「学习笔记」倍增思想与lca
「学习笔记」倍增思想与lca
点击查看目录
ST表
就是一个用倍增法求静态RMQ(区间最值)的算法。
预处理 \(O(n\log n)\),查询 \(O(1)\),远吊打其他算法。
算法
预处理
依次预处理出左端点为 \(l\),右端点为 \(l+2^j(1\le j\le \log_2(n))\) 的所有区间最小值,递推式为:
查询
比如说要查询 \([l,r]\) 这个区间。
我们令 \(k=\log_2(r-l+1)\ (2^{k}\le r-l+1\le 2^{k+1})\)。
那么这个区间的最小值就是 \(\min(d_{l,k},d_{r-2^k+1,k})\)
由于 \(2^{k}\le r-l+1\le 2^{k+1}\) ,所以这两个区间只会重合但不会超出去。
所以不用怕查询错误了。
关于 \(\log2\)
上面的讲述都围绕着一个东西 \(log_2(x)\),那么这个重要的东西怎么求呢?
其实很简单,我们使用 C++ 的 STL,直接写(int)(log(x)/log(2))就可以算出 \(log_2(x)\) 了。
Code
预处理
void pre_st(){
int ln=(int)(log(n)/log(2));
_for(i,1,n)d[i][0]=a[i];
_for(j,1,ln)
_for(i,1,n-(1<<j)+1)
d[i][j]=min(d[i][j-1],d[i+(1<<(j-1))][j-1]);
}
查询
int query(int l,int r){
int k=(int)(log(r-l+1)/log(2));
return min(d[l][k],d[r-(1<<k)+1][k]);
}
例题
P2880
板子题。
P2048
好题。
我们用 ST 表维护所有区间的最大前缀和,先算出所有以 \(l\) 为左端点时可以的右端点的区间 \([L,R]\) 和最优的右端点 \(t\),我们可以用一个堆来存储全局的最优区间。
但是我们不能只记录最优的右端点,还要找出分布在 \([L,t)\) 和 \((t,R]\) 的它次优的右端点,次次优的右端点……
那么我们就在每次取出当前最优区间的时候把 \([L,t)\) 和 \((t,R]\) 这两个区间的最优右端点也放入堆即可。
点击查看代码
#include <bits/stdc++.h>
#define _for(i,a,b) for(ll i=a;i<=b;++i)
#define for_(i,a,b) for(ll i=a;i>=b;--i)
#define ll long long
using namespace std;
const int N=1e6+10,inf=0x3f3f3f3f;
ll n,k,l,r,a[N],b[N],d[N][30],ans;
struct music{
ll le,rl,rr,t;
friend bool operator <(const music& aa,const music& bb){
return b[aa.t]-b[aa.le-1]<b[bb.t]-b[bb.le-1];
}
};
priority_queue<music>q;
inline ll rnt(){
ll x=0,w=1;char c=getchar();
while(c<'0'||c>'9'){if(c=='-')w=-1;c=getchar();}
while(c>='0'&&c<='9')x=(x<<3)+(x<<1)+(c^48),c=getchar();
return x*w;
}void pre_st(){
ll ln=(ll)(log(n)/log(2));
_for(i,1,n)d[i][0]=i;
_for(j,1,ln){
_for(i,1,n-(1<<j)+1){
ll x=d[i][j-1],y=d[i+(1<<(j-1))][j-1];
if(b[x]>b[y])d[i][j]=x;
else d[i][j]=y;
}
}
}ll query(ll l,ll r){
ll k=(ll)(log(r-l+1)/log(2));
if(b[d[l][k]]>b[d[r-(1<<k)+1][k]])return d[l][k];
else return d[r-(1<<k)+1][k];
}int main(){
n=rnt(),k=rnt(),l=rnt(),r=rnt();
_for(i,1,n)a[i]=rnt(),b[i]=b[i-1]+a[i];
pre_st();
_for(i,1,n+1-l)
q.push(music{i,i+l-1,min(n,i+r-1),query(i+l-1,min(n,i+r-1))});
_for(i,1,k){
music t=q.top();
q.pop();
ans+=b[t.t]-b[t.le-1];
if(t.t>t.rl)
q.push(music{t.le,t.rl,t.t-1,query(t.rl,t.t-1)});
if(t.t<t.rr)
q.push(music{t.le,t.t+1,t.rr,query(t.t+1,t.rr)});
}printf("%lld\n",ans);
return 0;
}
lca
即最近公共祖先。
这里先只讲三种简单的做法。
树上 RMQ
前置知识:欧拉序列
我们每到一个点就记录一下。比如这棵树:
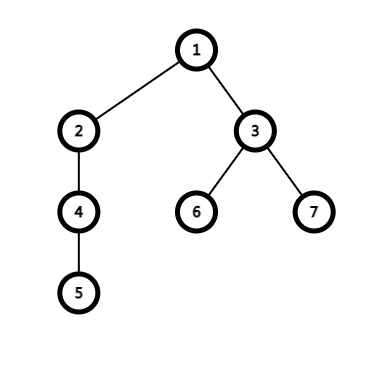
可以得到序列:
| dfs序 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 编号 | 1 | 2 | 4 | 5 | 4 | 2 | 1 | 3 | 6 | 7 | 3 | 1 |
| 层数 | 1 | 2 | 3 | 4 | 3 | 2 | 1 | 2 | 3 | 3 | 2 | 1 |
每个点第一次出现在:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|
| 1 | 2 | 8 | 3 | 4 | 9 | 10 |
算法
我们以上面的树为例,我们要查询 \(5\) 和 \(7\) 的 lca。
先找到 \(5\) 第一次出现在位置 \(4\),\(7\) 第一次出现在位置 \(10\)。
然后可以发现序列区间 \([4,10]\) 的最小的层数对应的点就是他们的 lca:\(1\)!
但这是为什么呢?
我们在正常 \(\text{dfs}\) 的过程中,要想从 \(u\) 遍历到 \(v\) 必然要经过它们的 \(\text{lca}\),也就说明它们的 \(\text{lca}\) 至少有两棵子树。
既然至少有两棵子树,就不可能遍历完一棵子树后先回到父亲再去遍历另一棵子树。
所以它们的 \(\text{lca}\) 一定是这个区间内层数最小的!
Code
void dfs(int u,int fa){
jl[u]=1;
c[u]=c[fa]+1;
dfn[++cnt]=u,q[u]=cnt;
int sz=tu[u].size();
_for(i,0,sz-1){
int v=tu[u][i].v;
if(jl[v])continue;
dfs(v,u);
dfn[++cnt]=u;
}
}void pre_st(){
int ln=(int)(log(cnt)/log(2));
_for(i,1,cnt)d[i][0]=dfn[i];
_for(j,1,ln)_for(i,1,cnt+1-(1<<j)){
if(c[d[i][j-1]]<c[d[i+(1<<(j-1))][j-1]])d[i][j]=d[i][j-1];
else d[i][j]=d[i+(1<<(j-1))][j-1];
}
}int query(int l,int r){
int k=(int)(log(r-l+1)/log(2));
if(c[d[l][k]]<c[d[r-(1<<k)+1][k]])return d[l][k];
return d[r-(1<<k)+1][k];
}
离线 Tarjan
算法
首先我们把所有查询都一股脑的给存进来。
对于一个节点 \(u\),我们都先把它当做自己的根,遍历它所有的子树,每个子树遍历完后把这棵子树的根设为 \(u\)。
在遍历某个节点的时候,如果它对应的查询点 \(v\) 被访问过,那么就查询 \(v\) 当前 的祖先 \(u\),这就是它们的 \(\text{lca}\)。
因为如果一个点对应的查询点被访问过,那么就一定是在 \(u\) 的另一棵子树上遍历的,既然不在一棵子树上但在同一个节点的子树们下,那么 \(u\) 就一定是它们的 \(\text{lca}\) 了!
具体实现,只用一个深搜就完成了。
Code
//tu是原来的树,t是每个点查询时对应的另一个点
void tarjan(int u){
v[u]=1;
int s1=tu[u].size(),s2=t[u].size();
_for(i,0,s1-1){
int vv=tu[u][i].v;
if(v[vv])continue;
tarjan(vv);
fa[vv]=u;
}_for(i,0,s2-1){
int vv=t[u][i].v;
if(v[vv])lca[t[u][i].w]=find(vv);
}
}
倍增
算法
我们先预处理出 \(u\) 的第 \(2^i\) 个祖先,递推式为:
即:\(u\) 的第 \(2^i\) 个祖先为 \(u\) 的第 \(2^{i-1}\) 个祖先的第 \(2^{i-1}\) 个祖先。
我们在查询时先让深度深的往上跳,直到跳到同一高度,然后再让两个点一起跳,跳到同一节点时,那个点就是它们的 \(\text{lca}\) 了。
总之:这是一个十分优雅的暴力。
Code
void dfs(int u,int last){
dep[u]=dep[last]+1;
fa[u][0]=last;
int sz=tu[u].size();
for(int i=1;(1<<i)<=dep[u];++i)
fa[u][i]=fa[fa[u][i-1]][i-1];
_for(i,0,sz-1)
if(tu[u][i]!=last)dfs(tu[u][i],u);
}int lca(int x,int y){
if(dep[x]<dep[y])swap(x,y);
while(dep[x]!=dep[y])
x=fa[x][lg[dep[x]-dep[y]]-1];
if(x==y)return x;
for_(i,lg[dep[x]],0)
if(fa[x][i]!=fa[y][i])
x=fa[x][i],y=fa[y][i];
return fa[x][0];
}
对比
| 算法 | 查询复杂度 | 代码长度 | 能否维护附加信息 | 维护附加信息代码长短 |
|---|---|---|---|---|
| 树上 RMQ | \(O(1)\) | 较长 | 否 | \ |
| 离线 Tarjan | \(O(n)\) (全部询问) | 简短 | 能 | 长 |
| 倍增 | \(O(logn)\) | 简短 | 能 | 短 |
例题
P3379
板子题。
P2912
对于每个节点 \(u\),我们维护一下它到根节点的路径权值和 \(sum(u)\)。
在找出 \(u\) 和 \(v\) 的 \(\text{lca}\) 后,它们的路径权值和就是:
点击查看核心代码
用 \(\text{tarjan}\) 做的。
void pre(){
_for(i,1,n)fa[i]=i;
}int find(int x){
if(fa[x]==x)return x;
return fa[x]=find(fa[x]);
}void tarjan(int u,int w,int f){
sum[u]=sum[f]+w;
v[u]=1;
int s1=tu[u].size(),s2=t[u].size();
_for(i,0,s1-1){
int vv=tu[u][i].v,ww=tu[u][i].w;
if(v[vv])continue;
tarjan(vv,ww,u);
fa[vv]=u;
}_for(i,0,s2-1){
int vv=t[u][i].v;
if(v[vv])lca[t[u][i].w]=find(vv);
}
}
P2245
好题。
首先我们要做一个最小生成树,来尽量降低危险值。
但难点在于:如何去维护路径最小值?
我们选择用倍增做,因为我们在递推 \(u\) 的第 \(2^i\) 个祖先的时候可以顺便递推出\(u\) 与第 \(2^i\) 个祖先的路径上的最小值。
我们在查询 \(u\rightarrow v\) 的最小值时,答案就应该"是 \(u\) 到 \(\text{lca}\) 的最小值"和"\(v\) 到 \(\text{lca}\) 的最小值"两者中的最小值
点击查看全部代码
#include <bits/stdc++.h>
#define _for(i,a,b) for(ll i=a;i<=b;++i)
#define for_(i,a,b) for(ll i=a;i>=b;--i)
#define ll long long
using namespace std;
const int N=3e5+10,inf=0x3f3f3f3f;
int n,m,q;
struct bian{int u,v,w;}b[N];
struct tree{int v,w;};
vector<tree>tr[N];
inline int rnt(){
int x=0,w=1;char c=getchar();
while(c<'0'||c>'9'){if(c=='-')w=-1;c=getchar();}
while(c>='0'&&c<='9')x=(x<<3)+(x<<1)+(c^48),c=getchar();
return x*w;
}bool cmp(bian a,bian b){
return a.w<b.w;
}struct Kru{
int fa[N];
void pre(){
_for(i,1,n)fa[i]=i;
}int find(int u){
if(fa[u]==u)return u;
return fa[u]=find(fa[u]);
}void kru(){
int k=0;
pre();
sort(b+1,b+m+1,cmp);
_for(i,1,m){
int u=b[i].u,v=b[i].v,w=b[i].w;
if(find(u)!=find(v)){
++k;
fa[find(u)]=find(v);
tr[u].push_back(tree{v,w});
tr[v].push_back(tree{u,w});
}if(k==n-1)break;
}
}
}Kru;
struct Lca{
int f[N][30],d[N][30],jl[N],c[N],z[N],root[N];
void dfs(int u,int w,int fa,int r){
jl[u]=1;
c[u]=c[fa]+1;
z[u]=w;
root[u]=r;
f[u][0]=fa,d[u][0]=w;
for(int i=1;(1<<i)<=c[u];++i){
f[u][i]=f[f[u][i-1]][i-1];
d[u][i]=max(d[f[u][i-1]][i-1],d[u][i-1]);
}
int sz=tr[u].size();
_for(i,0,sz-1)if(!jl[tr[u][i].v])dfs(tr[u][i].v,tr[u][i].w,u,r);
}inline int lca(int u,int v){
if(c[u]<c[v])swap(u,v);
int mx=0;
if(root[u]!=root[v])return 0;
if(c[u]!=c[v]){
for_(i,20,0)
if(c[f[u][i]]>=c[v])
mx=max(mx,d[u][i]),u=f[u][i];
}if(u==v)return mx;
for_(i,20,0){
if(f[u][i]!=f[v][i]){
mx=max(mx,max(d[u][i],d[v][i]));
u=f[u][i],v=f[v][i];
}
}mx=max(mx,max(d[u][0],d[v][0]));
return mx;
}
}Lca;
int main(){
n=rnt(),m=rnt();
_for(i,1,m)b[i].u=rnt(),b[i].v=rnt(),b[i].w=rnt();
Kru.kru();
_for(i,1,n)if(!Lca.jl[i])Lca.dfs(i,0,0,i);
q=rnt();
while(q--){
int x=rnt(),y=rnt();
int qwq=Lca.lca(x,y);
if(qwq)printf("%d\n",qwq);
else printf("impossible\n");
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号