packets transmitted, 2 received, 0% packet loss, time 1000ms 7 rtt min/avg/max/mdev = 0.336/0.348/0.360/0.012 ms 8 [root@HDmaster ~]# ping HDslave1 -c2 9 PING HDslave1 (118.25.8.59) 56(84) bytes of data. 10 64 bytes from HDslave1 (118.25.8.59): icmp_seq=1 ttl=61 time=0.338 ms 11 64 bytes from HDslave1 (118.25.8.59): icmp_seq=2 ttl=61 time=0.403 ms 12 --- HDslave1 ping statistics --- 13 2 packets transmitted, 2 received, 0% packet loss, time 999ms 14 rtt min/avg/max/mdev = 0.338/0.370/0.403/0.037 ms 15 [root@HDmaster ~]# ping HDslave2 -c2 16 PING HDslave2 (111.231.92.235) 56(84) bytes of data. 17 64 bytes from HDslave2 (111.231.92.235): icmp_seq=1 ttl=63 time=0.371 ms 18 64 bytes from HDslave2 (111.231.92.235): icmp_seq=2 ttl=63 time=0.393 ms 19 --- HDslave2 ping statistics --- 20 2 packets transmitted, 2 received, 0% packet loss, time 1000ms 21 rtt min/avg/max/mdev = 0.371/0.382/0.393/0.011 ms
3.配置三台机器之间的ssh免密登录
因为我这三台机器有用于其他实验,已经配置过免密登录
1 [root@HDmaster ~]# egrep 'ssh' ~/.bashrc 2 #此处我也在bashrc文件中配置了别名,方便后续使用和测试ssh免密登录 3 #for ssh 4 #alias sshmaster='ssh root@111.231.79.212' 5 alias sshhdm='ssh root@118.25.50.236' 6 alias sshslave1='ssh root@118.25.8.59' 7 alias sshslave2='ssh root@111.231.92.235'
二、安装软件(三个节点都需要做如下步骤,此处以HDslave2为例)
1.由于mapreduce是依赖java的,所以必须先安装好jdk(选择与自己hadoop版本相对应的jdk,我这里选择jdk8,文章最前面提供了下载链接)
[root@HDslave2 local]# pwd /usr/local [root@HDslave2 local]# ls bin games jdk-8u152-linux-x64.tar.gz lib64 mha4mysql-node-0.53 mysql sbin src etc include lib libexec mha4mysql-node-0.53.tar.gz qcloud share sysbench
#解压jdk的tar包
[root@HDslave2 local]# tar zxf jdk-8u152-linux-x64.tar.gz
#配置java和hadoop 环境变量
1 [root@HDslave2 local]# vim ~/.bash_profile #设置在该文件下,只对当前用户root有效 2 [root@HDslave2 local]# vim /etc/profile #该文件是全局变量,对所有用户有效,建议是该文件,后续还需要一个 hadoop用户 3 #============================================= 4 # java home 5 export JAVA_HOME=/usr/local/jdk1.8.0_152 #该目录就是刚刚解压的jdk8的tar包文件 6 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar #在解压后的文件中找到jar包 7 8 PATH=$PATH:$HOME/bin:$JAVA_HOME/bin 9 export PATH 10 #=========================================== 11 "/etc/profile" 92L, 2102C written 12 13 [root@HDslave2 local]# source /etc/profile
#测试一下jdk8是否安装成功
[root@HDslave2 local]# java -version java version "1.8.0_152" Java(TM) SE Runtime Environment (build 1.8.0_152-b16) Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
2.安装hadoop 2.6.5
1 [root@HDslave2 local]# tar zxf hadoop-2.6.5.tar.gz 2 [root@HDslave2 local]# mv hadoop-2.6.5 hadoop 3 [root@HDslave2 local]# ls 4 bin hadoop jdk1.8.0_152 lib64 mha4mysql-node-0.53.tar.gz sbin sysbench 5 etc hadoop-2.6.5.tar.gz jdk-8u152-linux-x64.tar.gz libexec mysql share 6 games include lib mha4mysql-node-0.53 qcloud src 7 [root@HDslave2 local]# useradd hadoop 8 [root@HDslave2 local]# passwd hadoop 9 [root@HDslave2 local]# chown -R hadoop:hadoop ./hadoop #为安全起见,一般使用hadoop用户来启动hadoop 10 [root@HDslave2 local]# ls -l |egrep hadoop 11 drwxrwxr-x 9 hadoop hadoop 4096 Oct 3 2016 hadoop 12 -rw-r--r-- 1 root root 199635269 Feb 5 15:27 hadoop-2.6.5.tar.gz 13 [root@HDslave2 bin]# pwd 14 /usr/local/hadoop/bin
#查看一下hadoop的版本,检测是否安装成功了
[root@HDslave2 bin]# ./hadoop version Hadoop 2.6.5 Subversion https://github.com/apache/hadoop.git -r e8c9fe0b4c252caf2ebf1464220599650f119997 Compiled by sjlee on 2016-10-02T23:43Z Compiled with protoc 2.5.0 From source with checksum f05c9fa095a395faa9db9f7ba5d754 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.6.5.jar
三、配置集群/分布式环境
集群/分布式模式需要修改/usr/local/hadoop/etc/hadoop的5个配置文件(这里的配置是最基本的配置以保证正常启动,参考文件的详细参数可官网详查)
这些配置文件的目录都在hadoop的etc/hadoop 目录下,版本不同的话,会有所差异。如下是本文安装hadoop解压之后的配置文件目录夹
[root@HDmaster hadoop]# pwd
/usr/local/hadoop/etc/hadoop
但是本文使用的是Master节点作为NameNode来使用,另外两台slave作为DataNode。所以改写该文件如下:
1 #注意以下的文件中 HDmaster 就是我的namenode;HDslave1 HDslave2 就是datanode 2 #======================= hadoop-env.sh ========================= 3 #该文件主要是配置hadoop的运行环境,以jdk为背景的(可以echo $JAVA_HOME查找到该路径) 4 # add JAVA_HOME 5 export JAVA_HOME=/usr/local/jdk1.8.0_152 6 7 #====================== slaves ================================== 8 #配置从节点的配置文件,这个别名必须与/etc/hosts文件中的域名 ip是一一对应的。 slaves是作为DataNode的主机名写入该文件,每行一个,默认localhost。如果是伪分布式配置的话,也就是说节点即作为NameNode 也作为DataNode,保留localhost。 9 [root@HDmaster hadoop]# vim slaves 10 [root@HDmaster hadoop]# pwd 11 /usr/local/hadoop/etc/hadoop 12 [root@HDmaster hadoop]# cat slaves 13 HDslave1 14 HDslave2 15 16 #====================== core-site.xml =============================== 17 #该文件主要是配置namenode的ip和端口(HDmaster也是在/etc/hosts里面配置好的) 18 <configuration> 19 <property> 20 <name>fs.defaultFS</name> 21 <value>hdfs://HDmaster:9000</value> 22 </property> 23 </configuration> 24 25 #==================== hdfs-site.xml ======================= 26 #value 这里是设置了两个辅助接点datanode(因为默认是3个,我这里只有2个从节点,所以需要备注一下) 27 <configuration> 28 <property> 29 <name>dfs.replication</name> 30 <value>2</value> 31 </property> 32 #以下两个目录夹是namenode和datanode的目录夹存放一些日志文件 33 <property> 34 <name>dfs.datanode.data.dir</name> 35 <value>file:/usr/local/hadoop/dfs/data</value> 36 </property> 37 <property> 38 <name>dfs.namenode.name.dir</name> 39 <value>file:/usr/local/hadoop/dfs/name</value> 40 </property> 41 </configuration> 42 43 #======================== mapred-site.xml ========================== 44 #该配置文件是template复制来的,这个是配置mapreduce的调度框架 yarn 45 [root@HDmaster hadoop]# cp mapred-site.xml.template mapred-site.xml 46 [root@HDmaster hadoop]# vim mapred-site.xml 47 <configuration> 48 <name>mapreduce.framework.name</name> 49 <value>yarn</value> 50 </property> 51 </configuration> 52 53 #======================== yarn-site.xml ========================== 54 #该配置文件就是yarn调度的基本配置 55 <configuration> 56 <name>yarn.nodemanager.aux-services</name> 57 <value>mapreduce_shuffle</value> 58 </property> 59 </configuration>
#############################################################################
#到这里为止,就是最基本的配置ok了
#把以上修改好的配置文件打包,然后scp到其他节点
(这里是由于hadoop整个文件打包传输太慢了,一般为了保证hadoop版本一致性,建议打包并传输整个hadoop目录)
[root@HDmaster etc]# tar zcf hadoop_master.tar.gz ./hadoop/ [root@HDmaster etc]# ls hadoop hadoop_master.tar.gz [root@HDmaster etc]# scp hadoop_master.tar.gz HDslave1:/root/hd [root@HDmaster etc]# scp hadoop_master.tar.gz HDslave2:/root/hd
#把这些配置文件应用到两台slave节点上
[root@HDslave2 hd]# tar zxf hadoop_master.tar.gz [root@HDslave2 hd]# cd /usr/local/hadoop/etc/ [root@HDslave2 etc]# ls hadoop [root@HDslave2 etc]# mv hadoop hadoop.old [root@HDslave2 etc]# cp -r ~/hd/hadoop ./ [root@HDslave2 etc]# ls hadoop hadoop.old
#还需要在三台机器上的/etc/profile的路径中,把hadoop的路径加进去
(只要echo $HADOOP_HOME 是正确的路径,其实随意配置都可以的)
1 [root@HDslave2 etc]# vim /etc/profile 2 #============================================= 3 # java home 4 export JAVA_HOME=/usr/local/jdk1.8.0_152 5 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar 6 # hadoop home 7 export HADOOP_HOME=/usr/local/hadoop 8 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop 9 10 PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin 11 export PATH 12 #===========================================
#不要忘记source一下
[root@HDslave2 etc]# source /etc/profile
四、集群环境格式化并启动
1 #以下步骤在HDmaster在执行即可 2 [root@HDmaster bin]# cd /usr/local/hadoop/bin/ 3 #这个是对namenode格式化,输入Y 。这个只需要执行一次;若启动失败的话,最好将hadoop目录夹重新解压一下,因为有一些目录会格式化导致踩坑 4 [root@HDmaster bin]# hdfs namenode -format 5 #启动所有进程的脚本 6 [root@HDmaster sbin]# pwd 7 /usr/local/hadoop/sbin 8 [root@HDmaster sbin]# ./start-all.sh
若安装配置成功,则可以看到以下jps信息:
在HDmaster上调用jps可以查看到 [root@HDmaster sbin]# jps 17847 NameNode 9080 Jps 18169 ResourceManager 18027 SecondaryNameNode 在HDslave1 和HDslave2 上调用jps可以查看到 [root@HDslave1 ~]# jps 30740 Jps 7643 DataNode 31237 NodeManager
五、启动过程中出现的错误以及解决办法
1 [root@HDmaster hadoop]# start-all.sh 2 This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh 3 Starting namenodes on [HDmaster] 4 HDmaster: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-HDmaster.out 5 HDslave1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-HDslave1.out 6 HDslave2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-HDslave2.out 7 Starting secondary namenodes [0.0.0.0] 8 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-HDmaster.out 9 starting yarn daemons 10 starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-root-resourcemanager-HDmaster.out 11 HDslave1: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-HDslave1.out 12 HDslave2: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-HDslave2.out 13 [root@HDmaster hadoop]# jps 14 10210 SecondaryNameNode 15 10358 ResourceManager 16 10639 Jps 17 [root@HDslave1 ~]# jps 18 31456 Jps 19 31140 DataNode 20 31237 NodeManager 21 #发现namenode没启动,那么查看一下日志,日志文件在启动过程中可以找到存放位置
[root@HDmaster ~]# more /usr/local/hadoop/logs/hadoop-root-namenode-HDmaster.log
#错误异常如下:无法分配请求地址(也就是我前面说到的不同网段的外网ip导致的)
java.net.BindException: Problem binding to [HDmaster:8020] java.net.BindException: Cannot assign requested address;
#解决办法:(注意只在HDmaster这一节点的配置文件将HDmater更改为localhost)
[root@HDmaster hadoop]# vim core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
#记得开启之后出错的话,需要先关闭server
[root@HDmaster hadoop]# stop-all.sh This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh Stopping namenodes on [localhost] localhost: no namenode to stop HDslave2: stopping datanode HDslave1: stopping datanode Stopping secondary namenodes [0.0.0.0] 0.0.0.0: stopping secondarynamenode stopping yarn daemons stopping resourcemanager HDslave1: stopping nodemanager HDslave2: stopping nodemanager HDslave1: nodemanager did not stop gracefully after 5 seconds: killing with kill -9 HDslave2: nodemanager did not stop gracefully after 5 seconds: killing with kill -9 no proxyserver to stop
#然后重新启动一下
[root@HDmaster hadoop]# start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [localhost] localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-HDmaster.out HDslave1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-HDslave1.out HDslave2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-HDslave2.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-HDmaster.out starting yarn daemons starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-root-resourcemanager-HDmaster.out HDslave2: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-HDslave2.out HDslave1: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-HDslave1.out
#然后namenode就出现了,启动终于正常了
[root@HDmaster hadoop]# jps 12889 SecondaryNameNode 13034 ResourceManager 13307 Jps 12701 NameNode [root@HDslave1 ~]# jps 32160 DataNode 32264 NodeManager 32447 Jps [root@HDslave2 ~]# jps 464 DataNode 578 NodeManager 783 Jps
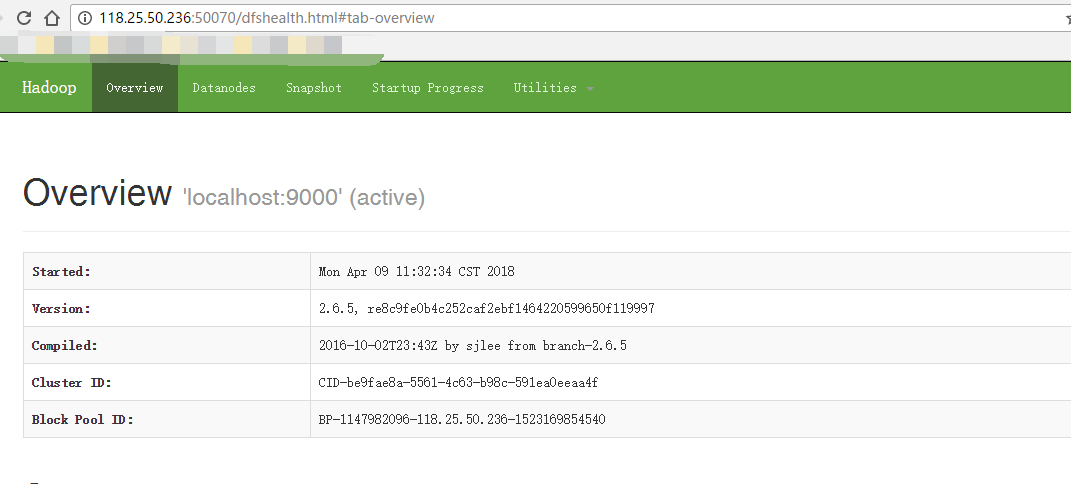
访问主节点的50070端口即可查看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号