Ubuntu 14.04 LTS 安装 spark 1.6.0 (伪分布式)-26号开始
需要下载的软件:
1.hadoop-2.6.4.tar.gz 下载网址:http://hadoop.apache.org/releases.html
2.scala-2.11.7.tgz 下载网址:http://www.scala-lang.org/
3.spark-1.6.0-bin-hadoop2.6.tgz 下载网址:http://spark.apache.org/
4.jdk-8u73-linux-x64.tar.gz 下载网址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Root用户的开启
为了简化Linux系统下的权限问题,我都是以root用户身份登陆和使用Ubuntu系统,而Ubuntu系统在默认情况下并没有开启root用户,我们需要开启root用户,我参考一下网址实现了root用户的开启:http://jingyan.baidu.com/article/27fa73268144f346f8271f83.html.
1.打开terminal终端(ctrl+Alt+T):
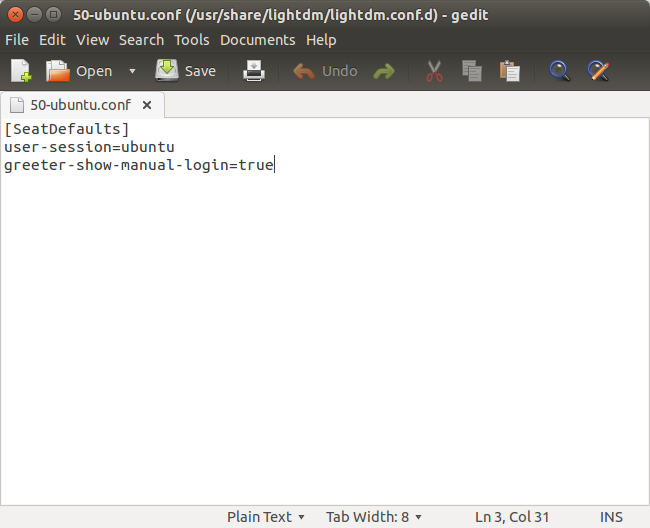
2.输入sudo gedit /usr/share/lightdm/lightdm.conf.d/50-ubuntu.conf 回车了之后,可能会提示输入密码,输入后会弹出如图示的编辑框。在编辑框中输入greeter-show-manual-login=true 保存关闭。
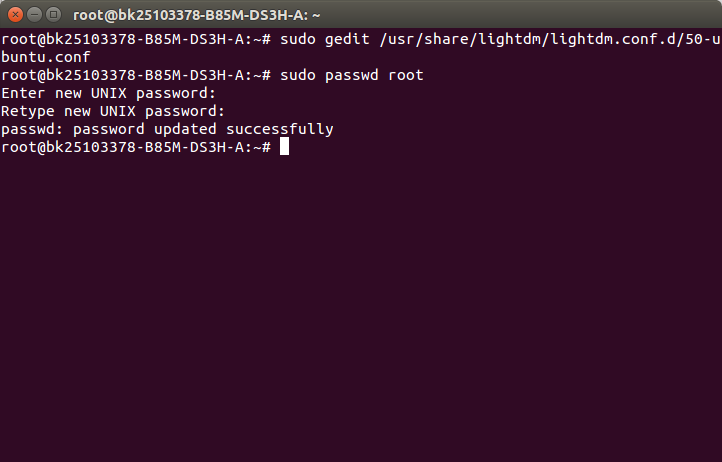
3.关闭之后,回到终端窗口,输入:sudo passwd root 回车;回车之后会要你输入两次密码,出现已成功更新密码字样即为成功。
4.然后关机重启之后,登陆的图形界面中,就可以输入root用户名和密码登陆了。
安装JAVA JDK
1.用root用户登陆后,cd到jdk下载存放的地方,利用tar -xf jdk-8u73-linux-x64.tar.gz进行解压,解压后利用剪切命令mv将jdk放到/usr/java目录下。
2.利用apt-get install vim命令安装vim文本编辑器,cd到/etc目录下,利用vim profile修改该文件加入JAVA的环境变量,打开profile文件后在最后添加如下文本:
export JAVA_HOME=/usr/java/jdk1.8.0_73 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
添加完成后,在terminal中输入source profile使得环境变量生效。
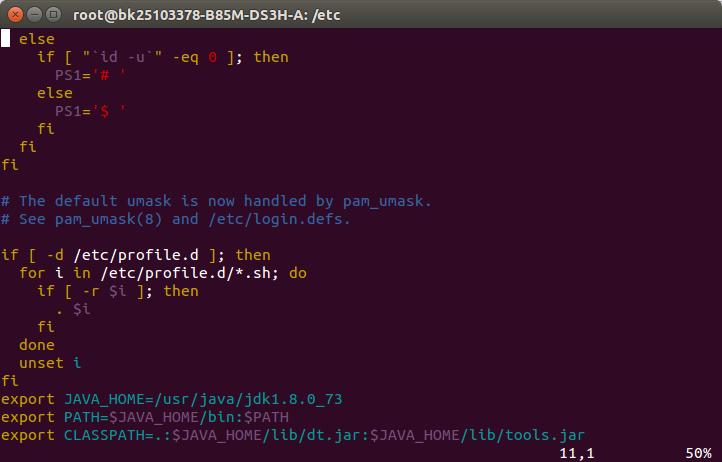
3.测试JAVA是否配置成功,在terminal中输入java -version如果出现如下信息即成功。

安装Hadoop
hadoop的安装主要参考官网上的伪分布式安装教程,参考网址:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
1.安装ssh和rsync,通过以下两个命令:
$ sudo apt-get install ssh $ sudo apt-get install rsync
2.cd到hadoop-2.6.4.tar.gz的下载目录,利用tar -xf 命令进行解压,将解压的文件夹利用mv命令剪切到目录/opt下,对于spark,scala都类似这样操作,不再累赘。
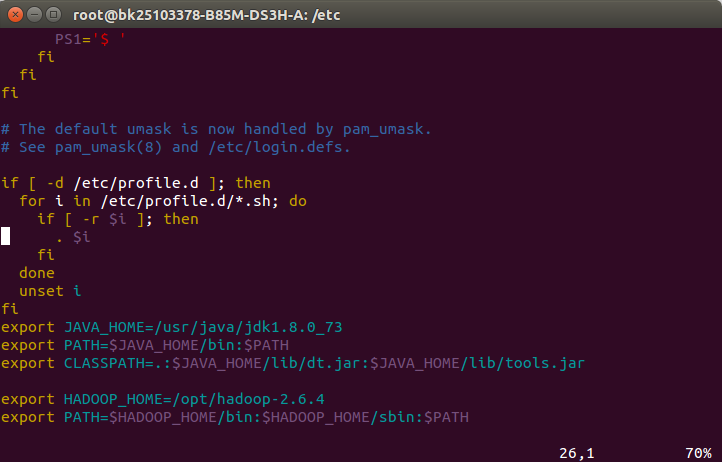
3.编辑文件/etc/profile,添加hadoop的环境变量,记得source profile
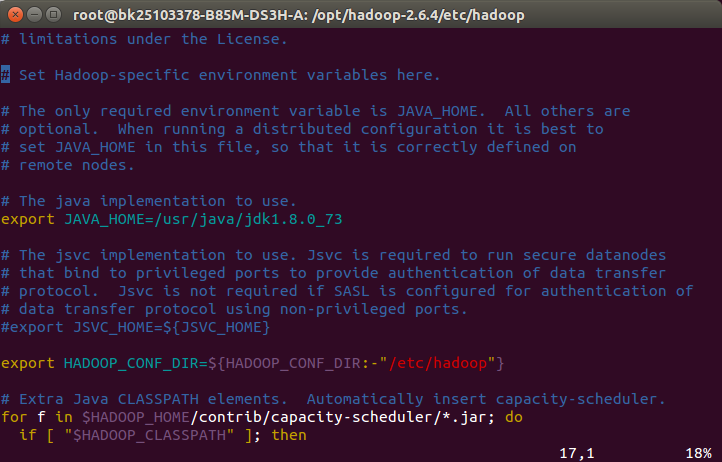
4.添加完hadoop环境变量后,cd到目录/opt/hadoop-2.6.4/etc/hadoop/,修改hadoop-env.sh文件,定义如下变量:
export JAVA_HOME=/usr/java/latest
5.伪分布式还需要修改etc/hadoop/core-site.xml文件为:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改etc/hadoop/hdfs-site.xml文件为:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
6.让ssh访问不受限制,需要如下设置,首先输入ssh localhost检查是否能不需要密码就能完成ssh localhost,如果不能需要如下生成秘钥:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
7.以上步骤完成后,hadoop的伪分布式就算完成了,然后就可以测试一下是否安装成功,可以查看网址http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html中的Execution部分。
安装Scala
安装scala比较容易,直接将解压后的scala-2.11.7文件夹放置在/opt目录下,然后修改etc/profile目录增加Scala所需环境变量就可以了。
1.vim etc/profile增加环境变量
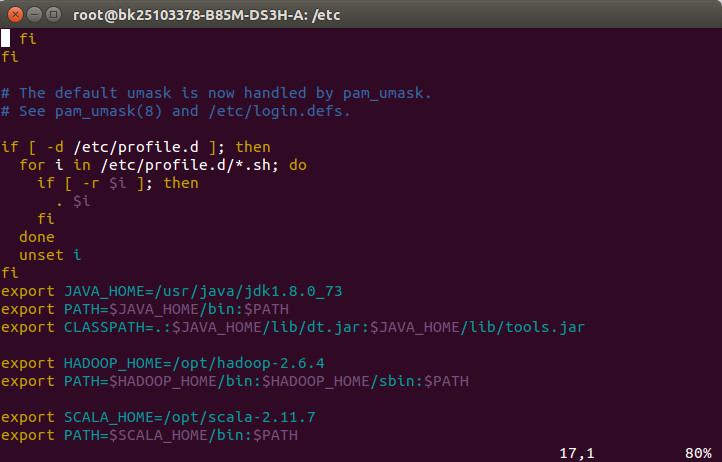
2.利用命令scala -version检查是否配置成功,如果出现如下信息就代表成功。
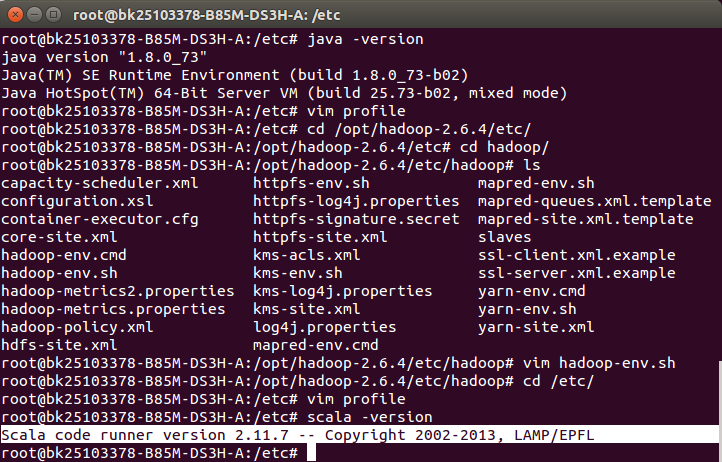
安装Spark
1.将下载好的spark用命令tar -xf进行解压后剪切mv到某目录下后,配置spark环境变量如下:
export SPARK_HOME=/opt/spark-1.6.0-bin-hadoop2.6 export PATH=$SPARK_HOME/bin:$PATH
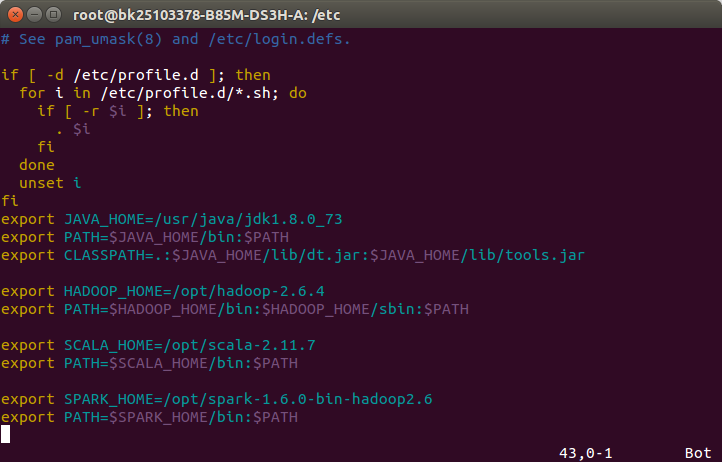
2.配置spark,参考网址:http://www.thebigdata.cn/Hadoop/28957.html,先修改spark-env.sh文件:
cp spark-env.sh.template spark-env.sh vim spark-env.sh
添加Spark的配置信息
export JAVA_HOME=/usr/java/jdk1.8.0_73 export SCALA_HOME=/opt/scala-2.11.7 export SPARK_MASTER_IP=bk25103378-B85M-DS3H-A #主机名 export SPARK_WORKER_CORES=2 export SPARK_WORKER_MEMORY=2g export HADOOP_CONF_DIR=/opt/hadoop-2.6.4/etc/hadoop
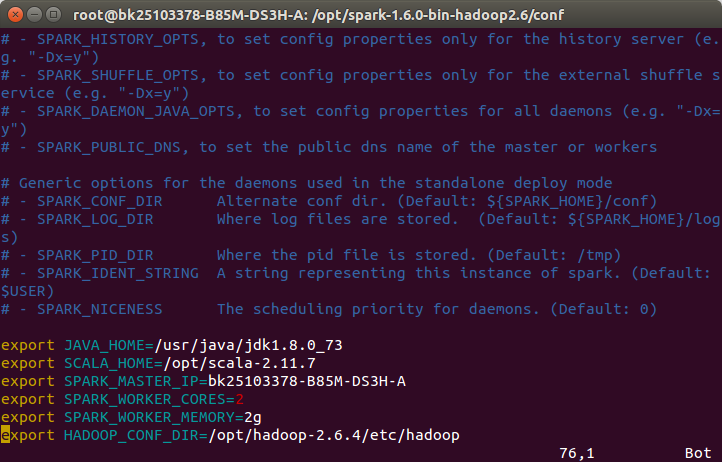
修改slaves文件:
cp slaves.template slaves vim slaves
添加节点:
127.0.1.1 bk25103378-B85M-DS3H-A
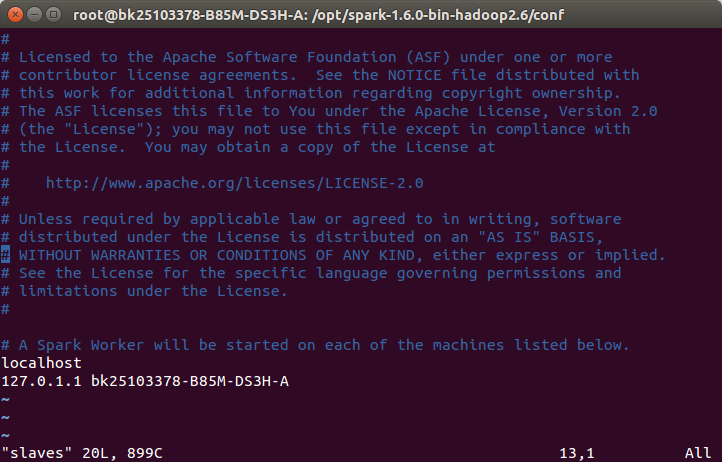
3.最后参考网址:http://www.thebigdata.cn/Hadoop/28957.html来启动spark检查是否配置成功即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号