编译原理复习
华南师范大学2023年编译原理复习提纲
第一章
程序语言的分类
- 高级语言和低级语言:
- 高级语言:面向过程、面向对象
- 低级语言:机器语言和汇编语言
程序翻译方式及不同
- 编译型语言和解释型语言:
- 编译语言:需要事先安装编译程序,通过产生目标程序来进行执行
- 解释语言:逐句进行翻译,不产生目标程序
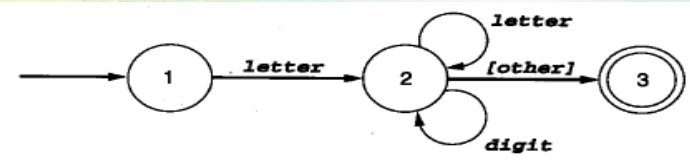
编译程序包含阶段及各部分任务
- 词法分析:输入源程序,对构成程序的字符串进行扫描分析,识别单个词
- 语法分析:在词法分析基础上,根据语言的语法规则,将单词符号串分解为各类语法单位(单词、句子、程序段和程序等)
- 词义分析:对语法分析识别出的各类语法单位分析含义
- 优化:对之前的中间代码进行加工变换,在最后阶段产生高效的目标代码
- 目标代码生成:把中间代码变成特定机器上的低级语言代码
第二章
正则表达式运算以及构建方法
-
表示方法:
通过书写\(L(a)=\{a\}\)来匹配a字符,而a为字母表中元素,表示为\(\Sigma=\{a\}\)
-
基本符号:
- 选择(
|) - 连接(不使用元字符)
- 闭包(\(a^*\))
- 选择(
-
基本方法导致的缺陷:
- 不能表示\(S=\{b,aba,aabaa,...\}=\{a^nba^n|n\geq 0\}\)
- 书写繁琐
-
简化正则表达式:
- 正闭包(\(r^+\))
- 字符范围:
[a-zA-Z]表示所有大小写字母 - 可选(
?) - 任意字符(
.) - 非字符(
~)
-
二义性问题:采取最长字串匹配原则
-
正则表达式缺点:抽象、不利于代码编写
正则表达式\(\to NFA\to DFA\to DFA\)最小化
-
向量机基本构成:状态、初态、终态、转换(和接受状态)
-
DFA定义:M由字母表\(\Sigma\)、状态集合S,转换函数T: \(S\times\Sigma\to S\)、初始状态\(S_0\in S\)及接受状态集合\(S\subset S\)组成。
-
NFA不同于DFA的地方:允许\(\epsilon\)转换和一对多的转换
-
正则表达式转NFA(
Thompson方法)龙书PDF页码:P99-101
-
基本正则表达式的NFA:
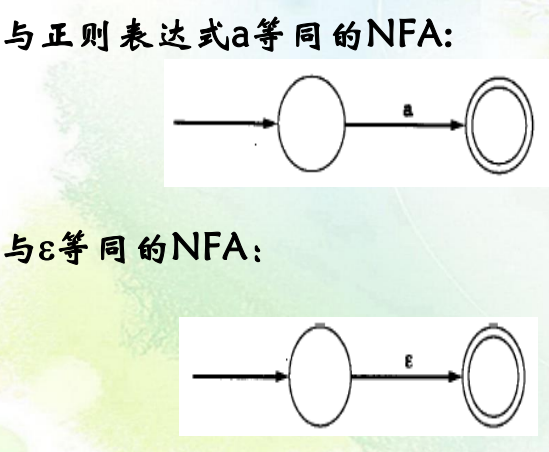
-
连接:
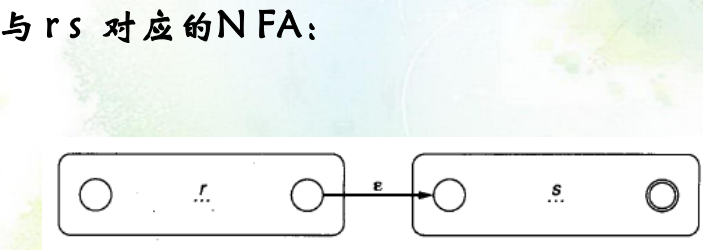
-
选择:
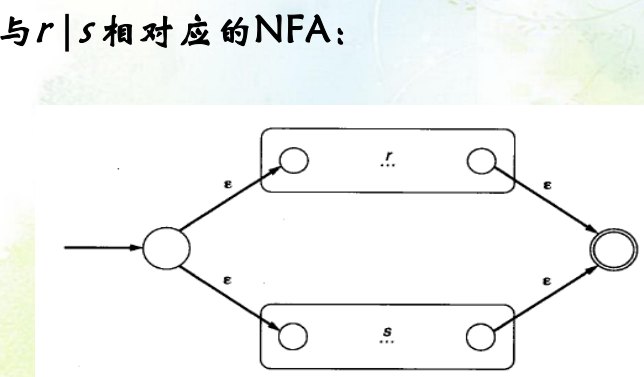
-
重复:
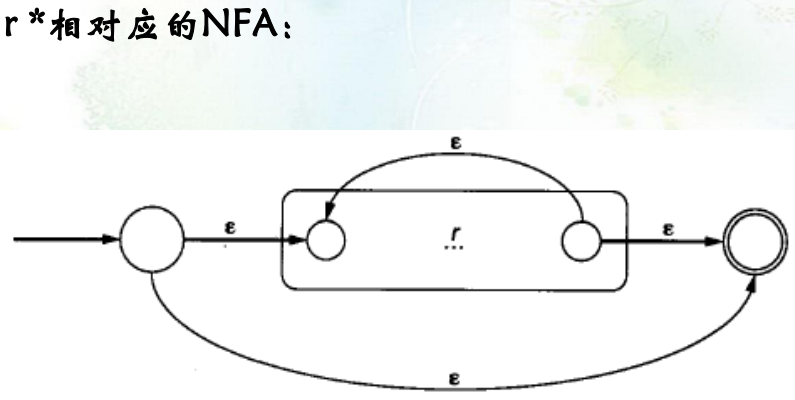
-
-
NFA转DFA过程(最重要部分之一)
-
消除\(\epsilon\)转换:
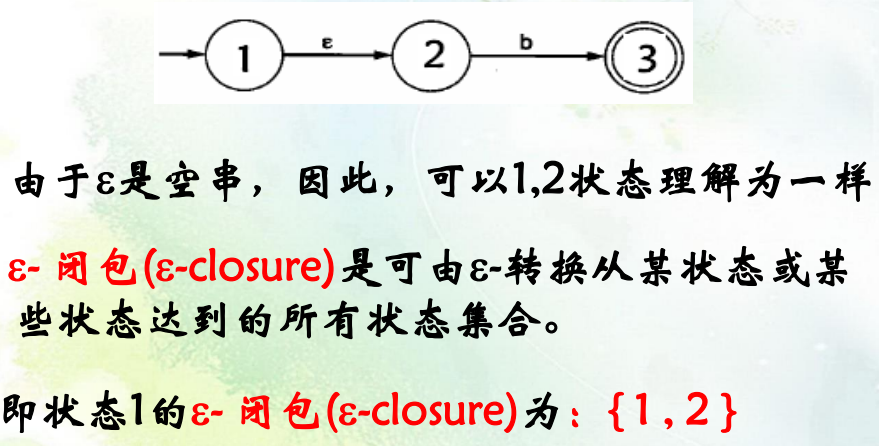
-
消除多重转换:
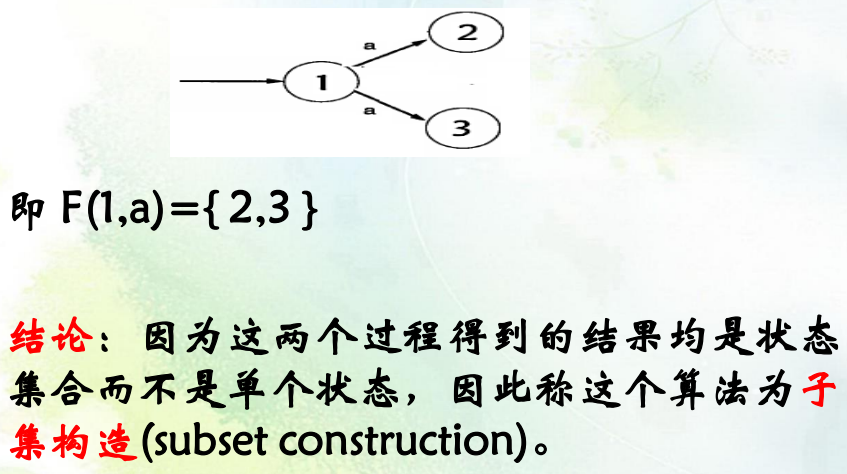
实现上述的两个转换要求我们必须掌握下面转换这几张图的思路:
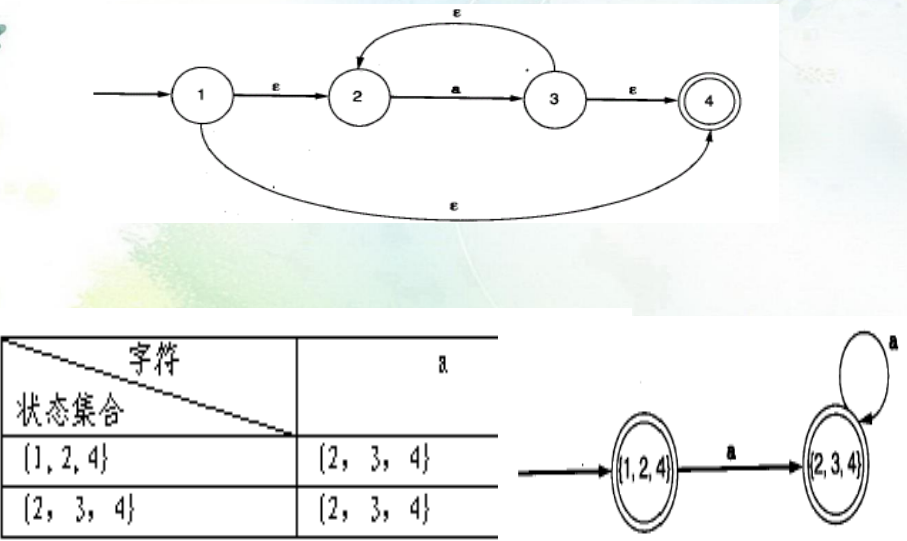
龙书思路(PDF P97):
-
输入:NFA N
-
输出:DFA D
-
方法:为D构造转换表
Dtran,DFA的每个状态是NFA的状态集合,D将“并行”地模拟N对输入串的所有可能移动操作 描述 \(\epsilon-closure(s)\) 从NFA状态s只经过\(\epsilon\)转换可以到达的NFA状态集 \(\epsilon-closure(T)\) 从T中的状态只经过\(\epsilon\)转换可以到达的NFA状态集 \(move(T,\alpha)\) 从T中的状态s经过输入符号\(\alpha\)上的转换可以到达的NFA状态集 使用上表来记录NFA的状态轨迹(s代表NFA的状态,T代表NFA的状态集合)


//数据结构 struct DFA{ map<int, map<char, int>> G;//图 unordered_set<int> end;//结束状态集合 bool match(const string &s,char (*type)(char c)){ int now = 0; for (auto &i: s){ char c = type(i); if (G[now].count(c)) now = G[now][c]; else return false; } return end.count(now); } }; struct DStat{ set<int> stats; int id; bool operator<(const DStat &d) const{ return stats < d.stats; } bool operator==(const DStat &d) const{ return stats == d.stats; } }; void Lex::buildDFA(){ vector<DStat> Dstats; Dstats.emplace_back(e_closure(nfa.start)); set<DStat> vis; vis.insert(Dstats[0]); for (int i = 0; i < Dstats.size(); ++i){ for (auto c: inputSet){ if (c == '$') continue; auto U = e_closure(move(Dstats[i], c)); if (U.stats.empty()) continue; if (vis.find(U) == vis.end()){ Dstats.emplace_back(U); if (U.stats.find(nfa.end) != U.stats.end()) dfa.end.insert(std::find(Dstats.begin(), Dstats.end(), U) - Dstats.begin());//U在DStat中的下标 vis.insert(U); } dfa.G[i][c] = std::find(Dstats.begin(), Dstats.end(), U) - Dstats.begin();//U在DStat中的下标 } } } Lex::DStat Lex::e_closure(int s){ DStat stat; stat.stats.insert(s); stack<int> stk; stk.emplace(s); stat.stats.insert(s); while (!stk.empty()){ int i = stk.top(); stk.pop(); for (auto &v: nfa[i]['$']){ if (stat.stats.find(v) != stat.stats.end()) continue; stk.emplace(v); stat.stats.insert(v); } } return stat; } Lex::DStat Lex::e_closure(Lex::DStat T){//这里实现和伪代码不太一样,我直接对多个e_closure(s)取并了 DStat stat; for (auto &i: T.stats){ auto tmp = e_closure(i); for (auto &v: tmp.stats) stat.stats.insert(v); } return stat; } Lex::DStat Lex::move(const Lex::DStat &T, char a){ DStat stat; for (auto &i: T.stats) if (nfa[i].find(a) != nfa[i].end()) for (auto &v: nfa[i][a]){ if (stat.stats.find(v) == stat.stats.end()){ stat.stats.insert(v); } } return stat; }
-
-
进行DFA最小化处理:
-
思路:目标一致的进行合并
-
两种方法:
-
逐个状态进行分析比较进行合并
-
从终态和非终态进行逐渐拆分,下述例子:
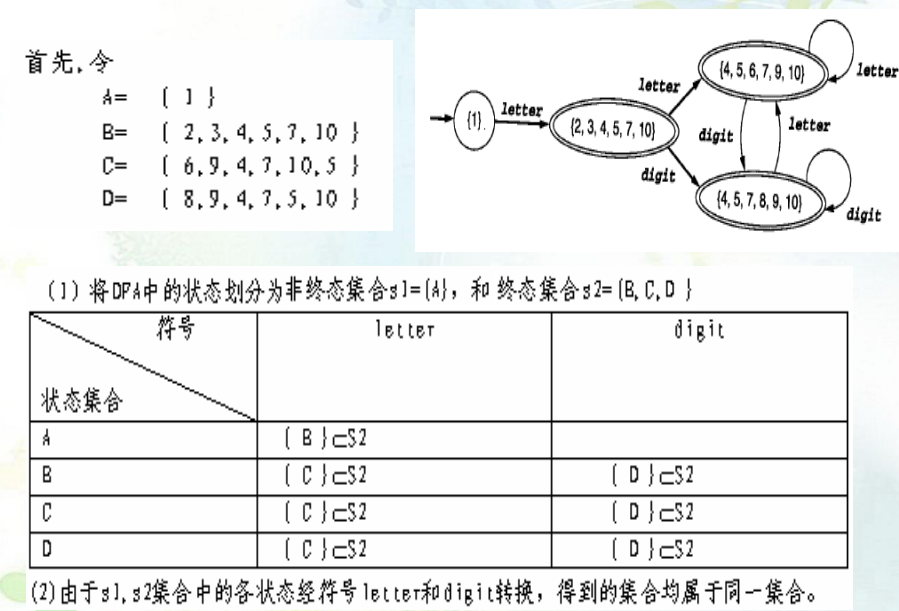
-
-
实现算法:龙书(P112)


-
-
词法分析程序的生成方法
- 最基本的方式(下述代码与上述代码无关联):
//要求生成类似下述的代码
bool matchDFA(){
int state=1;
string s=getToken();
if(letter.count(s)) state=2;
else return false;
s=getToken();
if(!letter.count(s)) return false;
while(letter.count(s)||isDigit(s)){
s=getToken();
}
state=3;
if(state==3) return true;
return false;
}
-
基本方法的特点:适合状态少循环小的DFA,但是任何一项不满足要求都会导致生成代码复杂
-
解决方法:
-
状态转换方法:
bool matchDFA(){ int state=1; string s=getToken(); while((state==1||state==2)&&(pos<s.length())){ switch(state){ case 1:{ if(!letter.count(s)) return false; state=2; break; } case 2:{ if(!letter.count(s)&&isDigit(s)) state=3; else s=getToken(); break; } } } if(state==3) return true; return false; } -
二维数组:
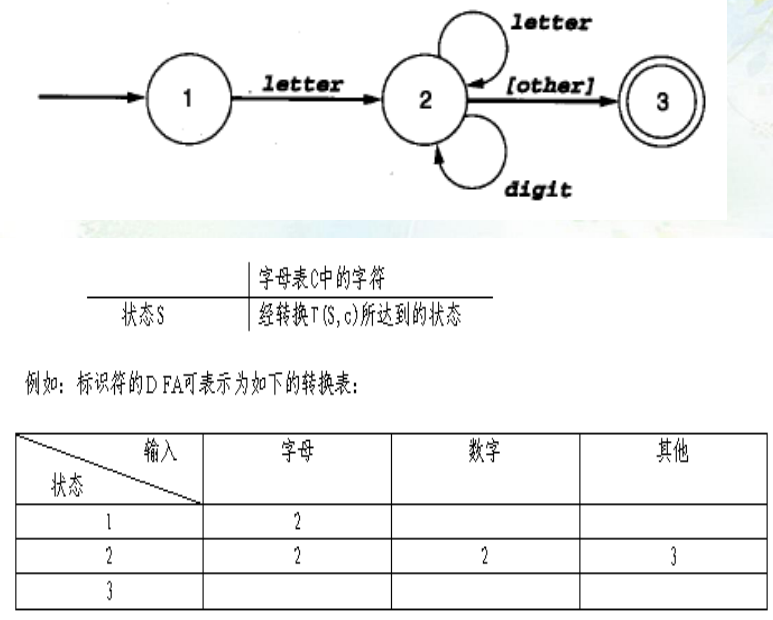
-
第三章
文法、语言及文法分类
-
文法
- 定义:反映句子组成成分的规则(分析方法分为[最左]推导和[最右]归约)
- 上下无关文法(BNF文法):
- 形式化定义:\(G=(V_T,V_N,P,S)\)。其中,\(V_T\)为终结符集合,\(V_N\)为非终结符集合,\(P\)为产生式集合,\(S\)为文法开始符号
- 基本符号:选择(
|)、连接、空串(\(\epsilon\))和括号(其中正则闭包使用递归文法实现) - 习惯用法:使用大写字母表示非终结符(或者用尖括号括起非终结符),使用小写字母表示终结符号
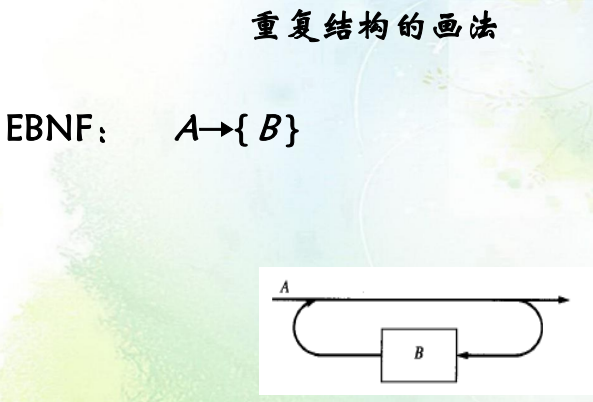
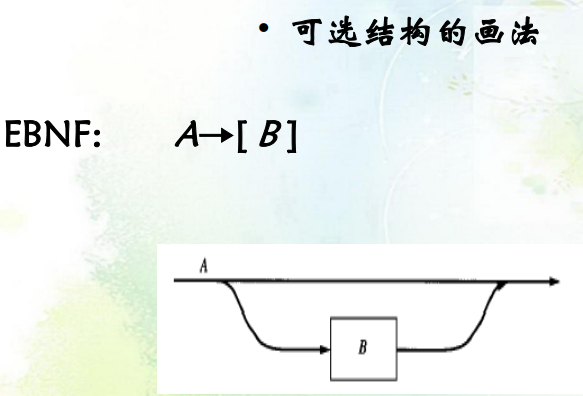
- 扩展(EBNF):重复(
{重复部分})、可选([可选部分])
- Chomsky分类方法【四类文法逐级包含(0型为最大集合)】:
- 0型文法(递归可枚举语言)
- 1型文法(上下有关文法):产生式右边不含文法开始符号
- 2型文法(上下无关文法)
- 3型文法(正则文法):只允许形如\(A\to aB,A\to Ba\)和\(A\to a\)规则
- 两种存储结构:
- 数组:【左部符号(使用序号代替,方便操作)|右部符号串|右部长度】
- 链表:【规则左部符号|下一规则指针|右部符号指针】
-
语言:一切句子的集合
推导、归约、语法树
-
语法树:
-
绘制语法树存在两种方式:自底而上(归约)和自顶向下(推导)
-
初始存储结构(分析树):【节点序号|文法符号序号|父节点序号|左兄弟节点序号|右子节点序号】
-
压缩语法树:
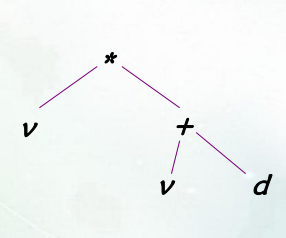
//算术表达式对应的C语言描述 typedef enum{Plus,Minus,Times,Division}OpKind; typedef enum{OpKind,ConstKind,VarKind}ExpKinnd; typedef struct streenode{ ExpKind kind; OpKind op; struct streenode *lchild,*rchild; int val; char varname[20]; }STreeNode; typedef STreeNode *SyntaxTree;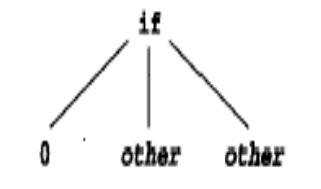
//if语句的语法树结构 typedef enum{ExpK,StmtK}NodeKind; typedef enum{Zero,One}ExpKind; typedef enum{IfK,OtherK}stmtKind; typedef struct streenode{ NodeKind kind; ExpKind ekind; StmtKind skind; struct streenode *test,*thenpart,*elsepart; }STreeNode; typedef STreeNode *SyntaxTree;
-
文法的二义性及消除方法
- 二义性判定问题:二义性问题是不可判定的,即不存在解决该问题的算法
- 消除二义性的问题:没有消除文法二义性的通用方法,只能针对常见文法进行操作
- 一些消除二义性的方式:
- 设置一个限制规则,在分析程序中实现(如:else要与最近的上一个未被匹配的if匹配)
- 改造文法
- 重新设计书写语法(如:代码中else部分必须出现)
第三章重点部分
文法构建问题
-
文法有效性
- 有害规则:导致二义性的规则
- 多余规则:不可到达或不可终止的规则
-
自顶而下的语法分析问题
-
左公因子:
- 面临问题:
- 同一非终结符规则右边存在多条规则且最左边符号相同
- 同一非终结符右边存在多条规则且经多步推导后,最左符号相同
- 解决方法:提取左公因子、求\(First(X)\)的集合元素
- 面临问题:
-
左递归:
-
面临问题:无法直接求出\(First\)集合元素
-
解决问题:
-
使用\(EBNF\)中的花括号
{...}表示重复 -
改写为右递归:
\(A\to Aa|b\)(左递归)
\(A\to bA'\)
\(A'\to aA'|\epsilon\)
-
间接左递归解决思路:
- 逐个非终结符进行解决
- 将干净非终结符带入未解决的非终结符中,并将其消除干净
- 反复进行
-
-
-
First与Follow集合
-
First集合求解方法(形同First(X)):
-
如果X是终结符,则FIRST(X)是
-
如果\(X\to\epsilon\)是一个产生式,则将\(\epsilon\)加入FIRST(X)中
-
如果X是非终结符,且\(X\to Y_1Y_2...Y_k\)是一个产生式,则:
a) \(FIRST(Y_1)\)中的所有符号在\(FIRST(X)\)中
b) 若对于某个\(i,a\)属于\(FIRST(Y_i)\)且\(\epsilon\)属于\(FIRST(Y_i),...,FIRST(Y_{i-1})\),即\(Y_1...Y_{i-1}\stackrel{*}{\Rightarrow}\epsilon\),则将a加入FIRST(X)中
c) 若对于所有的\(j=1,2,...,k,\epsilon\)在\(FIRST(Y_i)\)中,则将\(\epsilon\)加到FIRST(X)中
-
//计算First集合
void Grammar::makeFirst() {
//求所有非终结符的first集合
bool isChange = true;//是否需要继续迭代
while (isChange) {
isChange = false;
for (auto p : m) {
string key = p.first;//产生式左边 即非终结符号
vector<vector<string>> values = p.second;//对应右边的多条式子
for (auto value : values) {
int k;
for (k = 0; k < value.size(); k++) {
set<string> first_set_k = get_first(value[k]);
for (auto s : first_set_k) {
//first集合没找到
if ((s != "@") && (m_first[key]).find(s) == m_first[key].end()) {
m_first[key].insert(s);
isChange = true;//发生变化
}
}
if (first_set_k.find("@") == first_set_k.end())
break;
}
if (k == value.size() && (m_first[key]).find("@") == m_first[key].end()) {//含@
this->m_first[key].insert("@");
isChange = true;
}
}
}
}
}
- \(Follow\)集合求解方法:为计算所有非终结符\(A\)的后继符号集合\(FOLLOW(A)\),我们可以应用如下规则,直到每个\(FOLLOW\)集合都不能再加入任何符号或
$为止:- 将
$放入\(FOLLOW(S)\)中,其中\(S\)是开始符号,$是输入串的结束符 - 如果存在产生式\(A\to\alpha B\beta\),则将\(FIRST(\beta)\)除\(\epsilon\)以外的符号都放入\(FOLLOW(B)\)中
- 如果存在产生式\(A\to\alpha B\)或\(A\to\alpha B\beta\),其中\(FIRST(\beta)\)中包含\(\epsilon\)(即\(\beta\stackrel{*}{\Rightarrow}\epsilon\)),则将\(FOLLOW(A)\)中的所有符号都放入\(FOLLOW(B)\)中
- 将
//计算Follow集合
void Grammar::makeFollow() {
//初始化
for (auto nt : ntSet)
m_follow[nt] = set<string>();
m_follow[start].insert("$");
bool isChange = true;
while (isChange) {
isChange = false;
for (auto p : m) {//遍历每一个产生式p
string key = p.first;
vector<vector<string>> values = p.second;
for (auto value : values) {
//遍历value中每一个非终结符
for (auto it = value.begin(); it != value.end(); it++) {
if (ntSet.find(*it) != ntSet.end()) {
//特殊情况------非总结符号在生成式最后
if (it + 1 == value.end()) {
for (auto x : get_follow(key)) {//求生成式左侧的follow集合
//将Follow集合没有的加入
if (m_follow[*it].find(x) == m_follow[*it].end()) {
m_follow[*it].insert(x);
isChange = true;
}
}
}
else {
//求后面个符号的first
set<string> first_set = first(vector<string>(it + 1, value.end()));
for (auto x : first_set) {
if ((m_follow[*it].find(x) == m_follow[*it].end()) && x != "@") {
m_follow[*it].insert(x);
isChange=true;
}
}
//如果含有空符号 此情况类似非总结符号在生成式最后
if (first_set.find("@") != first_set.end()) {
m_follow[*it].erase("@");
for (auto x : get_follow(key)) {
if (m_follow[*it].find(x) == m_follow[*it].end()) {
m_follow[*it].insert(x);
isChange = true;
}
}
}
}
}
}
}
}
}
}
第四章
语法分析方法
- 带回溯的自顶向下分析方法
- 定义:不确定是指某个非终结符有多条规则,而面临当前输入符无法唯一确定选用哪条规则进行推导,只好逐个试探。
- 存在问题:
- 效率问题:回溯、规则选择效率
- 左递归问题:左递归存在使自顶向下分析过程存在死递归
- 无回溯的自顶向下分析方法
- 应用条件:
- 无左递归性
- 无回溯性
- 应用条件:
- 预测性自顶向下分析方法:
- 递归下降分析法
- LL(1)分析方法
第四章重点
递归下降分析法
-
基本方法:
对每个非终结符按其规则结构产生相应语法分析子程序(函数),终结符使用匹配命令,非终结符使用调用命令。(递归子程序法)
-
语法图:
箭头:表示序列和选择的
终结符:圆形框和椭圆形框
非终结符:方形框和矩形框
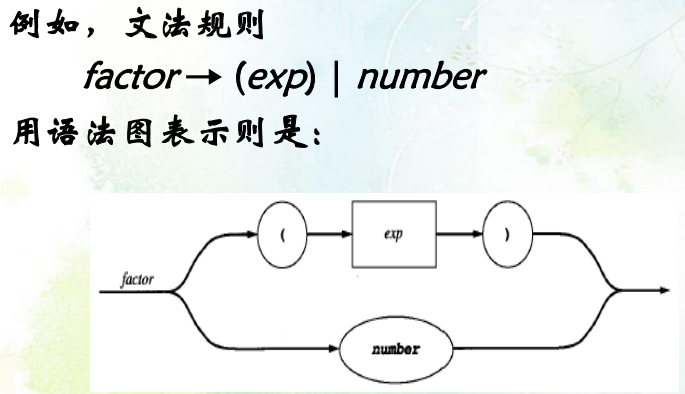
具体参见:
./编译原理/讲稿/chap04/page=24 -
程序设计基本方法:
- 每个非终结符对应一个函数,每遇到一个非终结符,调用此函数
- 每个终结符使用匹配函数进行处理
- 函数
getToken()负责读入下一个TOKEN单词 - 函数
ERROR()负责报告错误 - 函数
match()进行终结符号的匹配处理 - 全局变量
TOKEN存放已经读入的TOKEN单词
具体参见:
./编译原理/讲稿/chap04/page=29 -
程序设计实现的代码范式:
-
match函数:void match(string &expectedToken){ int ErrorNO=ErrTable(expectedToken); //将匹配内容转化为错误号 if(TOKEN==expectedToken) getToken(); else ERROR(ErrorNO); } -
ERROR函数:void ERROR(int ErrorNO){ switch(ErrorNO){ case 1:cerr<<"{错误信息1}"<<endl;break; case 2:cerr<<"{错误信息2}"<<endl;break; ... } } -
main函数:int main(){ getToken(); S(); //文法开始符号 return 0; }
-
-
消除问题:
-
左公因子项:
/* if-stmt->if(exp) statement|if(exp) statement else statement 普通方法转化为:if-stmt->if(exp) statement (Epsilon|else statement) EBNF转化为:if-stmt->if(exp) statement [else statement] */ void ifStmt(){ match("if"); match("("); exp(); match(")"); statement(); //可选内容部分 if(TOKEN=="else"){ match("else"); statement(); } } -
左递归项:
/* exp->exp (+|-) term|term EBNF转化为:exp->term {(+|-) term} */ void exp(){ term(); while((TOKEN=="+")||(TOKEN=="-")){ match(TOKEN); //为+或者- term(); } }
具体实现的功能添加参见:
- 计算功能:
./编译原理/讲稿/chap04/page=56 - 语法树:
./编译原理/讲稿/chap04/page=69 - 汇编指令:
./编译原理/讲稿/chap04/page=78
-
-
出现问题:
- EBNF导致编写困难
- 出现\(A\to\epsilon\)难以书写
- 产生式右部首位含多个非终结符导致选择规则困难
- 存在死递归情况
- 存在左公因子情况
LL(1)分析法
-
LL(1)分析表
G[S]={ S->Ab|Bc A->aA|dB B->c|e } First(S)={a,c,d,e} First(A)={a,d} First(B)={c,e}利用\(First\)集合进行构造分析表:
a b c d e S S->AbS->BcS->AbS->BcA A->aAA->dBB B->cB->e -
LL(1)判断方法
- 不含有左公因子
- 对每个有规则\(A\to\epsilon\)的非终结符,要求\(First(A)\)与\(Follow(A)\)交集为空
-
二义性消除新方法:
具体内容参见
./编译原理/讲稿/chap04/page=111
-
LL(1)分析过程
利用上述表的文法分析串
adcb步骤 符号栈 输入串 动作 1 SadcbS->Ab2 bAadcbA->aA3 bAaadcb匹配a 4 bAdcbA->dB5 bBddcb匹配d 6 bBcbB->c7 bccb匹配c 8 bb匹配b 9 成功 基本过程框架为:
- 初始化:文法开始符号入栈
- 查表
- 替换
- 反复2和3的步骤,直到分析成功或失败
第五章
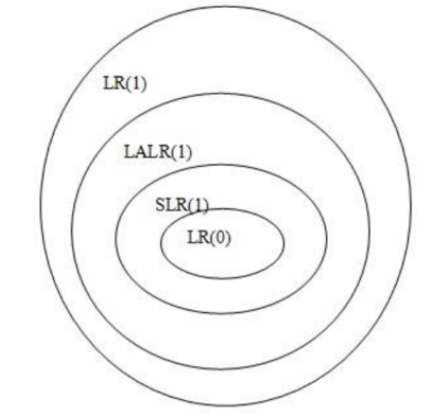
LR(0)DFA、LR(1)DFA、LALR(1)
-
简述概念:L指从左向右扫描输入符号串,R指构造最右推导的逆过程(归约大概是)
-
LR(0)项DFA
-
存储结构:邻接矩阵、邻接表和新二维表存储(LR(0)分析表)
-
值得注意的是,SLR(1)分析还是使用LR(0)项目集DFA
-
发生移进归约冲突情况:
也就是说存在移进-归约冲突、归约-归约冲突时都不满足(因为看不到Follow集合元素)
\(E'\to E\)
\(E\to E+n|n\)
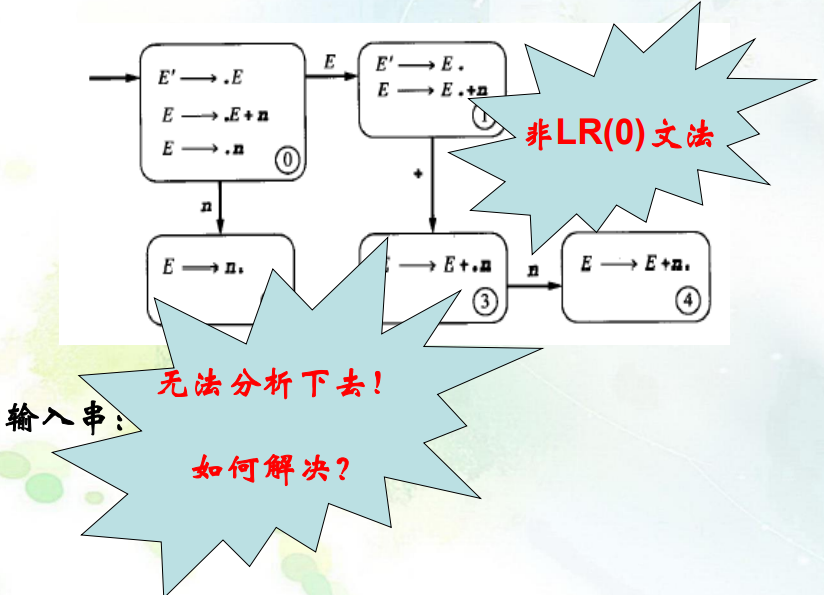
-
分析表:
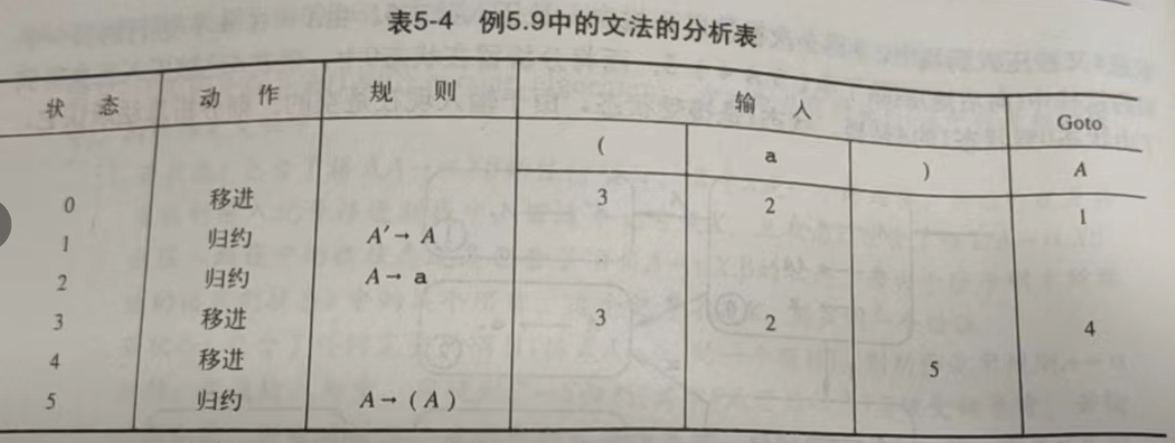
-
-
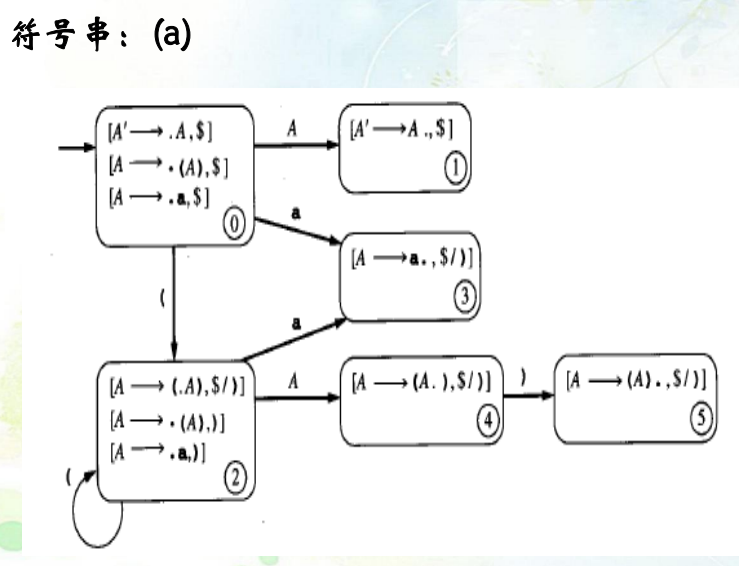
LR(1)项DFA
-
改进:在构造分析表时考虑到了超前查看一项符号
-
存储结构:二维表
-
DFA图画法:
(0)\(A'\to A\)
(1)\(A\to (A)\)
(2)\(A\to a\)
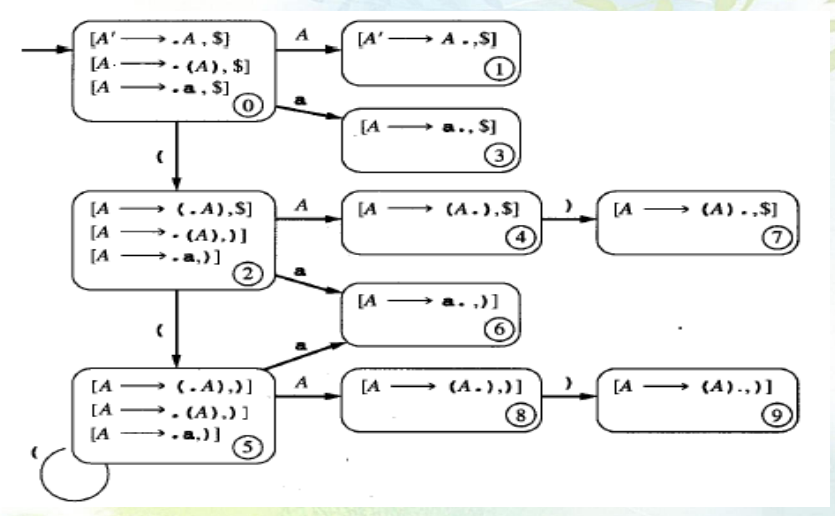
-
分析表:
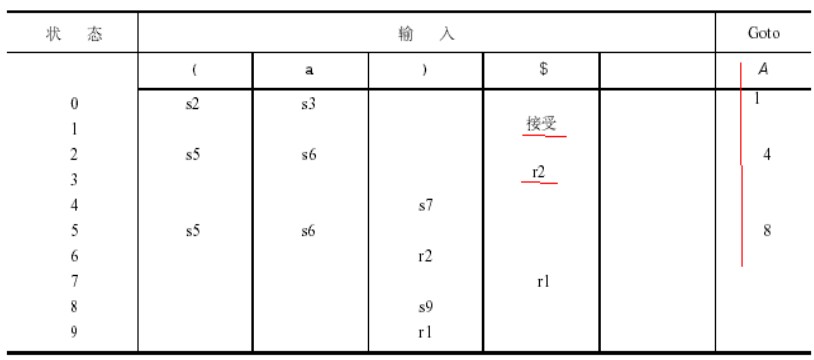
-
问题:
仍然存在归约-归约冲突,因此无归约-归约冲突的就满足LR(1)文法
-
-
SLR(1)项(相关练习:
./编译原理/讲稿/chap05/page=22):-
DFA相关:DFA图仍然使用LR(0)的DFA图,因此满足其文法也需要保证无“移进-归约”冲突,且无“归约-归约”冲突。(是LR(0)文法范畴)
不同于LR(0)的是,其仍然可以处理上述规则,只不过冲突可以在这里进行部分解决
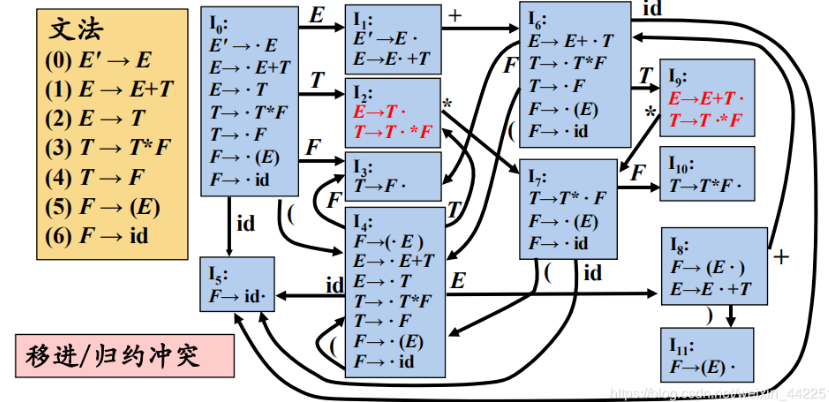
上图的l2与l9是存在“移进-归约冲突”的,而解决方法为:
- 求出E的Follow集合、T的First集合元素
- 若下一个输入符号为E的Follow集合,就归约为E
- 否则就采用T的产生式移进
实际上,我们使用Follow集合元素来解决这一问题,但是当其出现交集且下一输入符号属于此集合时,就无法解决冲突问题了,且此时也不属于SLR(1)文法了
- 绥靖方法:面对移进-归约冲突时(不属于SLR(1)文法时),只做移进不做归约
-
-
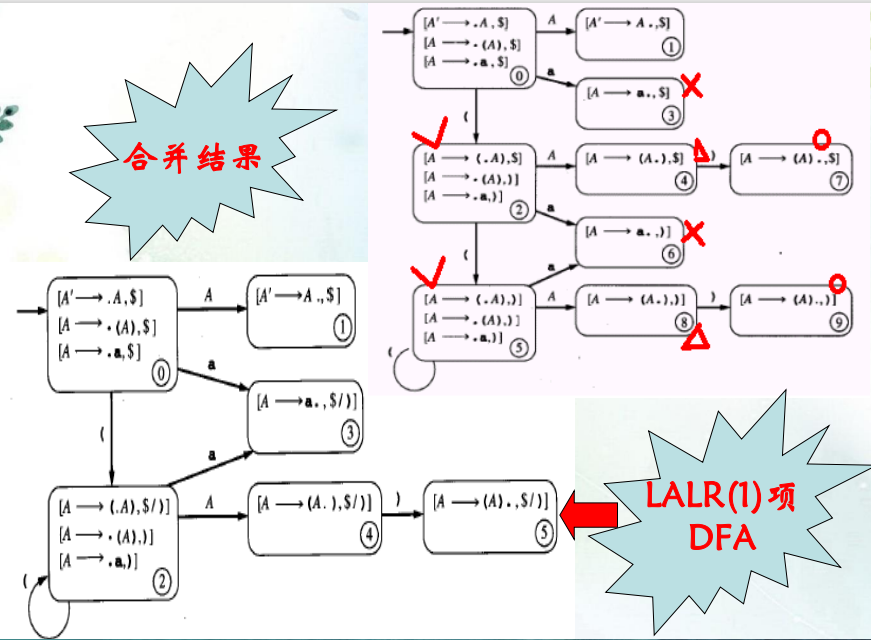
LALR(1)文法()
-
为了压缩LR(1)DFA的状态数,使用LALR(1)将核心相同的DFA进行合并
-
一个例子:
-
第六章
语法制导翻译方法
- 方法一:在确定的递归下降语法分析程序中,利用隐含堆栈存储各递归下降函数内的局部变量所表示的语义信息。
- 方法二:在自底向上语法分析程序中使用和语法分析栈同步操作的语义栈进行语法分析翻译。
- 方法三:在LL(1)语法分析程序中,利用翻译文法实施语法分析翻译
- 翻译文法是在描述语言的文法(即源文法或输入文法)中加入语义动作符号而形成的
- 方法四:利用属性文法进行语法分析翻译
- 属性文法也是一种翻译文法
- 其符号(文法符号和动作符号)都扩展为带有语义属性和同一规则内各属性间的运算规则
中间代码及表示形式
-
中间代码分类:
树、后缀表示、三元组、四元组、P代码
-
表现形式:
- 中缀表示
- 后缀表示——逆波兰表示
将一个算术表达式转换成逆波兰表示、三元组表示和四元组表示
-
基本方案:
-
递归下降分析法
- 写出算术运算的文法规则:
\[\begin{flalign} &\ G[E]:\\ &\ E\to T\space(+|-)\space T\\ &\ T\to F\space(*|/)\space F\\ &\ F\to (E)|n \end{flalign} \]-
使用EBNF改造文法:
\[\begin{flalign} &\ G[E]:\\ &\ E\to T\space\{(+|-)\space T\}\\ &\ T\to F\space\{(*|/)\space F\}\\ &\ F\to (E)|n \end{flalign} \] -
书写递归下降分析程序:
//E->T {(+|-) T} void E(){ T(); while(token=="+"||token=="-"){ match(token); T(); } } //T->F {(*|/) F} void T(){ F(); while(token=="*"||token=="/"){ match(token); F(); } } //F->(E)|n void F(){ if(token=="("){ E(); match(")"); } else if(isDigit(token)){ getNextToken(); } else error(); } -
根据要求进行语义动作的添加
//全局变量 stack<string> sta; sta.push("@"); //初始化 //E->T {(+|-) T} void E(){ T(); while(token=="+"||token=="-"){ string tmp=token; match(token); T(); sta.push(tmp); } } //T->F {(*|/) F} void T(){ F(); while(token=="*"||token=="/"){ string tmp=token; match(token); F(); sta.push(tmp); } } //F->(E)|n void F(){ if(token=="("){ match("("); E(); match(")"); } else if(isDigit(token)){ sta.push(token); getNextToken(); } else error(); }
-
采用自底向上分析方法(LR)
-
写出算术运算的文法
-
画出LR(0)DFA图——采用SLR(1)分析方法
-
构造规则的语义动作:
规则 语义函数 E'->E E->E+T sta.push(tmp);E->E-T sta.push(tmp);E->T T->T*F sta.push(tmp);T->T/F sta.push(tmp);T->F F->(E) F->n sta.push(token);
-
-
将一段代码翻译为中间代码(后缀表达式、三元组和四元组)
以if(m>n) k=1; else m=0;为例:
-
后缀表示:
-
if语句:if(u) S1 else S2u L1 BZ S1 L2 BR S2BZ为双目运算符,当u不成立(为0)时转向L1部分继续执行
L1表示语句S2开始执行的位置
BR为一个单目运算符,表示无条件转向L2部分继续执行
L2表示该语句下一个语句开始执行的位置
if(m>n) k=1; else m=0; //后缀表示 m n > 1 BZ k 1 = 2 BR 1:m 0 = 2: -
while循环语句:while(m>n) k=1; //后缀表示 1: 2:m n > 3 BZ k 1 = 1 BR 3:
-
-
四元组表示:(具体内容参见
./编译原理/讲稿/chap06/page=74~82)-
基本成分:
(OP,P1,P2,T) //OP为运算符,P1和P2为操作数,T为结果需要注意:
P1,P2,T均可以用于指向符号表某一等级入口位置或是临时变量的整数码 -
示例:
表达式
a*(b+c)对应为:(+,b,c,T1),(*,a,T1,T2) -
扩充表达:
-
赋值语句:
a=e -
关系比较语句:
//a>b: (-,a,b,T) (BMZ,?,,T) //或者 (J>,a,b,?) (J,,,?)
-
-
-
三元组表示:(具体内容参见
./编译原理/讲稿/chap06/page=83~87)-
基本成分:
(OP,P1,P2) //OP为运算符,P1、P2为运算对象 -
示例:
表达式
a*(b+c)对应为:(1) (+,b,c) (2) (*,a,(1))
-
几种常用语句的翻译——写出语义函数或语义动作
(具体内容参见./编译原理/讲稿/chap06/page=94~176)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号